
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Growth hacking
- 부트 스트래핑
- 로그 변환
- 마케팅 보다는 취준 강연 같다(?)
- WITH ROLLUP
- 그룹 연산
- ImageDateGenerator
- XGBoost
- WITH CUBE
- 인프런
- 데이터 핸들링
- tableau
- 그로스 마케팅
- lightgbm
- 데이터 정합성
- 데이터 증식
- 리프 중심 트리 분할
- 분석 패널
- DENSE_RANK()
- 컨브넷
- sql
- ARIMA
- 캐글 산탄데르 고객 만족 예측
- python
- pmdarima
- 3기가 마지막이라니..!
- 캐글 신용카드 사기 검출
- 스태킹 앙상블
- splitlines
- 그로스 해킹
- Today
- Total
LITTLE BY LITTLE
[4]실전! 텐서플로2를 활용한 딥러닝 컴퓨터비전 - 유력한 분류 도구( VGG, GoogLeNet, 인셉션, ResNet, 전이학습) 본문
[4]실전! 텐서플로2를 활용한 딥러닝 컴퓨터비전 - 유력한 분류 도구( VGG, GoogLeNet, 인셉션, ResNet, 전이학습)
위나 2022. 9. 16. 14:492부. 전통적 인식 문제를 해결하는 최신 솔루션
04. 유력한 분류 도구 (고급 CNN아키텍처의 이해 - VGG, GoogleLeNet, Inception,ResNet[잔차 네트워크], 전이학습)
05. 객체 탐지 모델 (YOLO, Faste R-CNN, 텐서플로 객체 탐지 API)
06. 이미지 보강 및 분할 (인코더-디코더로 이미지 변환, 노이즈 제거, 객체 분할)
3부. 컴퓨터 비전의 고급 개념 및 새 지평
07. 복합적이고 불충분한 데이터셋에서 훈련시키기 (입력 파이프라인, 데이터셋 보강, VAE와 GAN)
08. 동영상과 순환 신경망 (RNN, 장단기 메모리 셀, LSTM으로 동영상 분류하기)
09. 모델 최적화 및 모바일 기기 배포 (계산 및 디스크 용량 최적화, 온디바이스 머신러닝, MobileNet)
2-4. 유력한 분류 도구
Alexnet
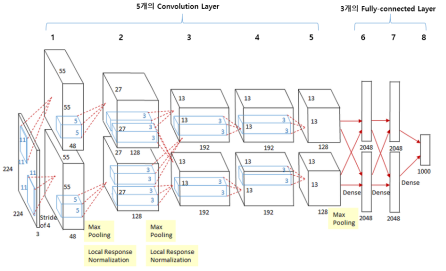
- 활성화 함수로 '정류형 선형 유닛(rectified linear unit, ReLU)' 사용, 경사 소실 문제를 피해서 훈련 개선
- CNN에 드롭 아웃 적용
- 합성곱과 풀링 계층으로 구성된 블록과 최종 예측을 위한 밀집 계층을 결합한 전형적인 CNN아키텍처
- 인위적으로 데이터셋 늘리기 - 원본 샘플을 무작위로 편집해서 다양한 훈련 이미지의 개수를 확대시킴
- 이 Alexnet로
- 더 많은 수의 계층 스택으로 구성된 네트워크를 만들고자 함
- (-)계층이 많아지면, 매개변수가 많아져 훈련 절차가 복잡해짐
↓
VGG
- 합성곱 계층과 풀링 계층으로 구성된 기본적인 CNN
- 계층 수를 늘리면서,그에 따른 매개변수의 증가에 따른 복잡성 문제를 개선한 네트워크

" [ 합성곱 계층 => 최대 풀링 계층 ] X 5개 => 마지막 3개는 밀집 계층으로 구성(+drop out) "
VGG는 CNN 아키텍처를 "표준화"시키는데 기여하였다.
1. "규모가 큰 합성곱을 여러 작은 합성곱으로 대체함"
- 처음에는 3X3 커널을 갖는 두 합성곱 계층을 쌓은 스택이 5X5 커널을 갖는 하나의 합성곱 계층과 동일한 수용 영역을 갖는다.
- 이와 마찬가지로, 3X3 합성곱 계층을 3개 연이어 배치하면, 수용 영역은 7X7이 되고
- 5개의 3X3 합성곱의 수용 영역은 11X11이 된다.
- 따라서 AlexNet의 필터는 11X11까지로 규모가 크지만, VGG 네트워크는 이보다 작은 합성곱 계층을 더 많이 포함해 더 큰 유효 수용 영역(ERF)를 얻을 수 있다.
- 장점
- 매개변수 개수를 줄인다. => 네트워크를 최적화하기 쉬워지고, 훨씬 가벼워짐
- 비선형성을 증가시킨다. => ReLU와 같은 비선형 활성화 함수가 오면, 네트워크가 복잡한 특징을 학습할 수 있는 능력이 증대된다.
2. "특징 맵 깊이를 증가"
- 합성곱 블록에 대한 특징 맵의 깊이를 두 배로 늘렸다. 깊이는 두 배로 늘고, 공간 차원은 반으로 줄게 된다.
- 공간 정보를 분류에 사용할 더 복잡하고 차별적인 특징으로 인코딩할 수 있음
3. "척도 변경을 통한 데이터 보강"
- 데이터 보강(data augmentation) : 이미지에 무작위 변환을 적용해 다양한 버전을 생성함으로써 훈련 데이터셋의 크기를 인위적으로 늘리는 절차
- '척도 변경'이라고 하는 데이터 보강 기법이 소개되었는데, 이 기법은 훈련이 반복될 때마다 이미지 배치를 적절한 입력 크기로 자르기 전, 그 척도를 무작위로 조정한다.
- 이렇게 무작위로 변환함으로써 네트워크는 다양한 척도의 샘플을 경험하게 되고, 이러한 척도 변경에도 불구하고 이미지를 적절히 분류하는 방법을 학습하게 된다.
- 다양한 범위의 현실적 변환을 포괄하는 이미지에서 훈련했기 때문에, 네트워크가 더 견고해진다.
- 테스트 시점에 무작위로 척도를 변경하고, 이미지를 자를 것을 제안한다.
- 이러한 방식으로 쿼리 이미지를 "여러가지 버전으로 생성"
- 모두 네트워크에 제공
- 네트워크가 익숙한 척도의 콘텐츠를 제공할 가능성↑
4. "완전 연결 계층을 합성곱 계층으로 대체"
- (전통적인 VGG 아키텍처 : Alexnet처럼 마지막에 여러개의 완전 연결 계층이 온다.)
- 그 완전 연결 계층(밀집 계층)을 합성곱 계층으로 대체하는 방법
- "완전 합성곱 계층, FCN, Fully Convolutional Network" : 밀집 계층을 두지 않는 네트워크
- 크기가 좀 더 큰 커널을 적용한 1번째 합성곱 세트는 특징맵의 공간 크기를 1X1으로 줄이고, 특징 맵의 깊이를 4096으로 늘림
- 마지막으로 1X1 합성곱 계층이 예측해야 할 클래스 개수만큼의 필터와 함께 사용
- 얻게된 1X1XN 벡터는 softmax 함수로 정규화된 다음 평면화(Flatten)되어 최종 클래스 예측으로 출력됨
- => 장점 : 사전에 이미지를 자르지 않고도, 다양한 크기의 이미지에 적용 가능
*참고
- **1X1 합성곱 : 일반적으로 공간 구조에 영향을 주지않고, 입력 볼륨의 깊이를 바꿀 때 사용, 각 공간위치에 대해 해당 위치의 모든 깊이의 값으로부터 새로운 값을 채운다.
- **모델 평균법(Model Averaging) : '일반 합성곱 신경망'과 '완전 합성곱 계층(FCN)'을 모두 훈련시켜 사용
VGG 정리
1. 규모가 큰 합성곱을 여러개의 작은 합성곱으로 대체하였다.
2. 특징 맵 깊이를 증가시켜, 공간 차원이 반으로 줄어들고, 공간 정보를 분류에 사용할 더 복잡한 특징으로 인코딩
3. 척도 변경(훈련시 입력 크기로 자르기 전, 척도를 '무작위로' 조정)을 통한 데이터 보강 => 네트워크가 견고해짐
4. 완전 연결 계층을 합성곱 계층으로 대체하였다.
GoogLeNet & 인셉션 모듈
- CNN 계산 용량 최적화를 위해서(매개변수▽), 병렬로 동작하는 인셉션 모듈을 도입한 모델
- 가로 방향에 폭이 있는 것이 특징(인셉션 구조) : 크기가 다른 필터와 풀링을 여러개 적용, 결과를 결합하여 하나의 빌딩 블록으로 사용하는 구조
- 1X1 크기의 필터를 사용한 합성곱 계층을 많이 사용하는 것이 특징(=>매개변수 제거&고속 처리)



- Google과 LeNet에서 따온 이름
- 구조적으로 '인셉션 블록' 개념 도입
- CNN 계산 용량을 최적화하는 것을 고려
- GoogLeNet은 5백만 개의 매개변수를 가지고 있어, Alexnet보다는 12배, VGG-16보다는 21배 가볍다.
- => 훈련이 비교적 빨리 끝난다.(일주일)
- 적은 매개변수로도 분류 대회에서 우승
- 여기서 도입한 인셉션 모듈은
- 병렬로 동작하는 다양한 계층으로 구성되어있다.
- 장점
- 정확도를 개선하기 위해 네트워크 스택에 추가해야할 계층을 알 수 있고,
- 해당 계층에서 최고 성능을 낼 수 있는 커널 크기를 알 수 있고,
- 다양한 크기의 커널은 동일한 척도의 특징에 반응하지 않는다는 (-) 극복 가능
- 작동 순서
- 맨 앞의 [conv + maxpooling 계층]에서 입력이미지가 처리된다.
- 이 정보는 9개의 인셉션 모듈 스택 통과
- 이 모듈은 수직, 수평으로 겹쳐놓은 계층 블록
- 각 모듈에서 입력 특징 맵은 한두 개의 서로 다른 계층으로 구성된 4개의 병렬 하위 블록에 전달된다.
- 위 4개의 병렬 연산 결과를 차원 깊이에 따라 서로 연결해 특징 볼륨으로 변환한다.
1. 인셉션 모듈로 다양한 세부 특징을 잡아냄
- 척도가 다양한 데이터 처리 가능
- 다양한 척도의 특징을 결합해서 더 광범위한 정보를 잡아낸다.
- 최신의 커널 크기를 선택할 필요가 없다.
- 네트워크가 "스스로" 각 모듈에 대해 어느 합성곱 계층에 더 의존하는지 학습
2. 병목 계층으로 1X1 합성곱 계층 사용
- 병목 계층 = 차원과 매개변수 개수를 줄이는 중간 계층
- 1X1합성곱 계층은 입력의 전체 깊이를 공간 구조에 영향을 주지않고 변경 가능
- 사전에 특징 깊이를 압축함으로써 합성곱 계층이 커지더라도 필요한 매개변수 개수 줄일 수 있음
- 병목 계층으로 1X1 합성곱 계층 사용
- 일반적으로 성능에 거의 영향 주지 않음
- 깊이 축소를 상쇄하는 병렬 계층이 있음
3. 완전 연결 계층 대신 풀링 계층 사용
- 마지막 합성곱 블록 다음, 완전 연결 계층 대신 평균풀링 계층 사용
- 매개변수 하나 없이 특징 볼륨을 7X7X1024 => 1X1X1024 로 줄임
- 밀집 계층이 오면 (7X7X1024) X 1024 = 51,380,224개의 매개변수가 추가될 것
- 네트워크가 표현력을 잃게되긴 하나, 계산상으로 이익을 많이 얻을 수 있는 방법
4. 중간 손실로 경사 소실 문제 해결
- 경사 소실 문제 : 경삿값은 매개변수 업데이트에 직접 사용되어서, 경사가 작아지면 계층들이 효과적으로 학습할 수 없는 문제
- 훈련에 사용되어 예측을 생성하는 두 개의 보조 분기가 있다.
- 훈련하는 동안, 네트워크를 통해 손실을 전파하는 과정 개선 (CNN이 깊어질수록 경사가 소실되어 발생하는 문제를 해결한다.)
- 다양한 네트워크 깊이에서 추가적 분류 손실 도입, 1번째 계층과 예측 사이의 거리를 줄임으로써 문제 해결
- 여러 손실에 의해 영향을 받는 계층의 견고함도 다소 개선
GoogLeNet 정리
1. 인셉션 모듈로 다양한 세부 특징을 잡아낸다.
2. 병목 계층으로 1X1 합성곱 계층을 사용하였다.
3. 완전 연결 계층 대신 풀링 계층을 사용하였다.
4. 중간 손실로 경사 소실 문제를 해결하였다.
TensorFlow Hub
TensorFlow Hub는 기계 학습 모델의 재사용 가능한 부분을 게시, 검색 및 사용하기 위한 라이브러리입니다.
www.tensorflow.org
ResNet & 잔차 모듈
- 매개변수가 쓰이지 않는 잔차 블록을 통해 극단적으로 깊이 들어갈 수 있게 만든 모델
- 입력 데이터를 합성곱 계층을 건너뛰어 출력에 바로 더하는 구조인 Skip connection을 도입한 것이 특징
- VGG 신경망을 기반으로 함
*참고
https://hwanny-yy.tistory.com/12
resnet-36, resnet-50 구현 tensorflow
목표 basemodel로 널리 사용되고 있는 resnet에 대하여 간단하게 알아보고 블럭 구현및 테스트를 진행 해보자! resnet은 residual path --> skip connection이라고도 표현되는 구조를 고안했다. 이미지 처리를
hwanny-yy.tistory.com
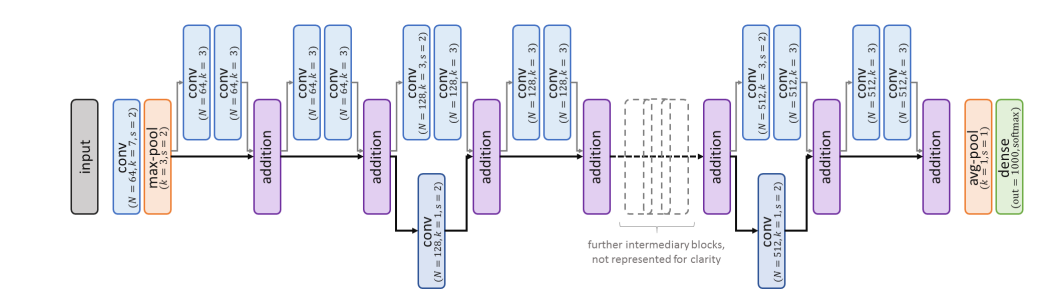

=> 처음을 제외하고는 균일하게 3x3 사이즈의 컨볼루션 필터를 사용하였다.
=> 특성 맵의 길이가 줄어들었을 때, 특성 맵의 깊이를 2배로 높였다.
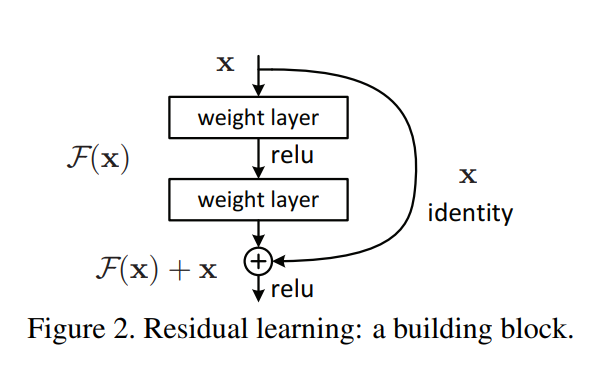
=> x가 입력이고, F(x)는 layer과 활성화 함수 relu를 통과한 것
=> VGG net과 유사하지만, 여기서는 identity x(원본)가 새로 등장
=> layer을 통과하고 나온 F(x)에 x를 더해주어 다음 블록의 입력으로 사용
=> 블록을 지날 때마다 gradient가 점점 희미해져 손실이나지만, 그것을 방지하기위해 layer을 통과하기 전 값을 더해줘서 보존을 할 수 있게 되는 것이다.
=> 152층까지도 block을 무리없이 쌓을 수 있었다 함
=> 현재도 base model로 Resnet이 많이 사용된다. 구조가 단순하고, 성능이 좋음
- 새로운 계층을 추가하다보면 정확도가 포화상태가 되다가 결국 저하된다.
- 일반적으로는 layer가 많고, 깊게 쌓을수록 좋은 성능을 보여주지면, 무조건 깊게만 하면 성능이 떨어진다.
- 그 이유는 깊어짐에 따라 1)과적합 발생, 2)경사소실 문제 발생
- 이 문제를 해결하기 위해 등장한 residual path
- 아키텍처 설명
- 병목 합성곱 계층 추가, 크기가 작은 커널 사용 지속적인 개선
- 서로 다른 깊이를 가진 몇 가지 버전이 있음
- 인셉션 아키텍처와 비슷하지만, 차이점은 더 얇다는 것
- [1개의 비선형 경로 + 1개의 항등 경로]로 구성
- 비선형 경로는 배치 정규화와 ReLu 활성화 함수와 함께 두 개의 합성곱 계층을 입력 특징 맵에 적용
- 항등 경로는 어떤 변환도 적용하지 않고 단순히 특징을 앞으로 전달
- 비선형 분기에 의해 깊이가 깊어지면, 특징의 깊이를 조절하기위해 병목 계층으로 1X1 합성곱 계층 적용
- 각 분기에서 얻은 특징맵은 다음 블록에 전달되기 전에 하나로 합쳐진다.
- 심도 결합을 통해 수행하지 X, 요소 단위 덧셈을 통해 수행
- 최종 블록에서 얻은 특징에 평균 풀링을 적용한다.
- => ResNet은 정보를 더 깊은 계층으로 전방 전달하고, 매핑 대신 잔차함수를 추정함, 극단적으로 깊이 들어가는 모델
1. 매핑 대신 잔차 함수 추정
- 네트워크 계층은 항등 매핑을 쉽게 학습할 수 없다. 성능 저하 현상이 불가피함
- CNN 위에 계층 추가시, 추가 계층이 항등 함수로 수렴할 수 있다면, 동일한 오차를 얻을 수 있다고 주장
- 그리고 그 추가 계층은 최소한 원래 네트워크의 결과를 품질 저하 없이 전달하는 방법을 학습할 수 있다.
- 잔차 블록 도입
- 일부 추가적 합성곱 계층을 사용해서, 데이터를 추가로 처리하는 경로 + 항등 매핑을 수행하는 경로
- CNN 위에 잔차블록을 추가함으로써, 처리 분기의 가중치를 0으로 설정, 사전 정의된 항등 매핑만 남겨 최소한 원래 성능을 유지할 수 있다.
- 스킵/숏컷 : 데이터 전달 경로를 부르는 말
- 잔차 경로 : 처리 경로를 의미
- 전반적으로 이 잔차경로는 입력데이터에 큰 변화를 주지 x, 더 깊은 계층으로의 패턴 전달을 가능케함
2. 극단적으로 깊이 들어가기
- 잔차 블록은 매개변수가 더 적음, 스킵과 덧셈 연산에는 매개변수가 쓰이지 않기 때문이다.
- 따라서 잔차 블록은 깊은 네트워크 구성시 효율적이다.
- ex. 하이웨이 네트워크 : 잔차블록에서 훈련 가능한 스위치 값을 사용, 어느 경로를 사용할지 결정
- ex. DenseNet : 블록 사이에 스킵 연결 추가
Resnet을 적용한 이미지 분류 예제(ing ...)
1. 네트워크 훈련시키기
사전 훈련된 Resnet 가져오기
import tensorflow as tf
from tensorflow.keras.applications import ResNet50top-5 Accuracy Metrics 추가하기 / Resnet 컴파일
optimizer = tf.keras.optimizers.Adam() #tf.keras.optimizers.SGD(momentum=0.9, nesterov=True)
accuracy_metric = tf.metrics.SparseCategoricalAccuracy(name='acc')
top5_accuracy_metric = tf.metrics.SparseTopKCategoricalAccuracy(k=5, name='top5_acc')
Resnet50.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy',
metrics=[accuracy_metric, top5_accuracy_metric])로그를 좀 더 보기 좋게 출력해주는 코드
# Setting some variables to format the logs:
log_begin_red, log_begin_blue, log_begin_green = '\033[91m', '\033[94m', '\033[92m'
log_begin_bold, log_begin_underline = '\033[1m', '\033[4m'
log_end_format = '\033[0m'
class SimpleLogCallback(tf.keras.callbacks.Callback):
""" Keras callback for simple, denser console logs."""
def __init__(self, metrics_dict, num_epochs='?', log_frequency=1,
metric_string_template='\033[1m[[name]]\033[0m = \033[94m{[[value]]:5.3f}\033[0m'):
"""
Initialize the Callback.
:param metrics_dict: Dictionary containing mappings for metrics names/keys
e.g. {"accuracy": "acc", "val. accuracy": "val_acc"}
:param num_epochs: Number of training epochs
:param log_frequency: Log frequency (in epochs)
:param metric_string_template: (opt.) String template to print each metric
"""
super().__init__()
self.metrics_dict = collections.OrderedDict(metrics_dict)
self.num_epochs = num_epochs
self.log_frequency = log_frequency
# We build a format string to later print the metrics, (e.g. "Epoch 0/9: loss = 1.00; val-loss = 2.00")
log_string_template = 'Epoch {0:2}/{1}: '
separator = '; '
i = 2
for metric_name in self.metrics_dict:
templ = metric_string_template.replace('[[name]]', metric_name).replace('[[value]]', str(i))
log_string_template += templ + separator
i += 1
# We remove the "; " after the last element:
log_string_template = log_string_template[:-len(separator)]
self.log_string_template = log_string_template
def on_train_begin(self, logs=None):
print("Training: {}start{}".format(log_begin_red, log_end_format))
def on_train_end(self, logs=None):
print("Training: {}end{}".format(log_begin_green, log_end_format))
def on_epoch_end(self, epoch, logs={}):
if (epoch - 1) % self.log_frequency == 0 or epoch == self.num_epochs:
values = [logs[self.metrics_dict[metric_name]] for metric_name in self.metrics_dict]
print(self.log_string_template.format(epoch, self.num_epochs, *values))
참고
https://hwanny-yy.tistory.com/12
resnet-36, resnet-50 구현 tensorflow
목표 basemodel로 널리 사용되고 있는 resnet에 대하여 간단하게 알아보고 블럭 구현및 테스트를 진행 해보자! resnet은 residual path --> skip connection이라고도 표현되는 구조를 고안했다. 이미지 처리를
hwanny-yy.tistory.com
전이 학습 활용 (Transfer Learn)
- 전이 학습 : 어떤 설정에서 학습된 내용이 다른 설정에서 일반화를 개선하기 위해 활용되는 것
- CNN은 특정 특징을 필터로 추출해 해석하도록 훈련되었기 때문에, 특징분포가 바뀌면 그 성능은 떨어지게 된다.
- 따라서 네트워크를 새로운 작업에 적용하려면 어느정도의 변환작업이 필요하다.
- 새로운 작업을 적절하게 학습하기에 충분한 데이터가 확보되지 않았을 때 효과적
- 풍부한 데이터셋에서 훈련한 성능좋은 네트워크의 아키텍처 전체 혹은 일부와 가중치를 재사용하는 것
- 새로운 모델은 이 조건에 따라 인스턴스화한 다음 '미세 조정'될 수 있다.
- 전이학습 전략
- 마지막에 분류하는 계층(Classifier)인 예측 계층을 제거한 사전 훈련된 CNN을 특징 추출 용도로 사용
- 그리고 제거되었던 예측 계층의 역할은 훈련된 한두 개의 새로 추가된 밀집 계층에서 처리
- 추출된 특징의 품질을 유지하기 위해 대체로 이 훈련 단계 동안 특징 추출기의 계층을 고정시킨다.
- 혹은 작업/도메인이 유사하지 않은 경우, 이 특징 추출기의 마지막 계층의 일부/전체를 미세 조정
- 전이학습 활용 사례
- 제한적 훈련 데이터 + 유사한 작업 수행
- 큰 데이터셋에서 수렴할 때까지 사전훈련시킨다.(일반적으로 사전훈련은 되어있다.)
- 마지막 계층 제거 후, 목표한 작업에 맞추어 조정한 계층으로 교체
- 미리 훈련된 계층을 고정시키고, 상단에 위치한 밀집 계층만 훈련시킴
- 데이터가 많지않아 특징 추출기의 구성 요소를 고정시키지 않을시 과적합 가능성
- 풍부한 훈련 데이터 + 유사한 작업 수행
- 특징 추출기의 최신 계층을 고정시켰던 것을 해제 (마지막 계층 일부를 Unfreeze)
- 목표 데이터셋이 클수록 안전하게 미세 조정할 수 있는 계층이 많아진다.
- 이로써 네트워크는 새로운 작업과 관련성이 높은 특징을 추출, 새로운 작업 수행 방법 학습
- 풍부한 훈련 데이터 + 유사하지 않은 작업 수행
- 무작위로 선정된 가중치(=가중치 초기화)보다 사전 훈련된 가중치를 사용해 네트워크를 초기화하는 것이 낫다. (비슷하지 않은 용도로 훈련되었더라도)
- 작업 또는 도메인이 어느정도 기초적 유사성을 공유해야하나(ex.오디오 데이터를 이미지 변환시 CNN 사용=>원래는 좋지 않은 방법), 꼭 그렇지는 않다
- 제한적 훈련 데이터 + 유사하지 않은 작업 수행
- ex. 꼭 딥러닝이 아닌 머신러닝으로도 해결가능한 문제
- 심층 모델을 적용하고 용도에 맞게 조정하는 것이 적절한가? 재검토
- 적절하지 않은 모델을 작은 데이터셋에서 훈련시키면 과적합이 일어남
- 깊이가 깊은 사전 훈련된 추출기는 특정 작업과는 무관한 특징 반환
- 하지만 CNN의 1번째 특징이 저차원 특징에 반응한다는 점을 감안하면, 여전히 전이학습에서 혜택 볼 수 O
- 남은 계층 위에 얕은 분류기 추가 => 새로운 모델 미세 조정
- 제한적 훈련 데이터 + 유사한 작업 수행



