
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- pmdarima
- 그로스 마케팅
- DENSE_RANK()
- lightgbm
- tableau
- 인프런
- 마케팅 보다는 취준 강연 같다(?)
- 그룹 연산
- 캐글 산탄데르 고객 만족 예측
- 컨브넷
- 데이터 정합성
- ImageDateGenerator
- 분석 패널
- XGBoost
- 리프 중심 트리 분할
- WITH CUBE
- 데이터 핸들링
- 데이터 증식
- WITH ROLLUP
- 3기가 마지막이라니..!
- Growth hacking
- 스태킹 앙상블
- splitlines
- 부트 스트래핑
- 캐글 신용카드 사기 검출
- 로그 변환
- 그로스 해킹
- sql
- ARIMA
- python
- Today
- Total
LITTLE BY LITTLE
[11] 실무로 통하는 인과추론 with 파이썬 - 11장. 불응과 도구변수 본문

목차
Part 5. 대안적 실험 설계
<11장. 불응과 도구변수>
11.1 불응
11.2 잠재적 결과 확장
11.3 도구변수 식별 가정
11.4 1단계
11.5 2단계
11.6 2단계 최소제곱법
11.7 표준오차
11.8 통제변수와 도구변수 추가
11.8.1 2SLS 직접 구현
11.8.2 행렬 구현
11.9 불연속 설계
11.9.1 불연속 설계 가정
11.9.2 처치 의도 효과
11.9.3 도구변수 추정값
11.9.4 밀도 불연속 테스트
11.10 요약
11장. 불응과 도구변수
- 서비스의 영향을 추론하기 어려운 이유는, 서비스를 고객이 '선택'하는 경우가 많기 때문이다.
- 참여 여부는 고객의 선택에 달려있음
- 제공 여부를 무작위로 결정하더라도, 고객에게 이를 받아들이도록 강요할 수는 없다.
- 이를 '불응'이라 하며, 처치를 배정받은 모든 사람이 처치 받지는 않음을 의미
불응 문제가 있는 실험을 설계할 때 어떤 점을 고려해야할까?
11.1 불응
처치 배정과 처치 적용
- 순응자(complier): 자신에게 배정된 처치를 받는 사람
- 항시 참여자(always-taker): 배정과 관계없이 항상 처치 받는 사람
- 항시 불참자(never-taker): 배정과 관계없이 처치를 한 번도 받지 않은 사람
- 반항자(defier): 배정된 처치와 반대되는 처치 받는 사람
여기서 문제는 각 그룹에 누가 속해 있는지 모른다는 점
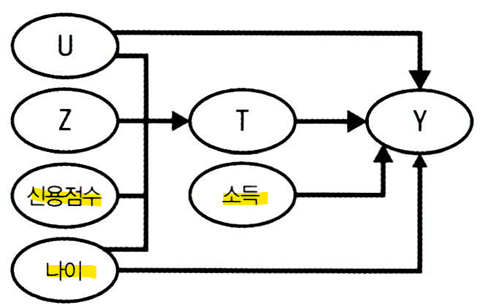
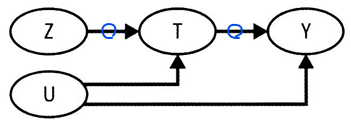
불응을 DAG 형태로 나타내보면,
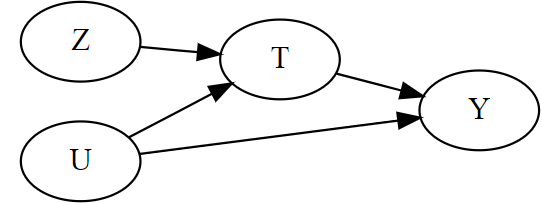
- Z가 무작위 처치배정일 때, 숨겨진 요인(U)이 처치(T)에 영향을 준다.
- Z는 도구변수(IV)의 역할을 하여,
- 교란 없이 처치(T)에 영향을 주고,
- 처치(T)를 거치지 않으면 결과(Y)에 영향을 미치지 않음
- U를 순응 그룹을 유발하는 미지의 요인으로 생각할 수도 있음
- U를 통과하는 열린 뒷문 경로때문에 T가 Y에 미치는 영향을 식별할 수 없음
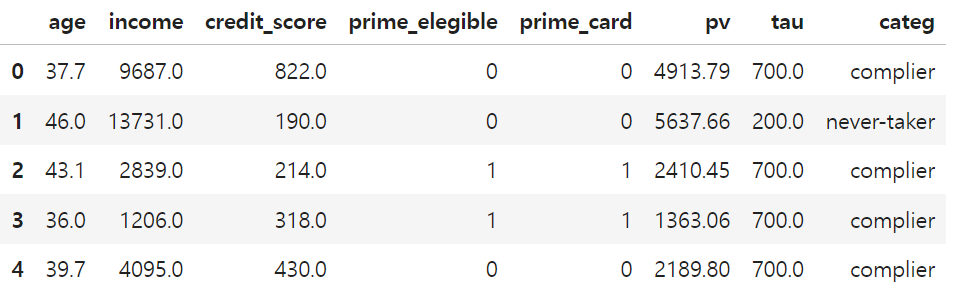
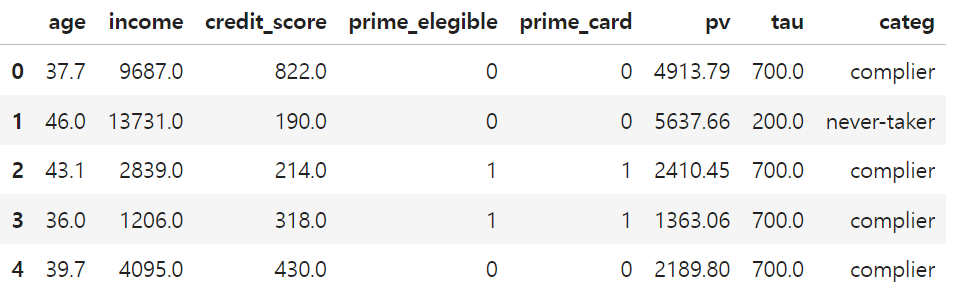
10,000명의 고객을 대상으로 프라임 신용카드 이용 가능 여부를 무작위로 배정하는 실험 데이터

- 구매금액 = pv (Y)
- 프라임 신용카드 보유 여부 = prime_card(T)
- 프라임 신용카드 사용 가능여부 = prime_elegible(Z)
11.2 잠재적 결과 확장
잠재적 처치(potential treatment) Tz
: Z가 T의 원인일 때, 잠재적 결과는 도구변수 Z에 대한 새로운 반사실 Yz,t를 가짐
처치의도효과(ITTE, Intent-To-Treatment Effect)
: 도구변수 Z가 결과 Y에 미치는 영향으로, 여기에서는 프라임 신용카드 사용 가능 여부가 구매 금액에 미치는 영향
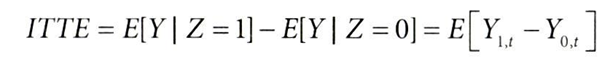
처치의도효과(ITTE)를 단순회귀로 추정해보자
m = smf.ols("pv~prime_elegible", data=df).fit()
m.summary().tables[1]
- ITTE는 프라임 신용카드의 구매 금액에 대한 제공 영향이자,
- 은행에서 프라임 신용카드를 사용함으로써 기대할 수 있는 고객당 추가 구매금액(PV)를 나타냄( ≠ 처치효과)
- 은행의 주요 목표는, "프라임 카드의 혜택이 그 비용을 상회하는가?" = 처치효과가 필요
- 이 사례에서는 프라임 카드를 사용 가능한 (Z)사람만이 보유 여부(T)를 선택할 수 있도록 통제되어있다.
- 이를 단방향 불응(one-sided non-compliance)이라 한다.
- 따라서 순응그룹이 4개가 아닌, 항시 참여자(always-taker) = 순응자(complier),
- 반항자(defier) = 항시 불참자(never-taker) 총 2가지로 분류
ITTE를 프라임 카드 효과의 대리변수로 사용할 수 있을까?
- 바로 사용할 수 없다. ITTE 추정값은 ATE 추정값보다 0에 가깝게 편향될 수 있다.
- 실험군인데에도 일부가 처치를 받지 않을 수 있기에 실험-대조군 간의 차이가 줄어들기 때문
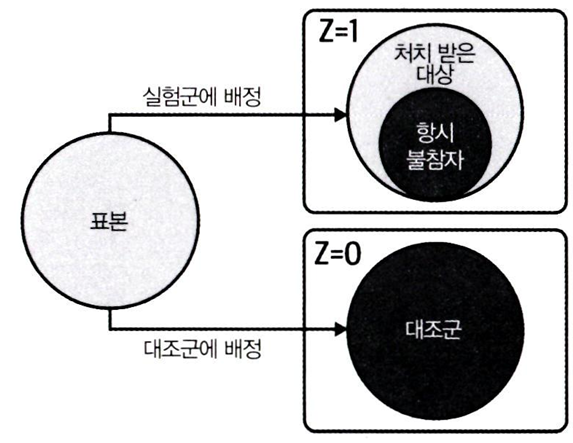
반대로 실험군-대조군 간의 단순평균 비교를 하면, 관심있는 효과 추정값을 대체해서 사용할 수 있는지 확인
m = smf.ols("pv~prime_card", data=df).fit()
m.summary().tables[1]
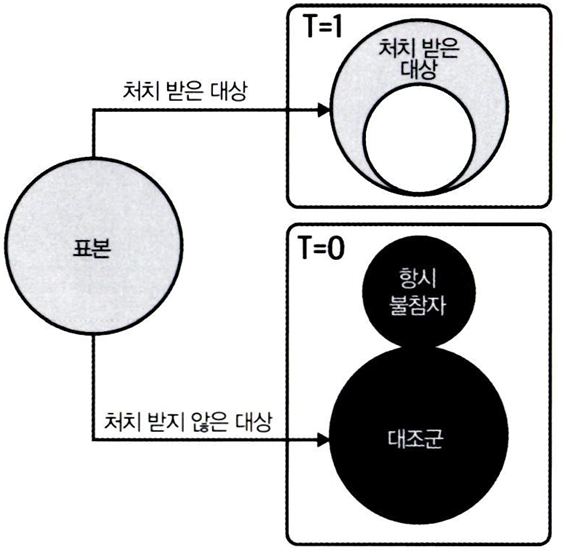
이 경우에는 항시 불참자(eligible 하지만 보유 X)가 빠져있고 대조군에 있어서, 대조군 Y0가 더 낮아져 효과에 상향편향이 존재한다.
불응 상태에서는 처치 선택이 무작위가 아니므로,
- ATE를 식별할 수 없고,
- ITTE는 ATE에 대한 편향 추정값이 어려운 상황
11.3 도구변수 식별 가정

도구변수 식별 가정에 필요한 가정을 정리해보면,
- 독립성
- 도구변수(Z)와 처치(T)는 독립
- 도구변수(Z)와 결과(Y)는 독립
- 배제 제약: 처치(T)를 통하지 않고는, 도구변수(Z)에서 결과(Y)로 가는 경로가 없어야 함
- 연관성: 도구변수(Z)가 처치(T)가 영향을 미쳐야 함
- 단조성: 도구변수(Z)가 처치(T)를 한 방향으로만 영향 주는 것
- 처치 받을 확률이 증가하는 경우, 반항자가 없다고 가정
- 처치 받을 확률이 감소하는 경우, 순응자가 없다고 가정
ITTE를 시작점으로 삼고, 위의 가정을 만족하는 ITTE를 ATE로 정의
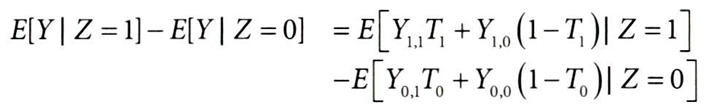
배제 제약 → Yz,t의 도구변수 첨자 제거
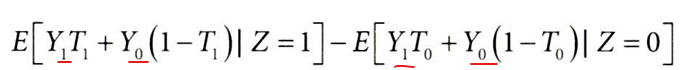
독립성 가정 → 두 기댓값 묶기
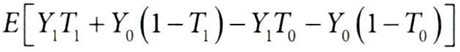
식을 단순화하면,
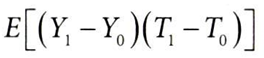
단조성 가정을 사용하여, 가능한 경우인 T1>T0과 T1=T0으로 확장
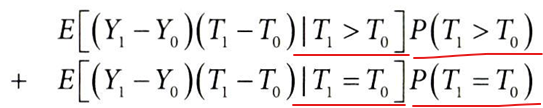
T1=T0일 때에는 T1-T0이 0이 되므로 첫 번째 항만 남음
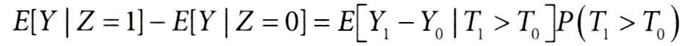
- T1>T0은 순응자 (자신에게 배정된 처치를 받는 사람)
- 카드를 사용 가능 여부가 미소유 → 소유 로 전환하는 집단
- 즉, 카드를 사용 가능하면, 무조건 카드를 보유하는 집단
- 즉, 도구변수(Z)가 결과(Y)에 미치는 영향(가정을 만족한 ITTE) = 순응자의 처치효과(E(Y1-Y0|T1>T0])에 순응률(P(T1>T0))을 곱한 값
→ P(T1>T0)만 추정할 수 있으면, 이전 추정량을 보정할 수 있음
※ 순응률: 도구변수(Z)가 처치(T)에 미치는 영향
순응률을 구하기 위해 단조성 가정을 활용해보면, 순응자이면 T1-T0=1이고, 그렇지 않으면 0이기에 이 효과의 기댓값은 순응률이다.
- T1-T0=1 : 순응자는, 카드를 사용 가능하지 않을 때(T0) 카드를 보유하는 사람(T1) = 0 이니까..?
→ E[T1-T0] = P(T1>T0)
→ 도구변수(Z)가 결과(Y)에 미치는 영향을, 도구변수(Z)가 처치(T)에 미치는 영향인 "순응률"로 조정함으로써, 순응자들에 대한 평균 처치효과를 식별할 수 있음
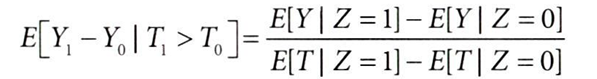
(순응률이 0~1 사이이므로 ATE * 순응률 = ITTE가 하향편향되어 나왔던 것)
하지만 여전히 ITTE * 순응률도 ATE라 할 수 없고, LATE(Local Average Treatment Effect, 국지적 평균 처치효과)만 구할 수 있게 된다.
- LATE는 프라임 카드를 사용가능할 때(Z), 보유(T)한 사람들의 효과
- 추가로 더 알고 싶은 건, 고객당 추가 구매금액(Y)의 효과가 프라임 카드의 비용을 상회하는지 여부
- 위 값은 모두 프라임 카드를 선택한 사람들에게만 발생하기에, ATE가 아닌 LATE만 구해도 충분하다. (은행은 카드를 선택하지 않을 사람들의 효과에는 신경 쓰지 X)
11.4 1단계
도구변수 분석의 첫 단계를 1단계 회귀라 부른다.
1단계 회귀
: 처치(T)를 도구변수(Z)에 회귀하는 단계로, 연관성 가정(Z가 T에 영향을 미쳐야함)을 확인하는 과정
first_stage = smf.ols("prime_card ~ prime_elegible", data=df).fit()
first_stage.summary().tables[1]
순응률은 약 42%로 추정되며, 유의하다.
이 예제에서는 실제 순응률을 알고 있기에 확인해보면, 실제 순응률과 일치함
df.groupby("categ").size()/len(df)
> categ
complier 0.4269
never-taker 0.5731
dtype: float6411.5 2단계
2단계(축약형)
: 결과(Y)를 도구변수(Z)에 회귀하여 처치의도효과(ITTE)를 추정
red_form = smf.ols("pv ~ prime_elegible", data=df).fit()
red_form.summary().tables[1]
1단계 회귀의 매개변수 추정값으로 나누면 LATE에 대한 추정값을 얻을 수 있다.
late = (red_form.params["prime_elegible"] /
first_stage.params["prime_elegible"])
late
> 757.6973795343938
이 예제에서는 실제 순응자에 대한 효과를 계산할 수 있기에 구한 LATE 추정값이 실제값에 근접한지 확인
df.groupby("categ")["tau"].mean()
> categ
complier 700.0
never-taker 200.0
Name: tau, dtype: float64- 완전히 일치하지는 않는다.
- 도구변수 추정값의 표준오차를 계산할 수 있는, LATE를 추정하는 다른 방법인 2단계 최소제곱법을 살펴보자
11.6 2단계 최소제곱법
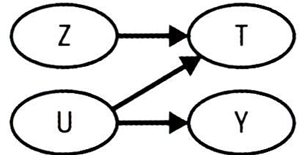
처치(T)의 원인은 두 가지 변수이다.
- 랜덤화된 도구변수(Z)
- 교란편향이 발생하는 U변수
- 앞서 살펴본 1단계 회귀(T~Z) 단계는 본질적으로 경로 Z→T를 추정하는 것을 의미함
- 1단계에서의 예측값인 T햇을 편향이 제거된 T로 볼 수 있다.
- 그리고 2단계 축약형(Y~Z) 단계는 Y를 편향이 제거된 T에 회귀하여 이전과 같은 도구변수 추정값을 얻게 됨
코드로 확인해보면,
iv_regr = smf.ols(
"pv ~ prime_card",
data=df.assign(prime_card=first_stage.fittedvalues)).fit()
iv_regr.summary().tables[1]
- 위 접근법을 2단계 최소제곱법(two-stage least square, 2SLS)라 한다.
- 위 접근법이 더 유용한 이유는,
- 표준오차를 적절하게 계산할 수 있고,
- 회귀 모델에서 변수를 추가할 때만큼 쉽게 도구변수(Z),공변량을 더 추가할 수 있기 때문
두 가지 이유에 대해 더 살펴보자.
11.7 표준오차
2단계 축약형(Y~Z) 단계 예측의 잔차는 다음과 같이 정의된다.
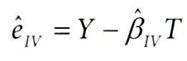
여기에서 T는 예측된 T햇이 아니라, 기존의 처치를 사용
위의 잔차로 도구변수(Z) 추정값에 대한 표준오차를 계산하면,
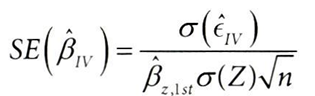
βz,lst 는 1단계 회귀 단계에서 얻은 예상 순응률을 의미
Z = df["prime_elegible"]
T = df["prime_card"]
n = len(df)
잔차(e_iv) 구하기 (표준오차의 분자)
# iv_regr.resid 와 다름에 유의 (T햇이 아닌 T를 사용)
e_iv = df["pv"] - iv_regr.predict(df)
순응률 구하기
compliance = np.cov(T, Z)[0, 1]/Z.var()
표준오차(se) 구하기
se = np.std(e_iv)/(compliance*np.std(Z)*np.sqrt(n))print("SE IV:", se)
print("95% CI:", [late - 2*se, late + 2*se])
> SE IV: 80.52861026141942
95% CI: [596.6401590115549, 918.7546000572327]
패키지(IV2SLS)를 이용해서 LATE 추정값과 표준오차 구하기
from linearmodels import IV2SLS
# 1단계 회귀(T~Z)를 공식 안에 넣고
formula = 'pv ~ 1 + [prime_card ~ prime_elegible]'
# 도구변수 모델 적합
iv_model = IV2SLS.from_formula(formula, df).fit(cov_type="unadjusted")
iv_model.summary.tables[1]
표준오차 공식을 다시 보면,
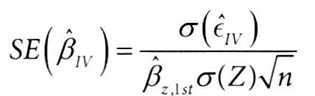
분모에 순응률 βz,lst이라는 추가 항이 생겨서
- 만약 순응률이 100%인 경우, Z=T, βz,lst=1이 되고 OLS 표준오차를 다시 얻게될 것이고,
- 순응률이 50%라면, 분모에있는 βz,lst=0.5가 되어 도구변수 표준오차는 OLS때보다 2배 커짐
- 따라서 순응률이 50%인 실험에 필요한 표본 크기는 순응률이 100%인 경우의 4배가 된다.
예상 순응률을 가정하여 LATE 매개변수 추정값에 대한 신뢰구간 크기를 비교해보면,

순응률이 커질 수록 신뢰구간은 좁아지고, 필요한 표본의 수는 줄어든다.
→ 실제 사례에서는 카드를 선택하는(Z) 고객이 일부이기에, 순응률이 50%만큼 높기 쉽지 않아 LATE를 추정하기 어려움
→ 순응률이 낮으면 큰 표본이 필요하기 때문에 큰 표본을 수집하는 것도 비현실적이다.
위와 같은 문제가 있을 때, 도구변수 표준오차를 낮출 수 있는 방법이 있다.
11.8 통제변수와 도구변수 추가
프라임 신용카드 데이터에 세 가지 공변량(소득, 나이, 신용점수)이 있었다.
- 소득: 결과(Y) 예측력이 높지만, 순응 여부(Z→T) 는 예측하지 못함
- 신용점수: 순응 여부(Z→T)는 예측하지만, 결과(Y)는 예측하지 못함
- 나이: 순응 여부(Z→T) 와 결과(Y)에 모두 영향을 미치는 교란 요인
→ 여기서 신용점수는 도구변수(Z)처럼 3가지 가정을 만족하며, 추가적으로 단조성만 가정하면 추가 도구변수로 취급할 수 있다.
formula = 'pv ~ 1 + [prime_card ~ prime_elegible + credit_score]'
iv_model = IV2SLS.from_formula(formula, df).fit()
iv_model.summary.tables[1]
두 가지 문제가 생긴다.
- 신용점수를 도구변수로 취급하는 대신, 조건부로 두고 2번째(축약형, Y~Z) 단계에도 추가하면, 오차가 증가한다.
- 결과(Y)가 아닌, 처치(T)의 원인을 조건으로 두면 추정값의 분산이 증가한다.(4장)
- 도구변수(Z) 배정 메커니즘을 알지 못하면, 배제 제약이 위배되는지 알기 어려움
- 배제 제약: 처치(T)를 통하지 않고는, 도구변수(Z)에서 결과(Y)로 가는 경로가 없어야 함
- 이 예제에서는 신용점수가 Y에 미치지 않는다고 가정했지만, 현실에서는 찾기 어려움(나이 처럼 Y와 순응 모두에 영향 주는 경우가 多)
결과(Y, 구매 금액)를 잘 예측할 통제변수(고객 소득, 나이)를 포함해서 도구변수 추정값의 분산을 줄여보자.
formula = '''pv ~ 1
+ [prime_card ~ prime_elegible + credit_score]
+ income + age'''
iv_model = IV2SLS.from_formula(formula, df).fit(cov_type="unadjusted")
iv_model.summary.tables[1]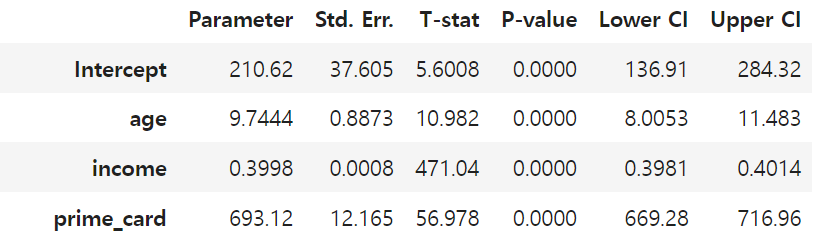
→ 하지만, 나이는 순응과 결과 모두에 영향을 미쳐 순응에 더 큰 영향을 미친다면(처치에 대한 설명력이 더 높다면) 분산이 커질 수 있다.
11.8.1 2SLS 직접 구현
- 1단계: T ~ Z + X
- 2단계: Y ~ T_hat + X
formula_1st = "prime_card ~ prime_elegible + credit_score + income+age"
first_stage = smf.ols(formula_1st, data=df).fit()
iv_model = smf.ols(
"pv ~ prime_card + income + age",
data=df.assign(prime_card=first_stage.fittedvalues)).fit()11.8.2 행렬 구현
위와 같이 구하면 linearmodels 사용했을 때와 표준오차가 달라지는데, 이는 표준오차 행렬로 구할 수 있음
Z = df[["prime_elegible", "credit_score", "income", "age"]].values
X = df[["prime_card", "income", "age"]].values
Y = df[["pv"]].values
처치 행렬과 도구변수 행렬 모두에 추가 공변량을 두어야 한다.
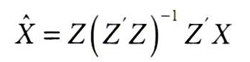
def add_intercept(x):
return np.concatenate([np.ones((x.shape[0], 1)), x], axis=1)
Z_ = add_intercept(Z)
X_ = add_intercept(X)# Z_.dot(...) 는 사전에 곱해야 함
# NxN matrix 생성
X_hat = Z_.dot(np.linalg.inv(Z_.T.dot(Z_)).dot(Z_.T).dot(X_))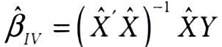
b_iv = np.linalg.inv(X_hat.T.dot(X_hat)).dot(X_hat.T).dot(Y)
b_iv[1]
> array([693.12072518])
얻게 된 계수(b_iv)로 도구변수의 잔차와 분산 계산
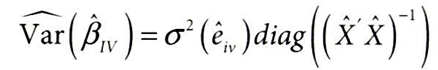
e_hat_iv = (Y - X_.dot(b_iv))
var = e_hat_iv.var()*np.diag(np.linalg.inv(X_hat.T.dot(X_hat)))
np.sqrt(var[1])
> 12.164694395033125
추가 공변량 없이 이전과 유사한 표준오차 값을 구할 수 있다.
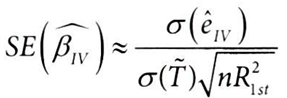
t_tilde = smf.ols("prime_card ~ income + age", data=df).fit().resid
e_hat_iv.std()/(t_tilde.std()*np.sqrt(n*first_stage.rsquared))
> 12.156252763192523
위 표준오차 공식을 통해 표본 크기를 늘리는 방법 이외에 표준오차를 줄이는 방법을 3가지 알 수 있다.
- 1단계의 R^2 증가시키기 - 순응을 잘 예측하는 강력한 도구변수 찾기
- T에 대한 예측력이 높은 변수를 제거하기
- Y에 대한 예측력이 높은 변수를 찾아서 2단계 잔차 줄이기 (가장 현실적)
11.9 불연속 설계
회귀 불연속 설계(RDD, Regression Discontinuity Design)
: 처치배정에 인위적인 불연속성을 활용하여 처치효과를 식별하는 방법
적용 사례
- 소득이 $50 미만인 빈곤층 가정만 혜택을 받을 수 있는 상황
- $50에서 프로그램 배정에 불연속성을 만듦
- 두 그룹이 유사하다는 전제하에, 연구자가 임곗값 바로 위/아래에 있는 가정을 비교하여 프로그램의 효과를 측정할 수 있게 함
- 대학 입시의 영향을 구하고자할 때: 합격 기준선 바로 위/아래에서 점수를 받은 학생들을 비교
- 여성이 정치에 미치는 영향을 평가할 때: 여성 후보가 소수점 차이로 패배한 도시와 승리한 도시를 비교
※ 학계에서는 널리 사용되지만, 실전에서 적용이 제한적이다.
임곗값을 하나의 '도구변수'로 이해
- 은행이 모든 고객에게 신용카드를 제공하되, 잔고가 $5000 이하인 고객에게 수수료를 부과한다면,
- 카드 제공 방식에 불연속성이 만들어져 잔액이 임곗값 이상인 고객은 프라임 카드를 선택할 가능성이 높고, 이하인 고객은 낮음
- 따라서 임곗값을 초과하는 고객과 그렇지 않은 고객의 특성이 비슷하다면, 회귀 불연속 설계를 활용할 수 있음
✅ 회귀 불연속 설계와 도구변수의 관계
불연속 설계에서의 도구변수
- Z = 계좌 잔고(임곗값, $5,000)
- 처치(프라임 카드)를 받을 확률을 높임 - 임곗값을 넘으면 P(T=1)이 급증함
1. 불연속 설계에서 잠재적 결과 Y
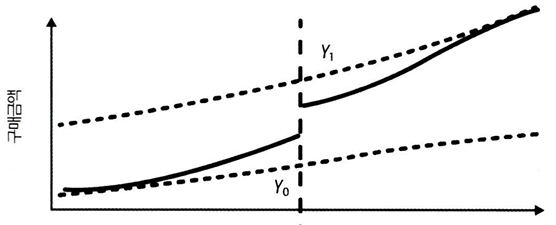
- 도구변수(계좌 잔고)로 인한 처치(T) 확률의 변화가 결과(Y)에 미치는 영향을 보여줌
- 임곗값 바로 위/아래가 불연속 - 잔고 $5,000 기준으로 결과(Y)에 차이가 난다.
2. 불연속 설계에서 잠재적 처치 T
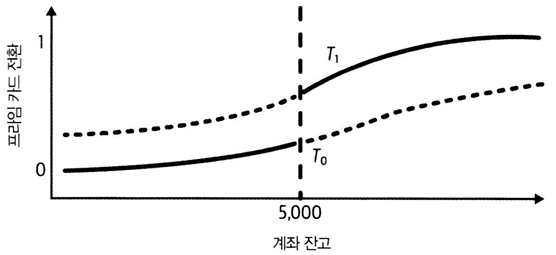
- 계좌 잔고(도구변수)에 따른 반사실 처치를 보여줌
- 도구변수는 $5,000을 임곗값으로 잔고가 $5,000 미만일 때 T0 (임곗값 아래일 때 , 그렇지 않으면 T1을 관측할 수 있음
❗임곗값에서의 처치효과는 실제보다 작게 보인다.
- 임곗값을 초과하더라도 처치 확률이 1보다 작으면 관측한 결과(Y)가 실제 잠재적 결과 Y1보다 작아짐
- 임곗값 아래에서 관측한 결과는 실제 잠재적 결과 Y0보다 높음
- → 도구변수를 사용해서 이를 보정해야 한다.
11.9.1 불연속 설계 가정
도구 변수 가정 이외에 추가 가정이 필요
: 잠재적 결과 및 잠재적 처치 함수의 평활도에 대한 추가 가정
1. 처치 확률이 임곗값 R=c에서 불연속 함수가 되도록 배정 변수 R(running variable)을 정의하고자 함
- R: 계좌 잔고
- c: 5,000
❗불연속 지점인 R=c에서 잠재적 결과 Yt와 잠재적 처치 Tz는 왼쪽에서 접근하든(r→c-) 오른쪽에서 접근하든(r→c+) 동일
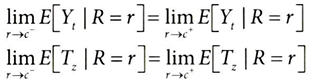
위 가정을 바탕으로 회귀 불연속 설계에 대한 LATE 추정량을 유도하면,
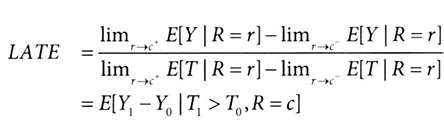
위 추정량은 두 가지 의미에서 국소적
- 임곗값 R=c에서만 처치효과를 줌
- 순응자의 처치효과만 추정함
11.9.2 처치 의도 효과
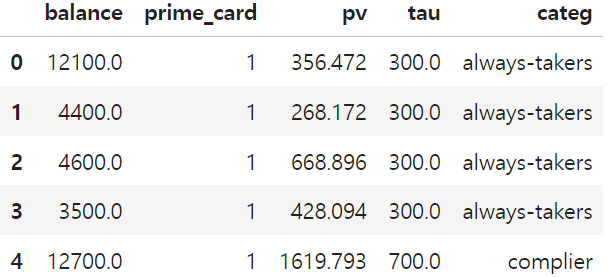
배정 변수(R)인 balance(잔고)가 추가된 프라임 카드 데이터
- 배정 변수인 잔고를 중심으로 조정하여 임곗값을 0으로 옮겨주기 (+해석도 더 쉬워짐)
- 불연속 지점($5,000)을 배정변수에서 빼줌
- 임곗값 위에 있는지 여부를 나타내는 더미변수 l(ri>0) 와, 상호작용하는 중심이 조정된 배정변수 R을 사용하여 결과변수에 대한 회귀분석을 진행(R>0)
- l(ri>0) = 1 : ri가 0보다 클 때
- l(ri>0) = 0 : ri가 0보다 작거나 같 때
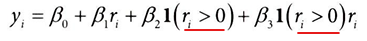
- : r가 0보다 클 때 추가적으로 영향을 미치는 상수적인 요소
- β3: 가 0보다 클 때 와 상호작용하여 종속 변수 에 미치는 추가적인 영향
- 임곗값 전후 기울기가 동일해서, 불연속 점프만을 포착하고자 한다면, 필요하지 않은 부분 ?
→ 여기에서 임곗값을 초과하는 것과 관련된 매개변수 추정값인 β2을 처치 의도 효과로 해석할 수 있음
① 값을 5,000만큼 뺀 balance 값을 생성하고, ② balance가 0보다 큰지 여부를 나타내는 더미 변수와, ③ 더미 변수와의 상호작용 항을 포함한 회귀 모델 정의하기
m = smf.ols(f"pv~balance*I(balance>0)",
df_dd.assign(balance = lambda d: d["balance"] - 5000)).fit()
m.summary().tables[1]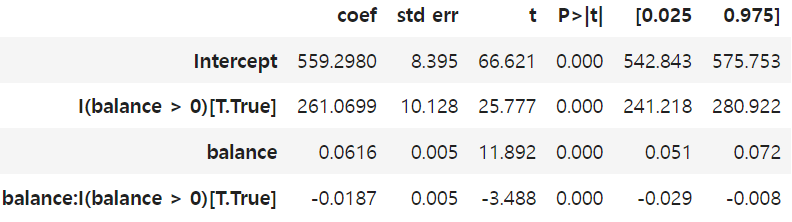
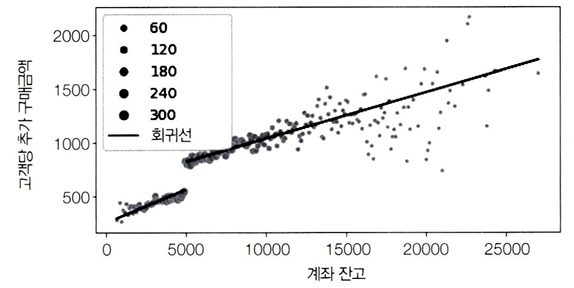
→ 위 식은 임곗값 위아래 두 개의 회귀선을 추정함
→ 여기에서 순응률이 100%라면, ITTE는 ATE가 된다. (앞서 증명함)
11.9.3 도구변수 추정값
하지만 순응률이 100%가 아니기 때문에, ITTE를 순응률로 나누어야 ATE를 구할 수 있다.
불연속 설계에서의 순응률
: 임곗값을 넘을 때 처치(T) 확률이 얼마나 변하는지
→ 순응률을 구하기 위해서는, 이전 과정을 반복하되, 결과(Y) pv를 처치(T) prime_card로 대체하면 됨
불연속 설계에서 ITTE와 순응률을 추정하여 도구변수 추정값(ITTE/순응률)을 계산하는 함수 정의하기
def rdd_iv(data, y, t, r, cutoff):
# cutoff($5,000)을 빼서 중앙정렬
centered_df = data.assign(**{r: data[r]-cutoff})
# 순응률 - 결과변수가 T인 회귀모델 적합
compliance = smf.ols(f"{t}~{r}*I({r}>0)", centered_df).fit()
# ITTE - 결과변수가 Y인 회귀모델 적합
itte = smf.ols(f"{y}~{r}*I({r}>0)", centered_df).fit()
param = f"I({r} > 0)[T.True]"
# ITTE를 순응률로 나누기
return itte.params[param]/compliance.params[param]rdd_iv(df_dd, y="pv", t="prime_card", r="balance", cutoff=5000)
> 732.8534752298891
balance=5000이고 categ가 'complier'(순응자)인 행만 필터링
(df_dd
.round({"balance":-2}) # round to nearest hundred
.query("balance==5000 & categ=='complier'")["tau"].mean())
> 700.011.9.4 밀도 불연속 테스트
불연속 설계에 대한 식별의 잠재적 문제
: 고객들이 배정변수(잔고)를 조작할 수 있다면, 스스로 실험군에 포함시킬 수 있다.
- 예시에서 고객이 프라임 카드를 무료로 받기 위해 계좌 잔고를 $5,000까지 늘린다면, 임곗값 바로 위/아래 사람들을 비교할 수 없게 됨(평활도 가정 위배)
임곗값 주변의 밀도를 그래프로 나타내서 원인을 시각적으로 확인해보면,
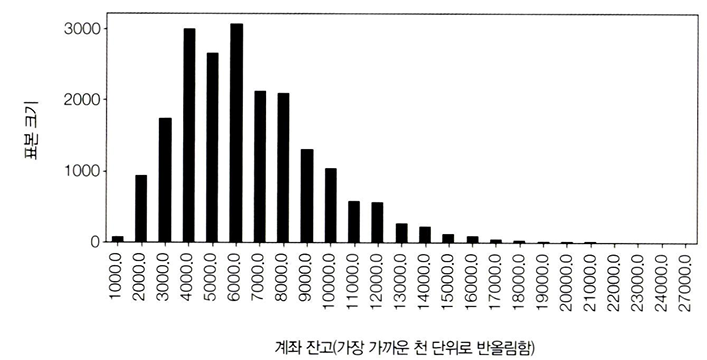
뭉침(bunching, 집군) 현상: 임곗값($5,000)에서 밀도가 증가하는 현상
→ 이 데이터에서는 해당 현상이 나타나지 않음
11.10 요약
- 많은 회사들은 고객이 직접 선택할 수 있는 제품/서비스를 제공하기에, 불응은 흔하게 발생하는 일
- 이러한 상황에서는 처치를 무작위 배정하더라도, 고객의 선택이 교란으로 작용함
1.
도구변수 Z
: ① 교란 없이 처치에 영향을 주고, ② 처치를 거치지 않으면 결과에 영향을 미치지 않는 변수
도구변수가 한 방향으로만 처치를 준다고 가정하면(단조성 가정), 순응률을 곱해 순응자의 ATE를 구할 수 있음
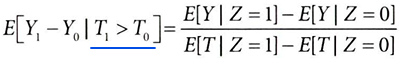
→ 처치 의도 효과(ITTE)를 순응률로 정규화해서 ATE 파악
2.
순응률이 낮은 경우, 분산이 커지는 문제를 해결하기 위해서 더 많은 표본이 필요하지만, 부족한 경우 결과(Y)를 잘 예측하는 공변량을 찾는 방법이 있음
3.
불연속성을 도구변수로 취급하여 LATE를 식별할 수 있음
✅ 도구변수를 활용한 실제 사례
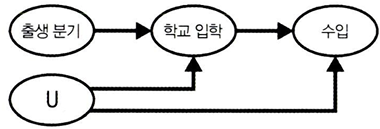
학교 교육(T)이 소득(Y)에 미치는 영향을 식별하고자 출생 분기(Z)를 도구변수로 활용
- 마지막 분기에 태어나면 학교를 더 오래 다닐 가능성이 높음 (처치에 영향)
- 출생분기는 수입에 직접적인 영향을 미치지 않음 (처치를 거치지 않으면 무작위 배정된 것처럼 보임)
- 이를 활용해서 교육 기간(T)이 1년 늘어날 때마다 평균 8.5%의 임금 상승(Y)을 기대할 수 있다고 추정하였다.
'데이터 분석 > 인과추론' 카테고리의 다른 글
| [10] 실무로 통하는 인과추론 with 파이썬 - 10장. 지역 실험과 스위치백 실험 (0) | 2024.07.16 |
|---|---|
| [9-2] 실무로 통하는 인과추론 with 파이썬 - 9장. 통제집단합성법 (0) | 2024.06.29 |
| [9-1] 실무로 통하는 인과추론 with 파이썬 - 9장. 통제집단합성법 (0) | 2024.06.23 |
| [8-2] 실무로 통하는 인과추론 with 파이썬 - 8장. 이중차분법 (0) | 2024.06.16 |
| [8-1] 실무로 통하는 인과추론 with 파이썬 - 8장. 이중차분법 (0) | 2024.06.11 |



