
- 분류 전체보기 (192)

Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- ImageDateGenerator
- pmdarima
- ARIMA
- tableau
- WITH ROLLUP
- Growth hacking
- 데이터 정합성
- 그룹 연산
- 리프 중심 트리 분할
- XGBoost
- DENSE_RANK()
- 데이터 핸들링
- 인프런
- 그로스 해킹
- 스태킹 앙상블
- python
- 데이터 증식
- 부트 스트래핑
- splitlines
- 3기가 마지막이라니..!
- 캐글 산탄데르 고객 만족 예측
- 로그 변환
- sql
- 그로스 마케팅
- lightgbm
- 컨브넷
- 분석 패널
- WITH CUBE
- 캐글 신용카드 사기 검출
- 마케팅 보다는 취준 강연 같다(?)
Archives
- Today
- Total
LITTLE BY LITTLE
[7]실전! 텐서플로2를 활용한 딥러닝 컴퓨터비전 - 이미지 보강 및 분할(오토인코더, 합성곱 인코더-디코더1. FCN) 본문
4-2/이미지 딥러닝
[7]실전! 텐서플로2를 활용한 딥러닝 컴퓨터비전 - 이미지 보강 및 분할(오토인코더, 합성곱 인코더-디코더1. FCN)
위나 2022. 10. 4. 20:11개요
- 코드화란?
- 고차원에서 저차원으로 바꾸는 것
- 인코더와 디코더의 개념
- 픽셀-수준의 예측 (=픽셀에 대한 분류가 Segmentation, 즉 분할이 분류인 것)
- 디코딩 : 고차원 데이터를 출력하기 위함
- FCN (Dense Layer을 없애고, 대신에 Fully Convolutional Network 사용, Segmentation을 위함)
- U-Net (U의 형태를 갖고 있으며, 인코더와 디코더 부분으로 나뉘어져 있음)
인코딩(=압축)과 디코딩(=압축 해제, 타겟 도메인으로 매핑)

- 인코더 : 입력 샘플을 잠재공간, 즉 숨겨진 구조화 값 집합에 매핑하는 함수
- *잠재공간 : 입력공간과 타겟공간보다 작음
- 샘플에 포함된 의미론적 정보를 추출/압축 하기 위해 설계 또는 훈련된다.
- 디코더 : 이 잠재공간의 요소를 사전 정의된 타겟 도메인으로 매핑하는 여함수 (여집합, 다시 돌려보내는 느낌)
- 디코더는 타겟 도메인에 대한 지식을 적용해 정보를 적절하게 압축 해제/완성한다.
- ex. 이미지, 오디오 압축 포맷
- 인코더-디코더 네트워크는 머신러닝의 기계 번역 등에서도 사용됨
- 인코딩과 디코딩은 각자 클래스 레이블과 함께 그래프로 표시될 수 있어 데이터셋에서 유사도와 구조 강조 가능
오토 인코딩(AE, Auto Encoder)
- 입력과 타겟 도메인이 동일하다.
- 모델의 병목 계층에도 불구하고, 원래 이미지로 복원(=적절하게 인코딩한 다음 품질에 영향을 주지 않고 이미지를 디코딩하는 것) 하는 것을 목표로 함
- 입력은 압축된 표현(=특징 벡터)으로 줄어듦
- 원본 입력이 나중에 요청되면 디코더에 의해 압축된 표현으로부터 재구성될 수 있다.
- 손실 : 입력과 출력 데이터 사이의 거리
- 이미지의 경우, 교차-엔트로피 손실 또는 L1/L2 손실로 계산될 수 있다.
인코딩, 디코딩의 목적
- 이미지를 변환하기 위해서
- 한 도메인 혹은 양식에서 다른 도메인이나 양식으로 매핑하기 위해서
- 거리감이 중요한 증감현실, VR에서 적용
- * 깊이 회귀 : 각 픽셀에 대해 카메라와 이미지 콘텐츠 사이의 거리 추정에 적용
- 주변의 3차원 표현을 구성함으로써 환경과 상호작용을 더 잘할 수 있다.
- 의미론적 분할을 하기 위함(Segmentation) : 각 픽셀에 대해 추정한 클래스를 반환하기위해 훈련
- 예술적인 용도로
- 낙서 예술 => 현실적인 허구 이미지로 변환
- 밤에 찍은 사진에서 낮 사진을 추정
오토인코더의 목적
- 인코딩과 디코딩 구성 요소가 전체로 훈련되지만, 용도에 따라 개별로 적용되도록 한다.
- 오토인코더의 인코더 부분 - 병목 때문에 인코더는 많은 정보를 보존하는 동시에 데이터를 압축해야하는데, 훈련 데이터셋이 갖고있는 반복 패턴에서 상관관계를 알아냄으로써 훈련된 도메인에서의 이미지의 저차원 표현을 얻기 위해 사용될 수 있다.
- 클러스터와 패턴을 강조하기 위해 데이터셋을 시각화할 때 사용됨 - 인코더가 제공하는 저차원 표현은 종종 이미지 사이의 콘텐츠 유사도를 보존하기 때문
- 경우에 따라 오토 인코더는 디코더를 위해 훈련되어 생성작업을 위해 사용된다.
- 잠재공간이 적절하게 구조화되었다면 무작위로 선정한 벡터는 모두 디코더에 의해 사진으로 변환될 수 있다.
- 가장 보편적으로 발견되는 AE 인스턴스는 노이즈를 제거하는 오토인코더
- 노이즈 제거 = 손실이 있는 연산을 취소함
- 원본 이미지를 반환하도록 훈련되어야 하기 때문에, 손실이 있는 연산을 취소하고(=노이즈를 제거하고) 누락된 정보 일부를 복원하는 방법을 학습한다.
- 백색 노이즈 / 가우스 노이즈를 취소하거나
- 누락된 콘텐츠를 복원하기 위해 훈련됨
- 스마트 이미지 업스케일링(=이미지 해상도 개선)에서도 사용 - 부분적 노이즈 제거도 가능
합성곱 인코더-디코더 (전치 합성곱, 팽창된 합성곱, 언풀링, FCN, U-NET)
전치 합성곱(=Deconvolutional Layer)
- 합성곱 계층에서 형상이 (H,W,D)인 입력 텐서에 대해 출력 형상의 공식
- 입력 텐서는 팽창 과정을 거쳐야 한다.

- padding 사용
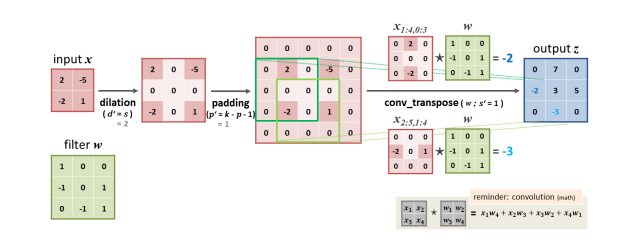
- dilation 사용(=양끝으로 몰고, 0으로 채워넣었다.)
- p는 원래 패딩의 크기이다.
* 추가 설명,,
[cs231n] 11강 탐지와 분리 (Detection and Segmentation) (1/4, 의미적 분리와 전치 합성곱 (semantic segmentation &
안녕하세요. 시작하겠습니다. cs23n 11강에 오신 것을 환영합니다. 오늘 우리는 탐지 (detection), 분리 (segementation)와 핵심 컴퓨터 시각 (computer vision) 작업들을 둘러싼 여러 많은 정말 흥분되는 주제
softwareeng.tistory.com
언풀링(Unpooling)
- 최대-풀링을 유사-반전하기 위한 최대-언풀링 연산 제안
- 최대-풀링을 역으로 뒤집을 수는 없지만, 가깝게 연산 정의 가능 => 각 최대-풀링 계층을 수정해서, 결과 텐서를 따라 풀링 마스크(=선택된 최대값의 원래 위치)를 출력함
- 풀링된 텐서와 풀링 마스크를 취해서 => 입력 값을 풀링되기 이전 형상으로 업스케일링된 텐서를 뿌림
- 고정된 연산이나, 훈련할 수 없는 연산에서 사용
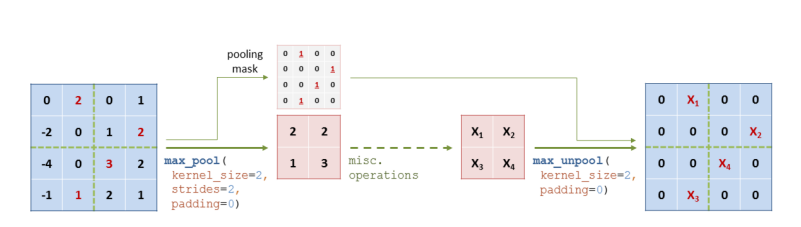
- pooling mask : 풀링 마스크에서 1에 해당하는 자리에 x1,x2,x3,x4를 넣어줌

- avg_pool에서는 pooling mask가 필요하지 않다
- x1,x2,x3,x4를 뻥튀기해서 같은 자리에 같은 값을 넣어준다.
업샘플링(=평균-언풀링 연산)과 크기 조정
- 평균-언풀링 연산은 최대-언풀링 연산보다 더 자주 사용되며, 이를 업샘플링이라 한다.
- 텐서의 각 값을 취해 이를 kxk 영역으로, 인접한 곳의 값을 같은 값으로 복제한다.
- 업스케일링 기법 중 이미지 크기 조정은 최근접 이웃 보간법이나 양선형 보간법을 통해 특징 맵을 업스케일링하는 것
- 디코더가 자신만의 특징을 학습하여 타겟 시그널을 더 잘 복원할 수 있도록, 사전에 정의된 업스케일링과 합성곱 연산의 조합은 인코더를 구성하는 합성곱과 풀링 계층을 반전시킴
팽창된 합성곱(=아트루스 합성곱)
- 제공된 특징맵을 업샘플링하는 용도가 아니라, 데이터의 공간차원을 희생시키지 않고, 합성곱의 수용 영역을 인위적으로 증가시키기 위해 제안
- * 수용 영역 : 합성곱 연산시 커널 크기에 따라 나오는 하나의 값은 그 영역의 정보를 함축하고있는 값이다.
- 추가적으로 커널에 적용될 팽창률을 정의하는 초매개변수가 있다는 점을 제외하면 표준 합성곱과 비슷하다.
- 아트루스 합성곱은 '커널'을 팽창시킨다는 점이 차이점이다.
- shape이 보존되기 때문에, 한 도메인의 이미지를 다른 도메인으로 매핑하기 위해 자주 사용된다.
- ex. 흑백 이미지 => 컬러 이미지
FCN(Fully Convolutional Networks)

- VGG-16에 기반하여 마지막 밀집계층(Dense Layer)을 1x1 합성곱 계층으로 대체하여 구성된 네트워크
- 업샘플링 블록을 사용해 확장되어 인코더-디코더로 사용된다.
- VGG-16 feature extractor부분이 인코더
- 마지막에 classification head(removed)부분을 떼고, 1x1 convolutional layer으로 대체하고, upsampling block을 붙여서 인코더-디코더로 사용하는 형태
- FCN의 구조
- 합성곱 계층 - 특징 추출
- 1X1 합성곱 계층 - 특징맵 채널 수를 데이터셋 객체 개수와 동일하게 변경함
- 낮은 해상도의 히트맵을 업샘플링(=전치 합성곱)
- 입력 이미지와 같은 크기의 맵을 생성
- 최종 특징맵과 레이블 특징맵의 차이를 이용해서 네트워크 학습

- 1번이 extractor,
- 2번이 객체 개수를 변경하는 단계이고,
- 3번에 pixel wise prediction이 히트맵을 upsampling하는 단계이다.

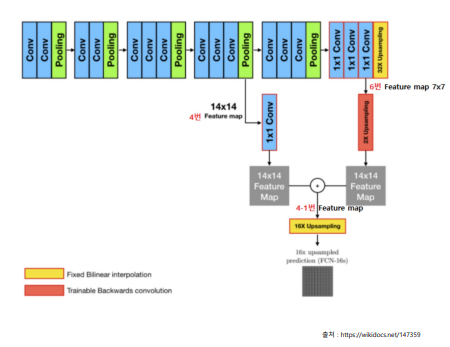

- FCN-32s
- 5번의 합성곱 블록을 통과하여 1/32만큼 줄어든 5번 특징맵
- 5번 특징맵이 합성곱 계층을 통과하여 같은 크기의 6번 특징맵을 얻는다.
- 6번 특징맵을 한번에 32배 업샘플링한다.
- FCN-16s
- 4번의 합성곱 블록을 통과해 1/16만큼 줄어든 4번 특징맵
- 6번 특징맵을 2배 업샘플링하 것과 4번 샘플링을 더한다.
- 새롭게 얻은 4-1번 특징맵을 한번에 16배 업샘플링한다.
- FCN-8s
- FCN-16s와 유사한 단계가 추가됨
- 4-1번 특징맵을 2배 업샘플링한 것과 3번 특징맵을 더한다.
- 3-1번 특징맵을 한번에 8배 업샘플링한다.
요약
1. 분할(Segmentation) : 픽셀에 대한 분류를 분할이라 한다.
2. 인코딩은 압축, 디코딩은 압축해제하는 개념으로 타겟 도메인으로 매핑할 때 사용된다.
3. 인코딩-디코딩은 데이터셋의 유사도와 구조를 강조하는데 사용될 수도 있다.
4. 오토인코딩은 입력과 타겟 도메인이 동일한 경우로, 원래 이미지로의 복원을 목표로 한다.
5. 오토인코딩에서 '손실'은 입력과 출력 사이의 거리
6. 인코딩,디코딩은 각 픽셀에 대해 추정한 클래스를 반환하기 위해서 훈련시키는 Segmentation을 하기 위함
7. 오토인코더는 노이즈를 제거하거나, 이미지의 해상도를 개선시키는데 사용된다.
8. 업샘플링 = 평균-언풀링 연산 (ex. 이미지 크기 조정에 사용 - 최근접 이웃 보간법), 합성곱 연산과 조합하여 사용
10. shape을 보존하기 위해서, 커널에 적용될 팽창률을 정의함으로써 팽창시켜 합성곱의 수용영역을 인위적으로 증가시킬 수 있다.
11. FCN(Fully Convolutional Network) : VGG-16에서 마지막 Dense Layer을 1x1합성곱으로 대체 + 업샘플링 블록을 추가하여 인코더-디코더로 사용하는 형태
'4-2 > 이미지 딥러닝' 카테고리의 다른 글
'4-2/이미지 딥러닝' Related Articles
more




Comments