
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 인프런
- 컨브넷
- sql
- 스태킹 앙상블
- lightgbm
- pmdarima
- WITH ROLLUP
- 그로스 마케팅
- 캐글 산탄데르 고객 만족 예측
- 캐글 신용카드 사기 검출
- python
- tableau
- ImageDateGenerator
- 그룹 연산
- WITH CUBE
- 분석 패널
- 데이터 정합성
- splitlines
- 마케팅 보다는 취준 강연 같다(?)
- 데이터 증식
- XGBoost
- 로그 변환
- 그로스 해킹
- ARIMA
- Growth hacking
- DENSE_RANK()
- 데이터 핸들링
- 3기가 마지막이라니..!
- 리프 중심 트리 분할
- 부트 스트래핑
- Today
- Total
LITTLE BY LITTLE
[8-2] 실무로 통하는 인과추론 with 파이썬 - 8장. 이중차분법 본문

목차
<8장 이중차분법>
8.1 패널데이터
8.2 표준 이중차분법
8.2.1 이중차분법과 결과 변화
8.2.2 이중차분법과 OLS
8.2.3 이중차분법과 고정효과
8.2.4 이중차분법과 블록 디자인
8.2.5 추론
8.3 식별 가정
8.3.1 평행 추세
8.3.2 비기대 가정과 SUTVA
8.3.3 강외생성
8.3.4 시간에 따라 변하지 않는 교란 요인
8.3.5 피드백 없음
8.3.6 이월 효과와 시차종속변수 없음
8.4 시간에 따른 효과 변동
8.5 이중차분법과 공변량
8.6 이중 강건 이중차분법
8.6.1 성향점수 모델
8.6.2 델타 결과 모델
8.6.3 최종 결과
8.7 처치의 시차 도입
8.7.1 시간에 따른 이질적 효과
8.7.2 공변량
8.8 요약
8장. 이중차분법
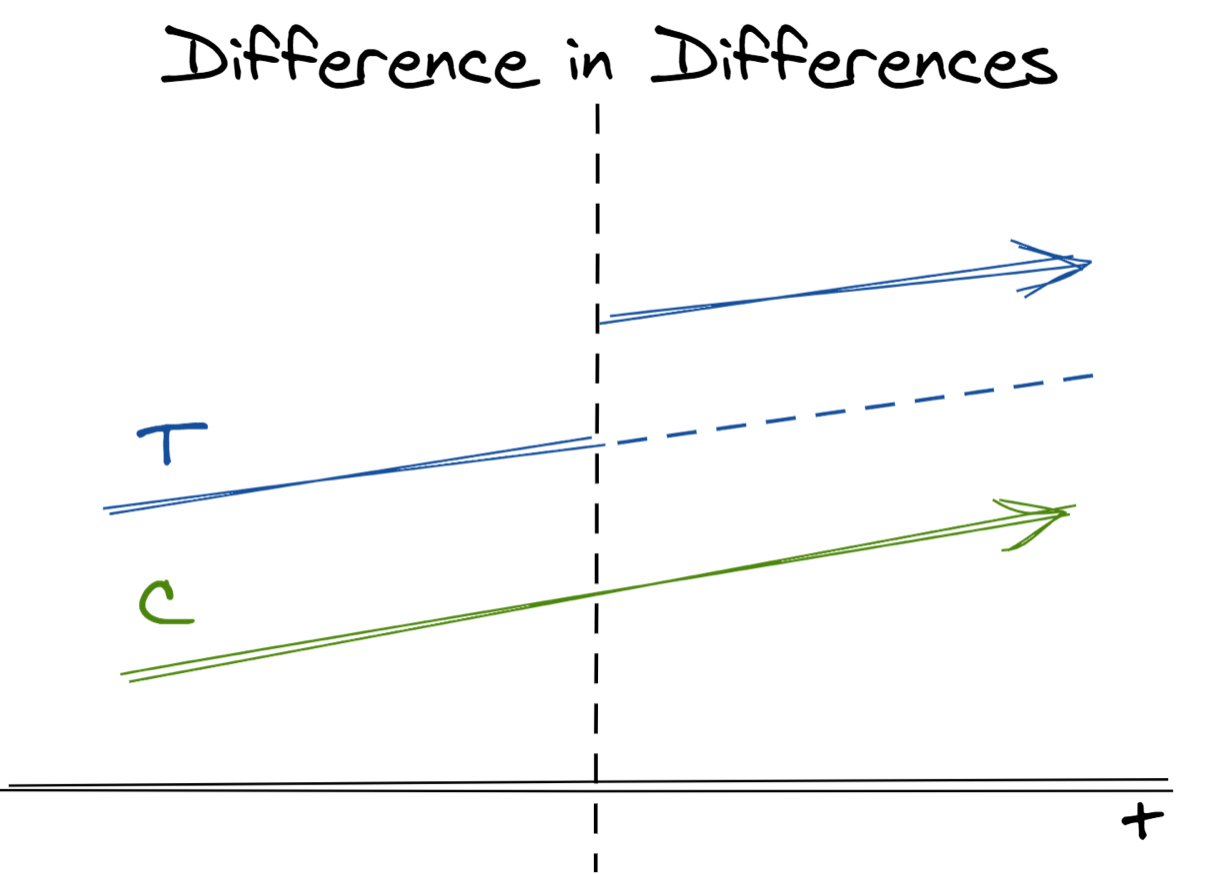
8.4 시간에 따른 변동
- 지금까지 살펴본 표준 이중차분법에 대한 식별 가정을 바탕으로, 이중차분법의 변형에 대해 조금 더 알아보자.
- 먼저 '시간에 따른 효과 변동'을 고려하는 접근법을 살펴보면,
- 처치 직후 실험군과 대조군의 차이가 바로 커지지 않는다.
- 즉, 전체적인 처치효과가 나타나기까지는 어느 정도 시간이 필요하며, 처치효과가 즉각적이지 않음
- 이런 경우, 최종 처치 효과가 과소평가될 수 있다.
위 문제를 해결하기 위한 간단한 방법 중 하나는 시간에 따른 ATT를 추정하는 것,
모든 시간대를 반복하며, 해당 시간대만이 처치 이후의 기간인 것처럼 이중 차분법을 적용해보자.
def did_date(df, date):
df_date = (df
.query("date==@date | post==0") # date가 주어진 날짜이거나, post=0인 행만 선택
.query("date <= @date") # 주어진 날짜 이전의 데이터만 선택
.assign(post = lambda d: (d["date"]==date).astype(int))) # 주어진 날짜와 같은 date값을 가진 행의 post=1로, 그렇지 않은 행의 post=0으로 설정
m = smf.ols(
'downloads ~ I(treated*post) + C(city) + C(date)', data=df_date
).fit(cov_type='cluster', cov_kwds={'groups': df_date['city']})
att = m.params["I(treated * post)"]
ci = m.conf_int().loc["I(treated * post)"]
return pd.DataFrame({"att": att, "ci_low": ci[0], "ci_up": ci[1]},
index=[date])- 위 함수는 인수로 받은 날짜가
- 처치 후 기간에 해당하면 아무것도 하지 않고,
- 처치 이전 기간에 해당하면 이후 날짜를 제외한다.
- 이 필터로직을 통해서 처치 이전 기간에도 이중차분법을 적용할 수 있다.
- 이를 위해 처치 이전 기간의 날짜가 전달되면, 처치 이후 기간을 지정된 날짜로 재할당하는 코드가 추가됨
- 이제 처치 이전 기간의 날짜가 전달되면, 이 함수는 마치 그 날짜가 처치 이후 기간에서 온 것처럼 처리하게 된다. (↔이는 시간 차원에서 일종의 위약 테스트와 같다.)
위 함수는 한 날짜에 대해서 작동하기에, 가능한 모든 날짜에 대한 효과를 파악하려면, 날짜들을 차례대로 반복하며 날짜별 DID추정값을 구한다.
*이중 차분법은 최소 두 개의 시간대가 필요하니 첫 번째 날짜는 건너뛰어야 한다.
post_dates = sorted(mkt_data["date"].unique())[1:] # 날짜들을 오름차순으로 정렬한 후, DATE열의 고유한 날짜를 추출한다. [1:]는 첫 번째 날짜를 제외하기 위함
atts = pd.concat([did_date(mkt_data, date)
for date in post_dates])
atts.head()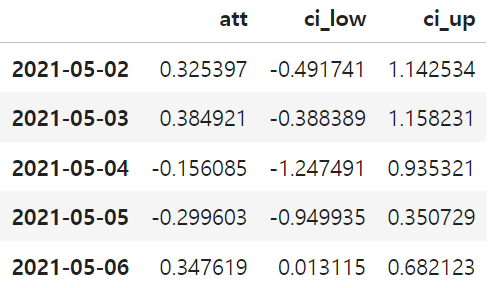
x를 date로, y를 ATT 로 시간에 따른 효과 변동과 신뢰구간을 시각화해보자.
plt.figure(figsize=(10,4))
plt.plot(atts.index, atts["att"], label="ATT 추정값")
plt.fill_between(atts.index, atts["ci_low"], atts["ci_up"], alpha=0.1)
plt.vlines(pd.to_datetime("2021-05-15"), -2, 3, linestyle="dashed", label="개입")
plt.hlines(0, atts.index.min(), atts.index.max(), linestyle="dotted")
plt.plot(atts.index, mkt_data.query("treated==1").groupby("date")[["tau"]].mean().values[1:], color="0.6", ls="-.", label="$\\tau$")
plt.xticks(rotation=45)
plt.title("시간에 따른 이중차분법 ATT")
plt.legend()
- 처치 이후에 효과가 바로 증가하지 않음을 보여준다.
- 효과가 완전히 나타나기 전인 초기 기간을 빼면, ATT가 약간 더 높아보이기도 함
- 개입 이전 기간에 추정된 효과(연한 점선)가 모두 0에 가까워, 처치 이전에는 실제로 어떤 효과도 발생하지 않았음을 나타낸다.
- 이 부분은 비기대 가정(SUTVA, 처치 이전에 파급효과가 발생하지 않음) 을 만족한다는 강력한 증거로 볼 수 있다.
8.5 이중차분법과 공변량
- 앞서 배운 이중차분법의 변형 이외에도 모델에 처치 전의 공변량을 포함하는 방법이 있다.
- 이 방법은 평행 추세 가정을 만족하지 않지만, 공변량을 조건부로 두었을 때 해당 가정이 만족하는 경우 유용하게 사용할 수 있다.
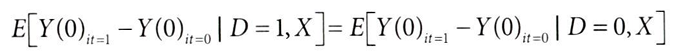
이전과 같은 마케팅 예제에서, 지역별로 데이터가 있다고 가정하고, 지역별 실험군-대조군에 대한 결과를 시각화해보자.
plt.figure(figsize=(15,6))
sns.lineplot(data=mkt_data_all.groupby(["date", "region", "treated"])[["downloads"]].mean().reset_index(),
x="date", y="downloads", hue="region", style="treated", palette="gray")
plt.vlines(pd.to_datetime("2021-05-15"), 15, 55, ls="dotted", label="개입")
plt.legend(fontsize=14)
plt.xticks(rotation=25);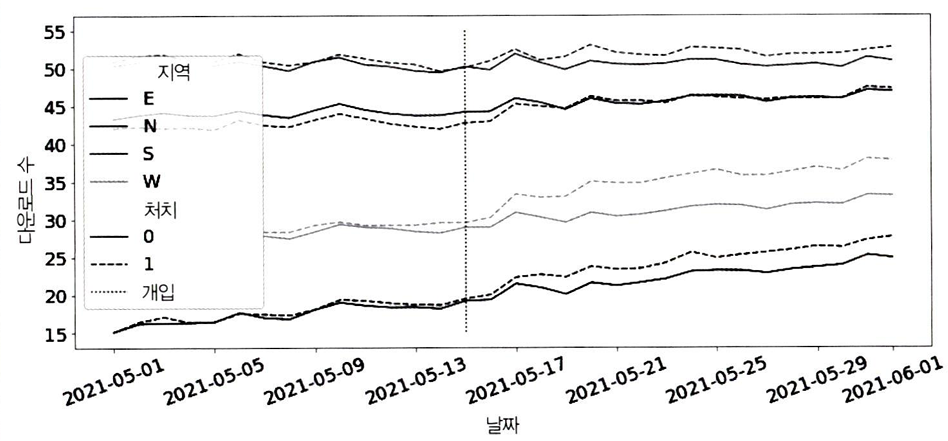
- 처치 이전의 경우, 지역 내에서는 평행하지만, 지역 간에는 평행하지 않음
- 이런 경우에는 지역별 서로 다른 추세를 반드시 고려해야 한다.
지역에 관한 추가 공변량을 회귀모델에 포함해보자.
m = smf.ols('downloads ~ treated:post + C(city) + C(date) + C(region)',
data=mkt_data_all).fit()
m.params["treated:post"]
> 2.071153674125536→ 지역에 관한 추가 공변량만 포함시켜서는 문제가 해결되지 않는다
- 시간 고정 공변량의 효과가 대상 고정효과를 사용함으로써 사라진다고 했었는데,(8.3.4절 시간에 따라 변하지 않는 교란 요인 참고)
- 이는 관측할 수 없는 교란 요인 뿐만 아니라, 일정하게 유지되는 지역 공변량에도 해당된다.
- 따라서 회귀모델에 지역 공변량을 추가해봤자 아무런 효과가 없을 것
이중차분법 모델에 처치 전 공변량을 올바르게 포함하려면, 두 가지를 인지해야 한다.
- 실험군 기준값과 대조군 추세를 추정하는 방식으로 이중차분법이 작동한다.
- 대조군 추세를 실험군 기준값에 투영한다.
→ 즉, 지역별로 대조군 추세를 각각 따로 추정해야 한다는 것을 의미한다. 따라서 지역별 별도의 DID 회귀 모델을 적용하면 된다.
→ 상호작용 항을 포함한 포화모델을 사용하여, (post*treated) * C(region) 상호작용 항이 지역별로 추가되도록 한다.
m_saturated = smf.ols('downloads ~ (post*treated)*C(region)',
data=mkt_data_all).fit()
atts = m_saturated.params[m_saturated.params.index.str.contains("post:treated")]
attspost:treated 1.676808
post:treated:C(region)[T.N] -0.343667
post:treated:C(region)[T.S] -0.985072
post:treated:C(region)[T.W] 1.369363
dtype: float64- 북쪽(N) 지역의 효과는 1.67 - 0.34
- 남쪽(S) 지역의 효과는 1.67 - 0.98
그 다음 지역별 도시 수를 가중치로 사용하는 가중평균을 통해서 서로 다른 ATT를 집계한다.
reg_size = (mkt_data_all.groupby("region").size()
/len(mkt_data_all["date"].unique())) # 지역별 도시 수 계산
base = atts[0] # 모델에서 추정된 전체 평균 처치 효과를 BASE값으로 설정
np.array([reg_size[0]*base]+
[(att+base)*size
for att, size in zip(atts[1:], reg_size[1:])] # ATT의 첫 번째 값을 제외한 나머지 값들과, REG_SIZE의 첫 번째 값을 제외한 나머지 값을 짝지어주기
).sum()/sum(reg_size)
> 1.6940400451471818
만약 공변량이 많거나, 공변량이 연속형인 경우에는 이 방법이 적절하지 않음
① (post*treated) * C(region) : 지역 변수를 처치 여부 및 처치 후 더미변수 모두의 상호작용하는 대신,
두 번째 방법 사용하기
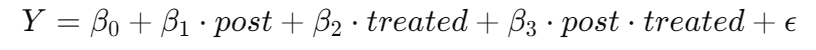
② (post*(treated + C(region)) : 각 지역 실험군의 추세를 별도로 추정하되, 실험군과 처치 후 기간에 대해서는 단일 절편 이동을 적합시킨다.


*지역별 실험-대조군의 downloads 수 추세를 별도로 추정하면서도, 처치 후 실험군의 추가적인 효과를 단일 절편 이동으로 표현한 식이다.
m = smf.ols('downloads ~ post*(treated + C(region))',
data=mkt_data_all).fit()
m.summary().tables[1]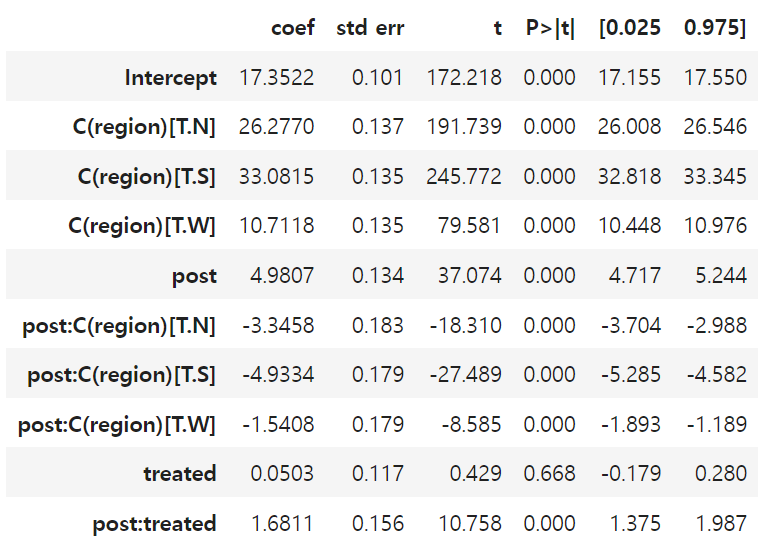
- 여기서 post:treated에 관한 매개변수를 ATT로 해석할 수 있다.
- 이전에 추정한 ATT(=1.694)와 유사하다.
* 회귀는 지역별 ATT를 지역 표본 수가 아닌, 분산에 따라 평균을 구한다.
* 즉, 회귀는 처치가 더 고르게 분포된(분산이 큰) 영역에 더 큰 가중치를 부여한다.
- 두 번째 접근 방식은 속도는 훨씬 바르지만, 상호작용하는 부분에 있어 신중해야 한다.
8.6 이중 강건 이중차분법
- 조건부 평행 추세 가정을 만족시키기 위한 또 다른 방법으로 이중 강건 이중차분법(DRDID, Doubly Robust Diff-in-Diff)가 있다.
이중강건 추정량
: 모델 기반과 디자인 기반 식별을 모두 결합하여, 적어도 둘 중 하나가 정확하기를 기대하는 방법으로, 5장에서는 성향점수와 선형회귀분석을 결합하는 방법을 살펴보았다.
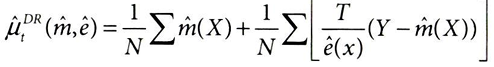
- 5장에서 배운 이중 강건 추정량의 아이디어를 활용하되, 몇 가지 조정이 필요하다.
- 이중차분법은 결과 변화량인 △y 와 관련이 있기에, 기본 결과 모델 대신 시간에 따른 델타 결과 모델 사용
- ATT에만 관심이 있으므로, 대조군을 바탕으로 실험군을 재구성해야함
8.6.1 성향점수 모델
이중 강건 이중차분법의 첫 단계는 처치 전 공변량을 활용하여 실험 대상이 실험군에 속할 확률을 추정하는 성향점수 모델
*시간 차원을 고려하지 않으므로, 한 시점의 데이터만 있으면 됨
unit_df = (mkt_data_all
# 첫 번째 날짜 유지
.astype({"date": str})
.query(f"date=='{mkt_data_all['date'].astype(str).min()}'")
.drop(columns=["date"])) # 혼선을 피하기 위해 날짜 컬럼 제외
ps_model = smf.logit("treated~C(region)", data=unit_df).fit(disp=0)8.6.2 델타 결과 모델
델타 결과 모델을 적합시키기 위해 먼저 델타 결과 데이터 구성하기
- 처치 전후 기간의 평균 결괏값 차이 계산
- 계산을 마치면, 전후 기간의 차이를 통해 시간 차원이 배제되었기 때문에 실험 대상별로 하나의 행이 남는다.
delta_y = (
mkt_data_all.query("post==1").groupby("city")["downloads"].mean()
- mkt_data_all.query("post==0").groupby("city")["downloads"].mean()
)
구한 △y를 실험 대상 데이터셋에 합치고, 결과 모델 적합시키기
df_delta_y = (unit_df
.set_index("city")
.join(delta_y.rename("delta_y")))
outcome_model = smf.ols("delta_y ~ C(region)", data=df_delta_y).fit()8.6.3 최종 결과
- 최종 이중 강건 추정량을 구하기 위해서는 실제 △y, 성향점수, 그리고 델타 결과 예측값이 필요하다.
- 델타 결과 데이터(df_delta_y)에 성향 점수 모델로 ps(propensity score)를, 결과 모델로 y_hat을 예측한다.
df_dr = (df_delta_y
.assign(y_hat = lambda d: outcome_model.predict(d))
.assign(ps = lambda d: ps_model.predict(d)))
df_dr.head()
이중 강건 이중차분법의 모습을 생각해보자.
- 모든 이중차분법과 마찬가지로, ATT는 실험 대상이 처치 받았다면 나타날 추세와, 대조군 하에서 나타날 추세 간의 차이이다.
- 이들은 반사실 추정량이므로, 각각 △y1과 △y0으으로 표현
- ATT는 다음과 같다.
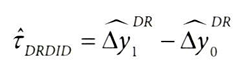
여기에서 △yD 값을 이중 강건하게 추정하는 방법을 생각해보자.
① Δy1^DR : 처치 그룹의 평균 처리 효과

- Ntr: 처치 그룹의 크기
- Δy: 처치 전/후 결과 변수 차이
- m^(Xi): 공변량 Xi에 기반한 결과 변수Y의 예측 값
- 실험군의 반사실을 추정하기 위해, y-m^(x)를 성향점수의 역수로 가중치를 주어 전체 모집단에 대한 y1을 재구성한다.
- ATT에만 관심있고, 실험군에 대한 모집단이 있기에 전체 모집단에 대한 재구성은 필요없음
② Δy0^DR : 대조 그룹의 평균 처리 효과
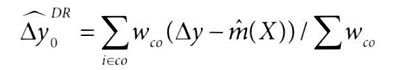

- wco: 대조그룹의 가중치 (성향 점수 기반)
- △y0에서는 1/1-(e^(x)) 가중치로 대조군 하에서의 전체 모집단을 재구성한다.
- (ATT를 구하는 것이 목적이기에) 대조군 하에서 실험군 모집단을 재구성해야 한다. 추가로 실험군이 될 확률 성향점수(e^(X))를 곱한다.
코드로 구현해보자
- dy1_treat : 처치 그룹의 평균 변화량 (△y) 에서 공변량 기반 예측값 (m^(X)) 을 뺀 평균
- dy0_treat = 대조 그룹의 평균 변화량 (△y) 에서 공변량 기반 예측값 (m^(X)) 을 뺀 가중 평균
# 처치-대조군 분리
tr = df_dr.query("treated==1")
co = df_dr.query("treated==0")
# 처치 그룹의 평균 처리 효과 계산
dy1_treat = (tr["delta_y"] - tr["y_hat"]).mean()
# 대조 그룹의 평균 처리 효과 계산
w_cont = co["ps"]/(1-co["ps"]) # 성향점수 기반 대조 그룹의 가중치
dy0_treat = np.average(co["delta_y"] - co["y_hat"], weights=w_cont)
print("ATT:", dy1_treat - dy0_treat)
> ATT: 1.6773180394442853- 위 추정값은 이중차분법에 공변량을 추가했을 때 얻은 ATT와 매우 유사하다.
- 이중 강건 이중차분법은 성향점수 모델이나 결과 모델 중 하나만 정확해도 잘 작동한다는 장점이 있다.
- 앞에서와 마찬가지로, 이중 강건 이중차분법에 대한 신뢰구간을 얻으려면, 앞서 구현한 블록 부트스트랩 함수를 사용하여 전체 과정(성향점수 모델, 델타 결과 모델)을 하나의 추정 함수에 모두 묶어 사용하면 된다.
8.7 처치의 시차 도입
지금까지는 블록 디자인을 기반으로, 처치 전과 후 두 시기만을 다루었다.
- 여러 날짜가 존재하지만, 핵심은 동일 시점에 처치 받은 대상-받지 않은 대상이 존재한다는 점
- 복잡한 계산 없이, 표본 평균을 비교하는 비모수적 방식으로 기준값과 추세 추정
그러나, 경우에 따라 상당히 제한적일 수 있다. 만약 실험 대상이 서로 다른 시점에 처치 받는다면?
❗시차 도입 설계
- 패널데이터에서 더 일반적인 상황으로, 여러 실험 그룹이 그룹별로 다른 시점에 처치를 받거나, 전혀 받지 않는 구조
- Gt : t 시점에 처치 받는 그룹 G를 코호트 Gt라고 한다.
- 마케팅 예제에 적용해보면, 처치 받지 않는 코호트와, 21-05-15에 처치 받은 코호트 (G05-15)에 대한 코호트 존재
21-07-31까지 모든 지역의 도시에 대한 데이터가 포함된 mkt_data_cohorts 데이터프레임을 살펴보자.

시각화를 통해 시차 도입 설계의 모습을 확인해보면,

- 21-06-01까지의 데이터만 있었을 때에는, 실험군이 작고 대조군이 큰 것처럼 보였는데,데이터를 확장해보니 06-01 이후에도 다른 도시들에 진행되었다는 것을 알 수 있다.
- 이 데이터에는 총 4개의 서로 다른 코호트(뒤에 붙은 날짜는 처치 받은 시점)가 있다. 3개는 처치 받은 그룹, 1개는 처치 받지 않은 그룹이다.
- 처치 받지 않은 그룹 = D∞ = D2100-01-01 : 블록 디자인과 마찬가지로 시차 도입에서는 한 번 처치가 시작되면, 그 상태가 영구적으로 유지된다고 가정한다.
차근차근 진행하기 위해 서부 지역에만 해당하는 데이터를 살펴보자.
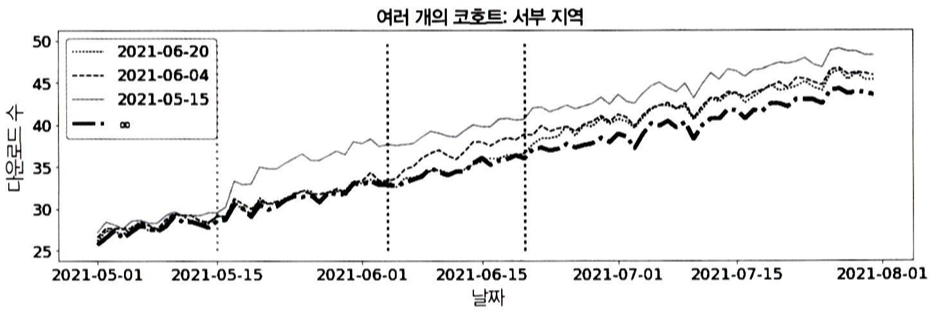
- 각 코호트의 시작 날짜가 점선으로 표시됨
- G05/15, G06/04, G06/20의 결과는 각각 21-05-15, 06-04, 06-20 날짜 직후에 증가한다.
- 반면, 대조군 D∞은 처치 전 실험군과 평행한 추세를 보인다.
주목해야할 점은 처치 효과가 나타나기까지 일정 시간이 걸린다는 것인데, 코호트를 정렬하여 시각화해서 이 점을 명확히 확인할 수 있다.

모든 코호트에서 처치 받은 시점에서 downloads수가 바로 증가하지 않는다.
이제 이중차분법으로 ATT를 구해보자.
twfe_model = smf.ols(
"downloads ~ treated:post + C(date) + C(city)",
data=mkt_data_cohorts_w
).fit()
true_tau = mkt_data_cohorts_w.query("post==1&treated==1")["tau"].mean()
print("True Effect: ", true_tau)
print("Estimated ATT:", twfe_model.params["treated:post"])True Effect: 2.2625252108176266
Estimated ATT: 1.7599504780633743- 추정된 ATT에서 효과가 하향 편향되었다.
❗시차 도입 설계에서는, 이중차분법 가정에 더해 <시간에 걸쳐 효과가 동일하다>는 가정도 필요하다.
- 위 데이터 시각화 그래프에서 볼 수 있듯이, 이 데이터는 효과가 나타나기까지 일정 시간이 걸리기 때문에, 처치 직후에는 낮고, 그 이후 점차 증가한다.
- 이러한 시간에 따른 효과 변동 때문에 ATT 추정값에 편향이 발생한다.
코호트 중 두 그룹에 대한 데이터를 살펴보자.
- 첫 번째 그룹은 이른 처치를 받은 코호트로, 21-06-04에 처치를 받은 그룹
- 두 번째 그룹은 늦은 처치를 받은 코호트로, 21-06-20에 처치를 받은 그룹
앞서 추정한 이원고정효과 모델(twfe_model)은 2x2 이중차분법을 실행하고, 최종 추정값으로 합친다.
- 이 중 한번은 늦은 처치를 받은 코호트(G06-20)를 대조군으로, G06-04의 처치효과 추정하는 케이스
- G06-20이 아직 처치 받지 않은 코호트로 간주될 수 있어 타당함
- 하지만 이 중 다른 한번은 반대가 되고, 이 경우에는 처치효과가 시간에 따라 변하지 않을 때에만 적합하다.

이른 처치 대 늦은 처치의 비교는 괜찮아 보인다.

- 문제는 2번 케이스이다. 대조군(G06/04, 진한 선)은 이미 처치를 받았는데에도 대조군 역할을 한다.
- 또한, 처치 효과가 시간에 따라 이질적이고 점진적으로 증가하여 대조군의 추세는 실험군(G06/20, 늦은 처치를 받은 코호트)가 처치를 받지 않았다면 나타났을 추세보다 더 가파르게 나타남
- 대조군 추세가 과대 추정됨
- 따라서 ATT 추정값은 하향 편향됨
문제의 핵심은 시간에 따른 이질적 효과이기 때문에, 더 유연한 모델을 사용해 이질성을 반영해보자.
8.7.1 시간에 따른 이질적 효과
앞서 시간에 따라 효과가 변하는 시차 도입 데이터에 이원고정효과를 적용하면 편향이 발생한다는 사실을 수식으로 표현하면,

→ 데이터 생성 과정에 다른 효과 매개변수를 갖고 있다는 의미
하지만, 해당 효과인 τ가 일정하다고 가정하면,
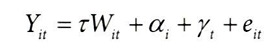
이론적으로는 다음 공식으로 문제를 해결할 수 있을 것 같지만,
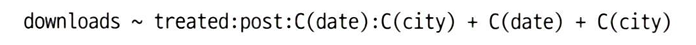
- 이 모델에 데이터 포인트보다 더 많은 매개변수가 있다는 것이 문제이다.
- 날짜와 실험 대상이 상호작용하므로, 각 기간에 대해 각 실험 대상마다 하나의 처치효과 매개변수를 갖게되고, 그 개수는 표본 수와 같아 ols 실행이 되지 않을 것
따라서, 모델의 처치효과 매개변수 수를 줄여야 한다.
- 매개변수 수를 줄이기 위해 실험 대상을 그룹화할 수 있는 방법을 생각해보아야 한다,
- 코호트를 통해 실험 대상을 자연스럽게 그룹화할 수 있다.
- 전체 코호트의 효과는 시간에 따라 동일한 패턴을 따른다.
실험 대상이 아닌, 코호트별로 효과가 변하도록 하면,
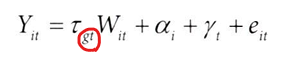
더 적은 수의 처치효과를 매개변수를 갖게 되고, 모델을 실행할 수 있다.
formula = "downloads ~ treated:post:C(cohort):C(date) + C(city)+C(date)"
twfe_model = smf.ols(formula, data=mkt_data_cohorts_w).fit()→ 각 코호트 및 날짜에 대해 하나씩, 여러 개의 ATT 추정값을 얻을 수 있다.
모델이 제대로 예측했는지 확인하기 위해 개별 처치효과 추정값의 평균을 실제 결과와 비교해보자.
df_pred = (
mkt_data_cohorts_w
.query("post==1 & treated==1")
.assign(y_hat_0=lambda d: twfe_model.predict(d.assign(treated=0)))
.assign(effect_hat=lambda d: d["downloads"] - d["y_hat_0"])
)
print("Number of param.:", len(twfe_model.params))
print("True Effect: ", df_pred["tau"].mean())
print("Pred. Effect: ", df_pred["effect_hat"].mean())Number of param.: 510
True Effect: 2.2625252108176266
Pred. Effect: 2.259766144685074
매개변수가 무려 510개나 되기는 하지만, 실제 ATT를 구할 수 있다. 이를 시각화해보면,

- 효과는 서서히 증가하고, 시간이 지나도 그 효과가 일정하게 유지된다.
- 또한, 모든 처치 전 기간과 처치 받지 않은 코호트에서는 효과가 0이다.
매개변수를 더 줄이는 방법을 생각해보자. 코호트보다 큰 기간의 효과만 고려해본다면,
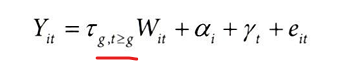
처치 전 날짜를 그룹화해야 하기에 많은 특성 엔지니어링이 필요하나, 구현 가능하다.
- post 변수를 생성하여 현재 코호트의 날짜보다 이후인 경우, 1로 설정하고, 그렇지 않으면 0으로 설정
- treated와 post의 상호작용 항을 포함한 ols 회귀분석을 수행하고, treated:post 항의 회귀 계수를 ATT로 사용한다.
cohorts = sorted(mkt_data_cohorts_w["cohort"].unique())
treated_G = cohorts[:-1]
nvr_treated = cohorts[-1]
def did_g_vs_nvr_treated(df: pd.DataFrame,
cohort: str,
nvr_treated: str,
cohort_col: str = "cohort",
date_col: str = "date",
y_col: str = "downloads"):
did_g = (
df
.loc[lambda d:(d[cohort_col] == cohort)|
(d[cohort_col] == nvr_treated)]
.assign(treated = lambda d: (d[cohort_col] == cohort)*1)
.assign(post = lambda d:(pd.to_datetime(d[date_col])>=cohort)*1)
)
att_g = smf.ols(f"{y_col} ~ treated*post",
data=did_g).fit().params["treated:post"]
size = len(did_g.query("treated==1 & post==1"))
return {"att_g": att_g, "size": size}
atts = pd.DataFrame(
[did_g_vs_nvr_treated(mkt_data_cohorts_w, cohort, nvr_treated)
for cohort in treated_G]
)
atts
그 다음, 결과를 가중평균으로 합치면, (가중치=T*N)
(atts["att_g"]*atts["size"]).sum()/atts["size"].sum()
> 2.2247467740558697→ 이전에 구한 추정값(2.2597)과 비슷하다.
- (+) 처치를 전혀 받지 않은 대상을 대조군으로 사용하는 대신에, '아직' 처치 받지 않은 대상을 대조군으로 사용하기에 대조군의 표본 크기를 늘릴 수 있다.
- (-) 동일한 코호트에 대해 이중차분법을 여러 번 실행해야 하기에 조금 더 번거롭다.
8.7.2 공변량
이원 고정효과의 편향 문제를 해결했으니, 이제 전체 데이터셋, 모든 기간, 시차 도입 설계, 모든 지역을 사용하는 방법을 살펴보고 모델에 공변량을 포함해야 한다.
공변량과 처치 후 더미변수를 상호작용 시키고, 공변량을 해당 날짜 열과 상호작용시키면 된다.
formula = """
downloads ~ treated:post:C(cohort):C(date)
+ C(date):C(region) + C(city) + C(date)"""
twfe_model = smf.ols(formula, data=mkt_data_cohorts).fit()
→ 여러 매개변수를 추정하므로 개별 효과를 계산하고 평균을 구하면 ATT를 추정할 수 있다.
df_pred = (
mkt_data_cohorts
.query("post==1 & treated==1")
.assign(y_hat_0=lambda d: twfe_model.predict(d.assign(treated=0)))
.assign(effect_hat=lambda d: d["downloads"] - d["y_hat_0"])
)
print("Number of param.:", len(twfe_model.params))
print("True Effect: ", df_pred["tau"].mean())
print("Pred. Effect: ", df_pred["effect_hat"].mean())Number of param.: 935
True Effect: 2.078397729895905
Pred. Effect: 2.04262628635845688.8 요약
- 패널데이터 방법은 인과추론 분야에서 빠르게 발전하며 큰 관심을 받고있는 방법론 중 하나이다.
- 시간 차원을 추가하면, 실험군의 과거 데이터로부터 실험군에 대한 반사실을 추정할 수도 있다는 점에서 많은 가능성을 가짐
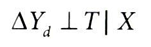
- 관측할 수 없는 교란 요인이 있을 때, 위의 가정에 도움이 됨
- 단, 해당 교란 요인이 시간 또는 실험 대상에 걸쳐 일정한 경우 ATT를 식별할 수 있다.
- 처치가 다른 시점에 이루어졌을 경우 시차 도입 설계가 필요한 데, 여기에서는 추가적인 함수형 가정이 필요하며, 이렇게 표준 이중차분법 공식에서 벗어나면 모델링에 특별한 주의가 필요하다.
'데이터 분석 > 인과추론' 카테고리의 다른 글
| [9-2] 실무로 통하는 인과추론 with 파이썬 - 9장. 통제집단합성법 (0) | 2024.06.29 |
|---|---|
| [9-1] 실무로 통하는 인과추론 with 파이썬 - 9장. 통제집단합성법 (0) | 2024.06.23 |
| [8-1] 실무로 통하는 인과추론 with 파이썬 - 8장. 이중차분법 (0) | 2024.06.11 |
| [7] 실무로 통하는 인과추론 with 파이썬 - 7장. 메타 러너 (1) | 2024.06.02 |
| [6] 실무로 통하는 인과추론 with 파이썬 - 6장. 이질적 처치효과 (0) | 2024.05.28 |



