
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 그로스 해킹
- Growth hacking
- lightgbm
- 그룹 연산
- 데이터 핸들링
- WITH ROLLUP
- ImageDateGenerator
- WITH CUBE
- ARIMA
- pmdarima
- 그로스 마케팅
- 로그 변환
- 컨브넷
- sql
- 부트 스트래핑
- 데이터 증식
- 마케팅 보다는 취준 강연 같다(?)
- tableau
- 데이터 정합성
- 캐글 신용카드 사기 검출
- python
- 3기가 마지막이라니..!
- DENSE_RANK()
- 분석 패널
- 캐글 산탄데르 고객 만족 예측
- XGBoost
- 리프 중심 트리 분할
- splitlines
- 인프런
- 스태킹 앙상블
- Today
- Total
LITTLE BY LITTLE
[10] 실무로 통하는 인과추론 with 파이썬 - 10장. 지역 실험과 스위치백 실험 본문

목차
Part 5. 대안적 실험 설계
<10장. 지역 실험과 스위치백 실험>
10.1 지역 실험
10.2 통제집단합성법 설계
10.2.1 무작위로 실험군 선택하기
10.2.2 무작위 탐색
10.3 스위치백 실험
10.3.1 시퀀스의 잠재적 결과
10.3.2 이월 효과의 차수 추정
10.3.3 디자인 기반의 추정
10.3.4 최적의 스위치백 설계
10.3.5 강건한 분산
10.4 요약
<10장. 지역 실험과 스위치백 실험>
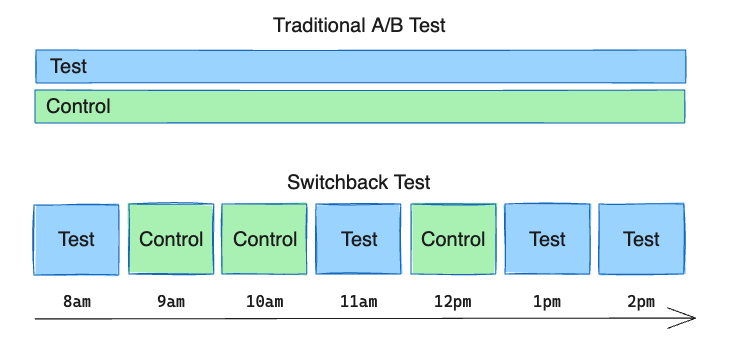
- 마케팅 효과를 추론하는 것이 어려운 이유 중 하나는 사람들을 무작위로 배정할 수 없기 때문이다.
- 한 가지 좋은 대안은 도시나 주와 같은 전체 대상을 실험군으로 하고, 다른 시장은 대조군으로 남겨두는 지역 실험을 수행하는 것
- 4부에서 배운 기법을 적용할 수 있는 패널데이터를 바탕으로 하며, 다루지 않았던 최적의 실험군과 대조군의 선정에 대해 배운다.
- 만약 전체 시장이 처치를 받았다면, 얻을 수 있는 효과에 근접한 추정값을 구하기 위해 지리적 실험군을 어떻게 선택할까?
- 주요 아이디어는 분석단위를 '고객'에서 '도시나 주 단위'로 확장하는 것
- 하지만 실험 대상이 하나뿐일 수도 있다.
- 다행히도 이 상황에서 스위치백 실험이라는 해결책이 있다.
- 한 처치를 여러 번 켜고 끄는 방식을 포함하며, 처치 받을 실험 대상이 1개만 있어도 처치를 여러 번 실시했다가, 실시하지 않음을 반복하며 일련의 전후 분석을 수행할 수 있다.
10.1 지역 실험

- 결과인 app_download에 초점을 맞춤
- 어느 도시에 처치해야 할까? 에 대한 결정을 할 수 있어야 함
- 개입 후 기간은 분석에서 제외 (df.query("post==0"))
전체 시장을 대표할 수 있는 도시그룹이 어디일까?
특정 도시그룹이 전체 시장을 대표하려면, 몇 개의 도시의 수가 필요할까?
2장에서 배운 표본 크기 공식(n=16σ ^2/δ ^2)을 고려해보자.
detectable_diff = df["app_download"].mean()*0.05 # δ=0.05 -> 5%의 효과를 탐지하려면
sigma_2 = df.groupby("city")["app_download"].mean().var()
np.ceil((sigma_2*16)/(detectable_diff)**2)[Out]
36663.0 # 40,000개의 도시가 필요하다.
40,000개가 필요한 데, 이 데이터에는 50개밖에 없다.
그렇다고 이중차분법을 사용하자니, ATT를 추정하는 방식이기에 전체 시장을 대표하는 효과는 알아내지 못할 수 있다.
① 표본이 부족하고, ② 전체를 대표하는 효과를 알고 싶을 때,
전체 시장을 대표하는 실험군을 식별함으로써 실험의 외적 타당성을 극대화하는 방법에 대해 알아보자.
10.2 통제집단합성법 설계
기존 방식에서 찾는 대상을 변경
기존: 알고자 하는 반사실의 시계열을 가장 잘 근사하는 가상의 대조군
→ 모든 실험 대상의 평균 행동을 근사하는 가상의 실험군
행에 기간이, 열에 도시가 오도록 피봇팅
df_piv = (df.pivot("date", "city", "app_download"))
df_piv.head()
1.
전체 평균을 구하기 위해 각 도시가 평균에 기여하는 정도를 의미하는 도시 가중치 벡터 f 구하기
f = (df.groupby("city")["population"].first()
/df.groupby("city")["population"].first().sum())
f.head()
2.
각 도시가 시장 평균을 제공할 수 있게 해주는 가중치 w 구하기
: 가중치 w와 결합했을 때 시장의 평균 결과를 제공하는 실험군 도시 조합 찾기
2-1. 제약조건 추가
: 가중치의 합은 1이어야하고, 음수가 아니어야 한다. ↔ |w|0 < N
: f가 w와 같아지면, 모든 도시가 실험군임을 의미하기에 대조군이 없어진다.
- 즉, 일부 도시는 실험군에 속하지 않아야 함
- 가중치 벡터 w를 조정하여 실험군과 대조군을 명확히 분리하는 과정
2-2. 제약조건 추가
: 한 도시가 실험군과 대조군에 동시에 속할 수 없다. ↔ wi νi = 0
시장 평균을 반영할 수 있는, 첫 번째와 다른 도시 그룹 찾기위함
→ 곱해서 0이 된다는 건 어떤 도시가 실험군에 속하면(w ≠ 0) 그 도시는 대조군에 속할 수 없고 (ν=0이어야 함) 그 반대도 마찬가지
→ 하지만 이 조건을 충족하는 건 실현 가능하지 않다.
앞서 구한 도시 가중치 벡터 f를 시각화해보면,
plt.figure(figsize=(12,3))
plt.bar(f.sort_values().index, f.sort_values().values)
plt.title("시장 내 각 도시의 규모 비율(f벡터)")
plt.xticks(rotation=90, fontsize=14);
→ 대규모 도시는 몇 개 없는 반면, 소규모 도시 수는 많기 때문
→ 문제를 해결하기 위해서는, 절편 이동 필요
두 가지 제약조건과 절편 이동을 추가해서 목적함수를 만들면,

- 가상의 실험군과 대조군 목표에 α0과 β0이라는 절편 항 추가
- 제약 조건 2가지 추가
- 마지막 제약조건은 실험군의 최대 도시 수 m에 대한 제약 조건
10.2.1 무작위로 실험군 선택하기
무작위로 도시를 선택해보자.
시장 평균 y_avg, 가능한 모든 도시의 목록 geos, 실험군 도시의 최대 수 m을 설정 (ex. 예산 상 최대 5개의 도시에만 처치할 수 있을 때, m=5)
y_avg = df_piv.dot(f)
geos = list(df_piv.columns)
n_tr = 5
5개 도시를 무작위로 선택해보면,
np.random.seed(1)
rand_geos = np.random.choice(geos, n_tr, replace=False)
rand_geos
> array(['manaus', 'recife', 'sao_bernardo_do_campo'. 'salvador', 'aracaju'], dtype='<U23')
무작위로 선택된 각 도시에 맞는 가중치 찾기
① get_sc()
: 가중치를 구하기 위해 졀편 이동을 허용하는 SyntheticControl 클래스 사용, 선택된 도시와 손실값 반환
def get_sc(geos, df_sc, y_mean_pre):
model = SyntheticControl(fit_intercept=True) # 절편을 포함한 모델 생성
model.fit(df_sc[geos], y_mean_pre) # 주어진 지역 5개로 y_mean_pre 예측
selected_geos = geos[np.abs(model.w_) > 1e-5] # 가중치 벡터 w의 절대값이 1e-5보다 큰 지역 선택
return {"geos": selected_geos, "loss": model.loss_ }
get_sc(rand_geos, df_piv, y_avg)
> {'geos' : array('salvador', 'aracaju'], dtype='<U23'), 'loss' : 1598616.80875266}
② get_sc_at_combination()
: 실험군과 대조군을 설정하고, 각 그룹에 대해 가상의 대조군을 생성하여 결과 반환
def get_sc_st_combination(treatment_geos, df_sc, y_mean_pre):
# 실험군에 대해 가상의 대조군 모델 생성 및 학습
treatment_result = get_sc(treatment_geos, df_sc, y_mean_pre)
# 실험군을 제외한 나머지 도시 선택
remaining_geos = df_sc.drop(
columns=treatment_result["geos"]
).columns
# 대조군에 대해 가상의 대조군 모델 생성 및 학습
control_result = get_sc(remaining_geos, df_sc, y_mean_pre)
return {"st_geos": treatment_result["geos"],
"sc_geos": control_result["geos"],
"loss": treatment_result["loss"] + control_result["loss"]}
resulting_geos = get_sc_st_combination(rand_geos, df_piv, y_avg)
> array(['salvador', 'aracaju'], dtype='<U23')
실험군+대조군 도시 합쳐서 몇 개인지 확인
resulting_geos.get("st_geos")
> 50
→ m이 작을 경우 전체 개수와 동일할 거라 예상 됨
- 실험군이 없을 때에는, 모든 도시를 대조군으로 선택하고, ν=f로 설정하는 것이 해결책
- m>0이지만 작은 경우, 모든 도시를 포함하고 가중치를 약간 조정하는 것이 최적의 선택

→ 가상의 실험군은 제대로 적합되지 않고, 대조군이 시장 평균과 비슷한 것을 볼 수 있다.
↔ m이 작으면, 가상의 대조군이 시장 평균을 잘 재구성하고, 대부분의 손실은 가상의 실험군에서 발생
10.2.2 무작위 탐색
방금 얻은 결과를 개선하기 위해, 다양한 도시 조합을 무작위 탐색하고, 성능이 좋은 조합을 선택하는 방법을 사용해보자.
1,000개의 5개 도시 조합을 생성하여 geo_samples에 저장, get_sc_at_combination()함수 적용
from joblib import Parallel, delayed
from toolz import partial
np.random.seed(1)
geo_samples = [np.random.choice(geos, n_tr, replace=False)
for _ in range(1000)]
est_combination = partial(get_sc_st_combination,
df_sc=df_piv,
y_mean_pre=y_avg)
results = Parallel(n_jobs=4)(delayed(est_combination)(geos)
for geos in geo_samples)
선택된 실험군 도시를 살펴보면 이 모델이 단 4개의 도시만 선택했음을 알 수 있다.
→ 주로 전체 시장 평균에 큰 영향을 미치는 큰 도시들이 포함되어 있음
resulting_geos = min(results, key=lambda x: x.get("loss"))
resulting_geos.get("st_geos")
> array(['nova_iguacu', 'belem', 'joinville', 'sao_paulo'], dtype='<U23')
가상의 대조군과 실험군을 시각화해보면, 대조군 뿐만 아니라 실험군도 평균을 잘 따라감을 확인할 수 있다.
synthetic_tr = SyntheticControl(fit_intercept=True)
synthetic_co = SyntheticControl(fit_intercept=True)
synthetic_tr.fit(df_piv[resulting_geos.get("st_geos")], y_avg)
synthetic_co.fit(df_piv[resulting_geos.get("sc_geos")], y_avg)
plt.figure(figsize=(10,4))
plt.plot(y_avg, label="Average")
plt.plot(y_avg.index, synthetic_co.predict(df_piv[resulting_geos.get("sc_geos")]), label="sc", ls=":")
plt.plot(y_avg.index, synthetic_tr.predict(df_piv[resulting_geos.get("st_geos")]), label="st")
plt.xticks(rotation=45)
plt.legend()
❗다른 실험 목표
- 여기에서는 실험의 외적 타당성을 극대화하기 위해서(=전체 시장을 대표하는 값을 추정하기 위해서), 실험군과 대조군의 손실의 합을 최소화하는 아이디어를 적용했지만, 실험의 목표가 달라지면, 다른 값을 최소화하는 방법을 찾아야 한다.
- 실험의 검정력을 극대화하는 데 초점을 맞출 때에는 표본 외 오차가 낮은 실험 대상의 집합을 선택
❗통제 집단합성법을 사용해서 실험을 설계했더라도, 다른 방법으로 결과를 해석할 수 있다.
- 추정량의 분산을 줄이기 위해 합성 이중차분법을 사용할 수도 있다.
- 단, 그 결과로 얻은 추정량의 분산 추정 시 도시군을 무작위로 선택하지 않았으므로 다른 실험 대상으로 처치를 재배정하는 추론 과정은 유효하지 않음
10.3 스위치백 실험
- 통제집단 합성법은 실험 대상이 적을 때 사용할 수 있는 방법이지만, 여전히 적당한 수의 실험 대상은 필요하다.
- 만약 실험 대상이 1개 뿐이라면?
- ex. 동적 가격 책정을 하고 있는 경우: 배달 수수료 인상 → 공급 늘어남(더 많은 운전 기사) → 고객 수요 조절 → 배달 시간에 어떤 영향을 미칠까?
- A/B테스트로 고객 절반에 대해서 가격을 인상하면, 전체 수요가 감소해 드라이버가 늘어나서 대조군에 혜택이 돌아갈 수 있기 때문에 효과 X
- 한 도시에만 있어서 통제집단합성법도 활용 불가하다면, 이 상황에 맞는 실험 설계 방법이 있다.
- ex. 동적 가격 책정을 하고 있는 경우: 배달 수수료 인상 → 공급 늘어남(더 많은 운전 기사) → 고객 수요 조절 → 배달 시간에 어떤 영향을 미칠까?
스위치백 실험
: 가격이 원래 수준으로 돌아갔을 때 가격 인상의 효과가 금방 사라진다면, 여러 번 가격 인상을 반복하여 전후 비교를 할 수 있다는 사실에 기반한 실험 설계 방법
- 단, 이 방법을 사용하려면 이월 효과의 차수(lag)가 작아야 한다.
- 즉, 가격 인상(처치)가 끝난 후에 장기간에 걸쳐 지속되면 안됨
- ex. 음식 배달의 경우 가격 인상 후 곧바로 공급이 증가하는 경향이 있고, 가격을 다시 인하하면 과잉된 공급이 몇 시간 내로 사라지기에 이월 효과의 차수가 작아 적용 가능함

- 120개의 기간(각 기간=1시간)으로 구성된 데이터
- 각 기간마다 50%의 확률로 처치 여부를 무작위로 배정
- d : 은 가격 인상(처치)이 적용되었는지 보여줌
- delivery_time : 주목하는 결과
- delivery_time_1 : 가격 인상이 항상 적용되었을 때의 배달 시간
- delivery_time_0 : 가격 인상이 항상 적용되지 않는 경우의 배달 시간
- tau: delivery_time1과 0의 차이로, 전체 처치 효과이자, 스위치백 실험에서의 인과 추정량
- 가격 인상(T)은 배달 시간(Y)을 줄이는 효과가 있기에 음의 값으로 나타남
- 이월 효과 때문에 첫 2시간 동안의 효과는 상대적으로 작게 나타남
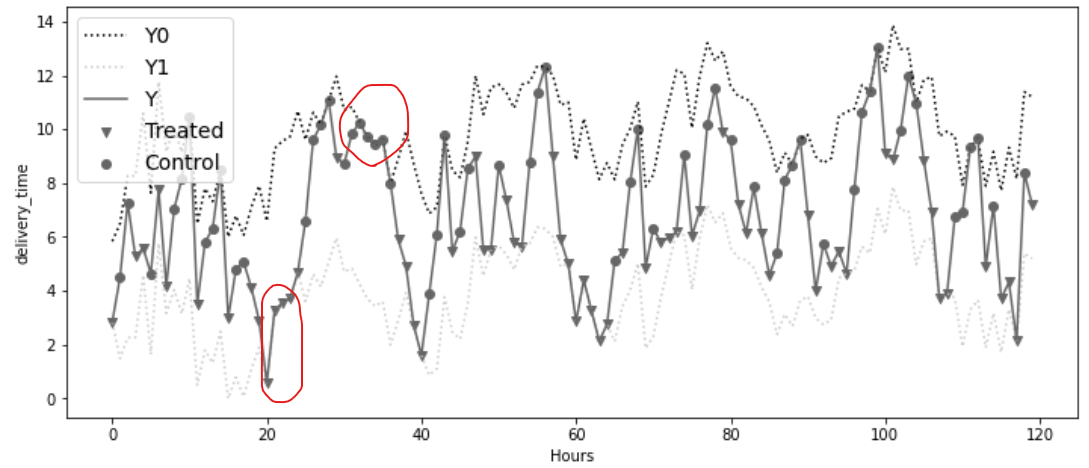
→ 스위치백 실험에서 관측된 결과 Y(실선)는 항상 처치를 받은 상태와 그렇지 않은 상태의 잠재적 결과(위 아래 점선) 사이에서 변동한다
- T=20~T=23까지를 예로 들어보면,
- 가격 인상이 연속해서 3번 적용되었고,
- 그 결과 배달 시간은 가격 인상 적용 시 배달 시간(점선)과 일치한다.
- 반대로 T=32 부근에서는 처치가 연속해서 3번 이상 적용되지 않음
- 그 결과, 가격 인상 적용 안됐을 때의 배달 시간(점선)과 일치한다.
- 1,2번에 해당하지 않으면(가격 인상이 연속해서 3번 미만으로 적용되면), 관측된 배달 시간은 중간 정도에 위치함(점선 사이)
즉, 이 실험에서는 결과가 세 기간 동안의 처치에 의해 결정된다. 바로 직전의 처치 뿐만 아니라, 그 이전의 두 기간 동안의 처치에도 영향을 받음

10.3.1 시퀀스의 잠재적 결과
- 처치효과가 이후 시간까지 영향을 주기에 스위치백 실험에서는 잠재적 결과를 처치 벡터의 형태로 정의해야 함
- 즉, Yt(D) = Y([d0, d1, ... , dT])
- 두 가지 과정으로 이를 단순화할 수 있다.
1. 처치에 대한 비기대 가정
: 잠재적 결과는 현재와 과거의 처치에만 의존하고, 미래의 처치에는 영향을 받지 않음
→ 이월 기간 m의 크기를 안다면, Yt(D) = Yt([dt-m, ..., dt])로 쓸 수 있음
→ Yt(D) = Yt([dt-2, dt-1, dt])
잠재적 결과를 위와 같이 정의했다면, 전체 처체 효과를 다음과 같이 쓸 수 있다.

m=2라면,
τ2 = E[Yt (1,1,1) - Yt(0,0,0)] 로 표현할 수 있다.
2. 시차의 효과는 가산적이다.

처치 효과를 위 두 가지 가정을 활용해서 단순화할 수 있도록 m을 추정하는 방법을 알아보자
10.3.2 이월 효과의 차수 추정
- 도메인 지식을 활용하여 m의 상한선을 설정해보자.
- 가격 인상 효과가 6시간 지속되지 않는다는 것을 알고 있다면, 회귀로 다음 모델을 추정할 수 있다.

d 열의 값을 1만큼 이동(지연)시켜서 0부터 6까지의 lag 값을 포함하는 새로운 열 추가하기
: 판다스의 .shift(lag) 메소드를 사용해서 처치에 대한 시차 만들기
# 각 lag의 이름을 d_l0, d_l1, ..., d_l6 형식으로 생성
df_lags = df.assign(**{
f"d_l{l}" : df["d"].shift(l) for l in range(7) # assign(**{"a":1, "b":2}) = assign(a=1, b=1)
})
df_lags[[f"d_l{l}" for l in range(7)]].head()
확보한 시차가 있는 데이터를 사용해서, 이전 시차들과 현재 처치(lag=0)에 회귀하기
import statsmodels.formula.api as smf
model = smf.ols("delivery_time ~" + "+".join([f"d_l{l}"
for l in range(7)]),
data=df_lags).fit()
model.summary().tables[1]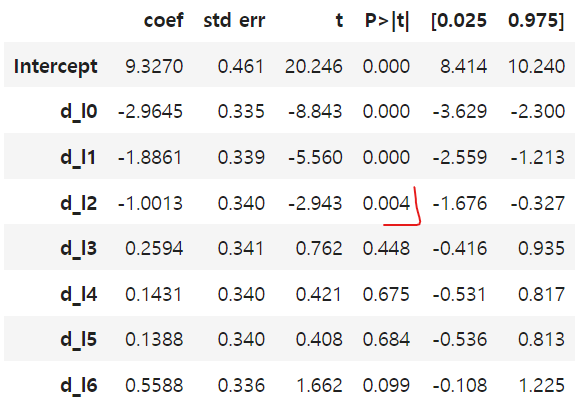
시차 매개변수는 두 번째 시차(d_l2)까지 유의하다.
↔ 즉, 2개의 기간에 걸친 이월효과가 존재한다는 것을 의미
## 절편 제거
tau_m_hat = model.params[1:].sum()
se_tau_m_hat = np.sqrt((model.bse[1:]**2).sum())
print("tau_m:", tau_m_hat)
print("95% CI:", [tau_m_hat -1.96*se_tau_m_hat,
tau_m_hat +1.96*se_tau_m_hat])
> tau_m: -4.751686115272022
> 95% CI: [-6.5087183781545574, -2.9946538523894857]
시차가 여러 개면 전체 효과의 추정값이 정확하지 않을 수 있음
두 개의 시차만 사용하면 분산을 크게 줄일 수 있다.
## 시차를 0,1과 2로 선택
tau_m_hat = model.params[1:4].sum()
se_tau_m_hat = np.sqrt((model.bse[1:4]**2).sum())
print("tau_m:", tau_m_hat)
print("95% CI:", [tau_m_hat -1.96*se_tau_m_hat,
tau_m_hat +1.96*se_tau_m_hat])
> tau_m: -5.8518568954422925
> 95% CI: [-7.000105171362163, -4.703608619522422]
10.3.3 디자인 기반의 추정
- 잠재적 결과 모델을 더 정확하게 설정하기 위해서, IPW(역확률 가중치) 를 사용할 수 있다.
- IPW: 무작위 처리에서 관찰된 결과를 처치 확률의 역수로 가중치를 부여하여 결과를 재구성하는 방법
- 이전에 배운 IPW 방식을 사용하되, 잠재적 결과가 처치 벡터로 정의되어 있다는 것을 고려
- ex. 효과가 두 기간에 걸쳐 이월되는 경우, Yt(0,0,0)과 Yt(1,1,1)을 재구성하려면 연속적으로 3개의 동일한 처치가 나타날 확률을 계산해야 함
m=2일 때 P(dt-2 = d, dt-1 = d, dt = d)이며 다음과 같이 표현할 수 있다.
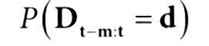
- Dt-m:t는 현재 및 최근 m개의 처치 벡터
- d는 상수 처치 d의 벡터
- 랜덤화(무작위 배정) 확률 p가 항상 50%이기에, P(Dt-m:t = 1) = P(Dt-m:t = 0) 이 되도록 만드는 것
- p = 50%이고, 처치가 모든 기간에 랜덤화되었다면, t=4,5일 때 lag=2인 window가 랜덤화 지점을 포함하기에,
- [1,1,1,1,1,1] 수열처럼 3번 연속 처치를 관측할 확률은(0.5^3=0.125) [na,na, 0.125, 0.125, 0.125, 0.125] 이다.
역확률 가중치 구하기
: 세 기간마다 랜덤화하는 상황에서 m+1개의 동일한 처치가 연속으로 관측될 확률을 계산해보자.
1. 랜덤화 창(randomization window) 식별하기
rad_points_3 = np.array([True, False, False]*(2))
rad_points_3
> array([ True, False, False, True, False, False])
랜덤화 지점의 누적 합을 계산하면, 지점별로 값이 1씩 증가
rad_points_3.cumsum()
> array([1, 1, 1, 2, 2, 2])→ 크기가 3인 두 개의 랜덤화 창(1,2)이 존재
2. 크기가 m+1인 이월 창(carryover window) 계산하기
sliding_window_view(): 주어진 배열을 지정된 일정한 크기의 창 크기(window size)로 슬라이딩하면서 각 창을 새로운 배열로 반환하는 기능을 하는 함수
- rad_points_3 = [1,1,1,2,2,2] 배열에 대해 창 크기 m+1 = 3으로 슬라이딩 뷰 생성
from numpy.lib.stride_tricks import sliding_window_view
m = 2
sliding_window_view(rad_points_3.cumsum(), window_shape=m+1)
> array([[1, 1, 1],
[1, 1, 2],
[1, 2, 2],
[2, 2, 2]])
3. 각 이월 창에 랜덤화 창이 몇 개나 포함되는지 계산하기
- = 각 이월 창에 포함된 서로 다른 숫자의 개수 (ex. 1,1,1 이면 모두 같으니 0이 됨)
- np.diff() 함수 사용
np.diff(sliding_window_view(rad_points_3.cumsum(), 3), axis=1)
> array([[0, 0],
[0, 1],
[1, 0],
[0, 0]])
4. 새로운 배열 생성
: 원래 배열의 각 지점에 해당하는 랜덤화 창의 개수를 포함하는 새로운 배열 생성기
- 각 열을 합산 후 1을 더하면, 원래 배열의 각 지점에서 해당하는 랜덤화 창의 개수 반환
- 처음 m개의 창을 버려야하기에 인덱스 2(T=3)에서 시작해서 배열의 시작 부분에 m개의 np.nan을 추가
n_rand_windows = np.concatenate([
[np.nan]*m,
np.diff(sliding_window_view(rad_points_3.cumsum(), 3),
axis=1).sum(axis=1)+1
])
n_rand_windows
5. 확률 벡터 구하기
: 실험에 대한 확률(여기에서는 0.5)를 취하고 앞서 구한 배열만큼 제곱하기
p=0.5
p**n_rand_windows
> array([ nan, nan, 0.5 , 0.25, 0.25, 0.5 ])
위 과정을 하나의 함수로 생성하면,
def compute_p(rand_points, m, p=0.5):
n_windows_last_m = np.concatenate([
[np.nan]*m,
np.diff(sliding_window_view(rand_points.cumsum(), m+1),
axis=1).sum(axis=1)+1
])
return p**n_windows_last_m
compute_p(np.ones(6)==1, 2, 0.5)
> array([nan,nan, 0.125, 0.125, 0.125, 0.125])역확률 가중치 P(Dt-m:t = d)를 계산했으면, 잠재적 결과를 얻기 위해 추정량의 나머지 부분 살펴보자

- T(전체 시간의 길이)-m(처치 기간) : 유효한 시간 기간의 수로 나눔
- t= m+1 부터 T까지의 시간 동안의 결과 Yt 합산
- 역확률 가중치 곱하기
위 추정량에서 분자의 지시 함수를 고려하면, 최근 m+1개의 처치가 d과 같을 때마다 true가 되어야 한다.
→ sliding_window_view()를 사용해서 처치 배열에 대한 m+1개의 창을 생성하고, 모든 요소가 처치와 동일한지 확인
def last_m_d_equal(d_vec, d, m):
return np.concatenate([
[np.nan]*m,
(sliding_window_view(d_vec, m+1)==d).all(axis=1)
])
print(last_m_d_equal([1, 1, 1, 0, 0, 0], 1, m=2))
print(last_m_d_equal([1, 1, 1, 0, 0, 0], 0, m=2))
> [nan nan 1. 0. 0. 0.]
> [nan nan 0. 0. 0. 1.]

정의한 함수를 사용해 역확률 가중치의 차이를 계산해서 처치 효과 추정
def ipw_switchback(d, y, rand_points, m, p=0.5):
p_last_m_equal_1 = compute_p(rand_points, m=m, p=p)
p_last_m_equal_0 = compute_p(rand_points, m=m, p=1-p)
last_m_is_1 = last_m_d_equal(d,1,m)
last_m_is_0 = last_m_d_equal(d,0,m)
y1_rec = y*last_m_is_1/p_last_m_equal_1
y0_rec = y*last_m_is_0/p_last_m_equal_0
return np.mean((y1_rec-y0_rec)[m:])ipw_switchback(df["d"],
df["delivery_time"],
np.ones(len(df))==1,
m=2, p=0.5)
> -7.426440677966101
- OLS로 얻은 효과 추정값보다 약간 낮다.
- 즉, 가격 인상이 배달시간을 더 줄인다.
- 분산이 훨씬 더 크다.
→ IPW 추정량을 사용하여 분산을 줄일 수 있는 실험을 설계하는 방법을 알아보자
10.3.4 최적의 스위치백 설계
- 기존 IPW 추정량 공식은, m+1개의 연속적인 처치가 동일한 시퀀스만 유지한다.
- 분산을 줄이기 위해 더 많은 데이터를 사용하되, 추정이 가능하려면, m+1 기간마다 랜덤화하는 방법이 있다.
- 이월 효과의 차수가 m=2인 경우, m+1=3 세 기간마다 랜덤화하는 것

- T는 최적의 랜덤화 지점
- m은 이월 효과의 차수
- n은 T/m = n을 만족하는 4 이상의 정수
예를 들어 T=12, m=2인 경우
- t=1에서 랜덤화하고, 크기가 2인 간격을 남겨둔 후,
- t=3에서 같은 식으로 크기가 2인 간격을 둔 t=5,7,9에서 랜덤화하고
- t=11에서 최종적으로 크기가 2인 간격을 남김
m = 2
T = 12
n = T/m
np.isin(
np.arange(1, T+1),
[1] + [i*m+1 for i in range(2, int(n)-1)]
)*1
> array([1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0])
m=3이고,T=15일 때는 t=1에서 다시 랜덤화하고, t=4에서 크기가 3인 간격을 둔채 t=7,10에서 랜덤화하고, 마지막으로 t=13에서 크기가 3인 간격을 남김
m = 3
T = 15
n = T/m
np.isin(
np.arange(1, T+1),
[1] + [i*m+1 for i in range(2, int(n)-1)]
)*1
> array([1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0])
→ 최적설계는 분산이 극적으로 감소되지는 않으나, 구현이 간단하다는 장점이 있다.
10.3.5 강건한 분산
IPW 추정량의 분산을 추정해보자
: 음식 배달 회사가 첫 번째 실험과 유사한 두 번째 실험 T=120, p=0.5)을 실행하는데, 최적 설계에 따라 랜덤화 지점을 결정했다고 가정

tau_hat = ipw_switchback(df_opt["d"],
df_opt["delivery_time"],
df_opt["rand_points"],
m=2, p=0.5)
tau_hat
> -9.921016949152545
분산 공식을 살펴보면,

- 분모는 표본 크기의 제곱 (처음 m개를 버렸으므로 m을 빼야 함)
- 분자 첫 번째, 마지막 항은 최적 설계의 시작과 끝에 남긴 간격을 고려하기 위한 값
- 중간에 있는 항은 두 개의 연속된 블록이 동일한 처치를 받았을 때마다 1이됨을 의미(지시함수)
- (Ȳk)블록 합의 정의
- 데이터를 K = T/m개의 블록으로 분할, 각 블록의 크기가 m이 되도록 한다.
- Yk바 = 블록 k에서의 결과 합
→ Y = [1,1,1,2,2,3]일 때 m=2, k={1,2} 일때는 아래와 같이 [3,5]가 된다.

이 공식을 코딩하기 위해 먼저 T가 m으로 나누어떨어지며, 그 몫이 4이상이 되도록 하기 위해 hsplit과 vstack 함수 사용
- np.hsplit함수로 배열을 수평으로 분할하고, 몇 개로 나눌지 인자를 지정(여기에선 3)
- vstack함수로 배열을 수직으로 쌓고, 결과로 나온 3개의 열을 수직으로 쌓아 2차원 배열을 만듦듦
np.vstack(np.hsplit(np.array([1,1,1,2,2,3]), 3))
> array([[1, 1],
[1, 2],
[2, 3]])
처치 벡터 [1,1,0,0,0,0]을 가져와서 지시 함수에도 동일한 작업 수행
- 연속된 두 블록의 처치가 동일한지 diff 함수로 확인
- 그그러면 블록이 하나더 삭제된다 ?
np.diff(np.vstack(np.hsplit(np.array([1,1,0,0,0,0]), 3))[:, 0]) == 0
분산 함수를 정의하면,
def var_opt_design(d_opt, y_opt, T, m):
assert ((T//m == T/m)
& (T//m >= 4)), "T must be divisible by m and T/m >= 4"
# 첫 번째 블록 버리기
y_m_blocks = np.vstack(np.hsplit(y_opt, int(T/m))).sum(axis=1)[1:]
# 첫 번째 열의 값
d_m_blocks = np.vstack(np.split(d_opt, int(T/m))[1:])[:, 0]
return (
8*y_m_blocks[0]**2
+ (32*y_m_blocks[1:-1]**2*(np.diff(d_m_blocks)==0)[:-1]).sum()
+ 8*y_m_blocks[-1]**2
) / (T-m)**2
위 함수로 분산을 추정하고 신뢰구간을 구해보면,
se_hat = np.sqrt(var_opt_design(df_opt["d"],
df_opt["delivery_time"],
T=120, m=2))
[tau_hat - 1.96*se_hat, tau_hat + 1.96*se_hat]
> [-18.490627362048095, -1.351406536256997]
→ 이 최적 설계가 OLS 분산을 최소화하지는 않지만, 기간마다 랜덤화할 때보다 더 정확한 추정값을 얻을 수 있다.
10.4 요약
- 사용 가능한 실험 대상의 수가 다소 부족한 경우 사용하는 대안적 실험 설계 방법
- EX. 실험 대상을 고객들에서 도시 전체로 실험 범위를 확대해야하는 경우
- 이월 효과의 차수가 커서 처치 효과가 사라지는 데 오랜 시간이 걸리는 경우 적합
- 이월효과의 차수가 작다면, 스위치백 실험이 좋은 대안이 됨
- 스위치백 실험: 동일한 실험 대상에 처치 배정과 미배정을 반복하면서 전후 비교를 여러 번 수행하는 방식
- 처치 확률과(50%가 이상적) 랜덤화 지점(혹은 기간)에 따라 정의된다.
- 이월 효과의 차수인 m이 0보다 큼을 안다면, 최적 설계는 m+1기간마다 랜덤화하는 것
- 통제 집단 합성법 설계의 목표: 전체 실험 대상의 평균 행동을 근사하는 소규모 실험 대상 집단을 찾는 것
이를 위해, 다음 목적함수를 최적화

- f: 각 실험 대상이 전체 평균에 기여하는 가중치
- w / ν: 가상의 실험군과 대조군에 대한 가중치
- m: 실험군의 최대 수에 대한 제약조건
'데이터 분석 > 인과추론' 카테고리의 다른 글
| [11] 실무로 통하는 인과추론 with 파이썬 - 11장. 불응과 도구변수 (0) | 2024.07.23 |
|---|---|
| [9-2] 실무로 통하는 인과추론 with 파이썬 - 9장. 통제집단합성법 (0) | 2024.06.29 |
| [9-1] 실무로 통하는 인과추론 with 파이썬 - 9장. 통제집단합성법 (0) | 2024.06.23 |
| [8-2] 실무로 통하는 인과추론 with 파이썬 - 8장. 이중차분법 (0) | 2024.06.16 |
| [8-1] 실무로 통하는 인과추론 with 파이썬 - 8장. 이중차분법 (0) | 2024.06.11 |



