
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- python
- WITH ROLLUP
- 마케팅 보다는 취준 강연 같다(?)
- 부트 스트래핑
- 그로스 해킹
- sql
- 스태킹 앙상블
- ImageDateGenerator
- DENSE_RANK()
- 로그 변환
- 데이터 증식
- 데이터 정합성
- 캐글 신용카드 사기 검출
- 데이터 핸들링
- 리프 중심 트리 분할
- 분석 패널
- pmdarima
- 그로스 마케팅
- Growth hacking
- ARIMA
- lightgbm
- XGBoost
- splitlines
- 인프런
- 3기가 마지막이라니..!
- tableau
- 컨브넷
- 그룹 연산
- 캐글 산탄데르 고객 만족 예측
- WITH CUBE
- Today
- Total
LITTLE BY LITTLE
Nelson Rules(1~4번) 파이썬으로 구현하기 본문
사전 작업) 중심선, 상한선, 하한선 설정
💡조건문 (if-elif-else)
💡통계적 공정 관리 (SPC, Statistical Process Control) 개념
- 일반적으로는 평균,표준편차+=3시그마를 각각 중앙선, 상한선, 하한선으로 설정하나, 고정된 값(중앙선과 관리 한계값)을 사용해야하는 경우 다르게 설정하고, 그렇지 않은 경우에는 평균과 표준편차를 활용하여 동적으로 계산
def calculate_limits(group):
type = group.name # 그룹의 이름을 가져옴
if type == 'A1':
central_line = 75
ucl = 80
lcl = 70
elif type == 'A2':
central_line = group['value'].mean()
std_dev = group['value'].std()
ucl = central_line + 3 * std_dev
lcl = central_line - 3 * std_dev
elif type == 'B1':
central_line = 142
ucl = 146
lcl = 138
elif type == 'B2':
central_line = 142
ucl = 146
lcl = 138
elif type == 'B3':
central_line = 25
ucl = 30
lcl = 20
elif type in ['C1', 'C2']:
central_line = group['value'].mean()
std_dev = group['value'].std()
ucl = central_line + 3 * std_dev
lcl = central_line - 3 * std_dev
else:
central_line = group['value'].mean()
std_dev = group['value'].std()
ucl = central_line + 3 * std_dev
lcl = central_line - 3 * std_dev
group['central_line'] = central_line
group['ucl'] = ucl
group['lcl'] = lcl
return group규칙 1번) 상/하한선 초과
: 상한선을 초과하거나, 하한선을 초과한 인덱스를 가진 행 반환

rule_1_indices = group[(group['value'] > ucl) | (group['value'] < lcl)].index
for timestamp in rule_1_indices:
rules.append((timestamp, timestamp, 1, 'Rule_1', tagname))
💡.index 속성
- group[(조건)].index → 조건을 만족하는 행들의 인덱스만 추출
💡append()
- rules 리스트에 새로운 튜플 (timestamp, timestamp, 1, 'Rule_1', tagname) 추가
💡for 반복문을 활용한 리스트 생성
- 관리 한계(UCL, LCL)를 초과하거나 미달하는 값의 인덱스만 가져옴 (=규칙 1번에 해당하는 경우의 값)
- 해당하는, rule_1_indices에 저장된 인덱스를 하나씩 가져와 rules.append() 결과df인 rules에 붙임
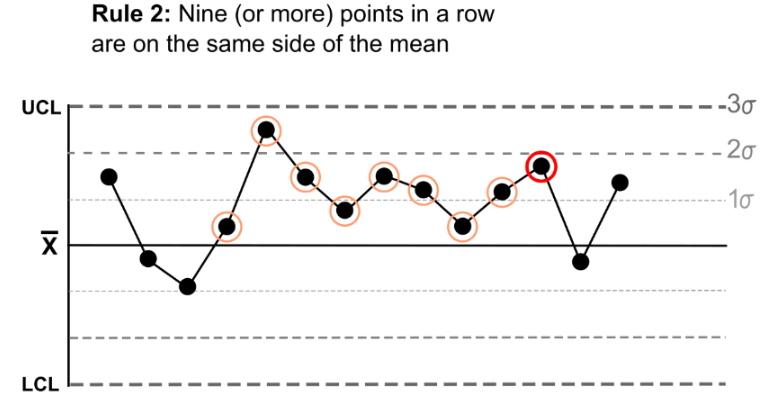
규칙 2번) 9개 연속 같은 쪽
: 연속적으로 관측된 9개 이상의 점이 중심선 위/아래 에만 존재할 경우.
즉, 9번 이상 평균과 상한선, 혹은 평균과 하한선 사이에 값이 존재하는 경우
*2번 부터는 슬라이딩 윈도우 적용
### 1)
def check_same_side(window, central_line):
above = window > central_line
below = window < central_line
return np.all(above) or np.all(below)
### 2)
for i in range(len(group) - 8):
window = group['value'].iloc[i:i+9]
if check_same_side(window, central_line):
if start_index is None:
start_index = i
end_index = i + 8
else:
### 3)
if start_index is not None and end_index is not None:
rules.append((group.index[start_index], group.index[end_index], end_index - start_index + 1, 'Rule_2', tagname))
start_index = None
end_index = None💡슬라이딩 윈도우
- 데이터를 작은 구간으로 나누고, 그 구간을 한 칸씩 이동하면서 반복적으로 검사하는 방식
- 목적: 데이터를 구간별로 나누어 특정 패턴을 확인
- 예를 들어 윈도우 크기를 3으로 설정한다면, 3초씩 구간이 나뉘고 + 3초 간의 연속된 데이터가 조건을 만족하는지 검사
💡numpy 배열 및 boolean 연산
- np.all(above) : 모든 값이 중앙선 위에 있음 → 모두 True → True 반환
💡 슬라이싱 / iloc - 슬라이딩 윈도우 가져오기
- range(len(group) - 8) : 9개씩 데이터를 가져옴
- iloc[i:i+9] i부터 i+8까지 9개의 데이터를 추출하여 window 변수에 저장 (*iloc[start:end]에서 end값은 포함되지 않음)
💡 for 반복문을 활용한 윈도우 이동
- for i in range(len(group) - 8): 한 루프 당 9개씩 묶어서 비교
- check_same_side(window, central_line)로 window(9개의 데이터)가 모두 중앙선 위 또는 아래에 위치하는지 검사
💡 연속된 인덱스 찾기 (start_index, end_index)
- 연속된 패턴이 처음 발견되면 start_index에 저장
- 연속된 패턴이 유지되면 end_index를 갱신하여 end_index 업데이트
- check_same_side()가 False가 되면 패턴이 종료
- 패턴 종료 시, 결과 리스트에 추가
- 이후 start_index = None, end_index = None으로 리셋
규칙 3번) 추세 - 9개 연속 증가/감소
: 여섯 개 이상의 점이 연속적으로 증가하거나 감소하는 경우 (=추세 존재)
*시계열 데이터에서도 추세가 존재하면 추세를 제거하고 모델링을 진행해야 하듯이, 여기에서도 추세가 존재하면 불량 패턴으로 의심해볼 수 있음

### 1)
def check_increasing_or_decreasing(window):
increasing = np.all(np.diff(window) > 0)
decreasing = np.all(np.diff(window) < 0)
return increasing or decreasing
### 2)
for i in range(len(group) - 5):
window = group['value'].iloc[i:i+6]
if check_increasing_or_decreasing(window):
if start_index is None:
start_index = i
end_index = i + 5
else:
### 3)
if start_index is not None and end_index is not None:
rules.append((group.index[start_index], group.index[end_index], end_index - start_index + 1, 'Rule_3', tagname))
start_index = None
end_index = None💡np.diff()를 활용한 증가/감소 판별
- np.diff()로 연속된 요소의 차이(증가/감소) 계산
- np.diff(window)를 사용해 연속된 값들의 차이를 계산
- 증가 = 차이가 모두 양수 / 감소 = 차이가 모두 음수
💡 슬라이딩 윈도우를 활용한 증가/감소 탐지
- for 루프를 이용해 데이터에서 9개씩 묶어서 검사
💡 연속된 증가/감소 구간 찾기
- 처음 감지되었을 때 (start_index is None인 경우) start_index = i 설정
- 패턴이 계속 유지되는 동안 end_index를 업데이트하여 가장 끝의 인덱스 저장
- 패턴이 더 이상 유지되지 않는 경우(else 실행)
규칙 4번) 교대 패턴 - 14개가 교대로 변동
: 연속적으로 관측된 14개 이상의 점이 번갈아가며 나타나는 경우

### 1)
def check_alternating(window):
diffs = np.diff(window)
signs = np.sign(diffs)
alternating = np.all(signs[1:] != signs[:-1])
return alternating
### 2)
for i in range(len(group) - 13):
window = group['value'].iloc[i:i+14]
if check_alternating(window):
if start_index is None:
start_index = i
end_index = i + 13
else:
### 3)
if start_index is not None and end_index is not None:
rules.append((group.index[start_index], group.index[end_index], end_index - start_index + 1, 'Rule_4', tagname))
start_index = None
end_index = None💡 np.diff()와 np.sign()을 활용한 증가/감소 방향 판별
- np.diff로 연속된 차이를 계산하고, np.sign으로 차이값의 부호(+1,-1,0)을 반환해서, 부호가 교대로 변동하는지 확인
- np.sign() 양수(1), 음수(-1), 0(0) 로 변환하는 함수 활용 - 값이 증가하면 1, 감소하면 -1
- signs[1:] : 2번째 값부터 끝(14번째)까지 가져옴 = 현재 부호를 나타냄
- signs[:-1] : 1번째 값부터 마지막 이전(13번째)까지 가져옴 = 이전 부호를 나타냄
- np.all(signs[1:] != signs[:-1]) : 모든 연속된 두 값의 부호가 교대하는지 검사, 모두 다른 경우 true로만 구성된 배열 반환
💡 슬라이딩 윈도우를 활용한 교대 패턴 탐지
- for 루프를 이용해 데이터에서 14개씩 묶어서 검사
💡 연속된 교대 패턴 구간 찾기
- 처음 감지되었을 때(start_index is None인 경우) start_index = i 설정
- 패턴이 계속 유지되는 동안 end_index를 업데이트하여 가장 끝의 인덱스를 저장
✅ 추가적으로 고려해볼 항목
- 예외 처리: 위의 함수는 비어 있는 데이터나, 중앙선과 정확히 일치하는 값에 대해 어떻게 동작할지 명확하지 않음
- 데이터에 NaN이 포함된 경우 어떻게 처리할까?
- check_same_side() 함수에서 같은 값(central_line과 정확히 같은 값)이 포함된 경우는 어떻게 처리할까?
- 최적화 및 성능 개선
- for 문을 사용한 슬라이딩 윈도우는 반복문을 직접 수행하기 때문에 속도가 느릴 수 있음
- 벡터 연산을 활용하여 Pandas의 .rolling() 메서드를 사용하면 훨씬 빠르게 연산할 수 있을 것
'기타' 카테고리의 다른 글
| [2] 검색광고 마케터 1급 자격증 대비 (0) | 2023.03.21 |
|---|---|
| [1] 검색광고 마케터 1급 자격증 대비 (0) | 2023.03.16 |
| GAIQ(구글 애널리틱스 Individual Qualification) 취득 (0) | 2023.01.21 |

