
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- 컨브넷
- splitlines
- sql
- 데이터 증식
- 분석 패널
- 그룹 연산
- tableau
- ImageDateGenerator
- 캐글 산탄데르 고객 만족 예측
- 부트 스트래핑
- 로그 변환
- Growth hacking
- 데이터 핸들링
- 리프 중심 트리 분할
- 그로스 해킹
- 3기가 마지막이라니..!
- 스태킹 앙상블
- XGBoost
- WITH CUBE
- WITH ROLLUP
- 마케팅 보다는 취준 강연 같다(?)
- python
- lightgbm
- DENSE_RANK()
- 데이터 정합성
- 그로스 마케팅
- 캐글 신용카드 사기 검출
- pmdarima
- 인프런
- ARIMA
Archives
- Today
- Total
LITTLE BY LITTLE
[5-1]실전! 텐서플로2를 활용한 딥러닝 컴퓨터비전 - 객체 탐지 모델( YOLO, Faster R-CNN) 본문
2부. 전통적 인식 문제를 해결하는 최신 솔루션
04. 유력한 분류 도구 (고급 CNN아키텍처의 이해 - VGG, GoogleLeNet, Inception,ResNet[잔차 네트워크], 전이학습)
05. 객체 탐지 모델(YOLO, Faster R-CNN, 텐서플로 객체 탐지 API)
06. 이미지 보강 및 분할 (인코더-디코더로 이미지 변환, 노이즈 제거, 객체 분할)
3부. 컴퓨터 비전의 고급 개념 및 새 지평
07. 복합적이고 불충분한 데이터셋에서 훈련시키기 (입력 파이프라인, 데이터셋 보강, VAE와 GAN)
08. 동영상과 순환 신경망 (RNN, 장단기 메모리 셀, LSTM으로 동영상 분류하기)
09. 모델 최적화 및 모바일 기기 배포 (계산 및 디스크 용량 최적화, 온디바이스 머신러닝, MobileNet)
2-5. 객체 탐지 모델
- 한 이미지에서 객체와 그 경계 상자를 탐지
- 입력으로 이미지를 받고,
- 경계 상자와 객체 클래스 리스트 출력
- 각 경계 상자에 대해 그에 대응하는 예측 클래스와 해당 클래스의 신뢰도 출력
- 응용 분야
- 자율 주행 자동차에서 자동차,보행자 찾기
- 콘텐츠 조정을 위해 금지된 객체와 그 크기 찾기
- 의료분야에서 방사선 사진으로 종양,위험한 조직 찾을 때
- 제조업에서 조립 로봇이 제품 조립,수리할 때
- 야생관찰에서 동물 개체수 모니터링
- 객체 탐지 모델에서 모델 성능 평가 방법
- 경계 상자 정밀도 : 정확한 경계 상자를 제공하는지
- 재현율 : 모든 객체를 찾았는지
- 클래스 정밀도 : 객체마다 정확한 클래스를 출력했는지
- 정밀도(=양성 예측도)는 예측값이 TRUE 인 값 중 맞춘 정도
- 안정적이지 않은 특징을 기반으로 객체 존재를 예측하면, 아닌데 그냥 일단 다 맞다고 하게되면 예측값이 TRUE인 값이 늘어남(정밀도의 분모) => False Positive가 많아짐 => 정밀도(=양성 예측도)가 낮아짐
- 재현율(=TPR=민감도) 은 실제값이 TRUE 인 값 중 맞춘 정도
- 모델이 너무 엄격해서 웬만해서는 맞다고 하지 않는다면, 실제 값이 TRUE인 것을 맞출 확률이 매우 낮아질 것 => False Negative가 많아짐(실제는 true인데 false로 예측) => 재현율(=TPR=민감도)이 낮아짐
- 정밀도-재현율 곡선 : 임계값마다 모델의 정밀도와 재현율 시각화, 신뢰도가 낮은 예측은 유지할 필요가 없으므로 특정 임계값 T 이하의 예측은 제거한다.
- 임계값 T가 1에 가까우면(=모델이 엄격하면), 정밀도▲재현율(TPR)▼
- 임계값 T가 0에 가까우면(=모델이 엄격하지 않으면), 정밀도(양성예측도)▼재현율▲
- AP 와 mAP
- AP(평균 정밀도) : 정밀도-재현율 곡선 아래 영역
- AP는 단일 클래스에 대한 모델 성능정보 제공
- 전역 점수를 얻으려면 mAP(mean Average Precision)을 사용하면 된다. => 단일 이미지 중 여러 클래스를 평가하기 위함
- AP 임계값(=IoU[Intersection Over Union]) : 얼마나 일치해야 일치했다고 판단할지 '자카드 지표(Jaccard index)'를 메트릭으로 사용
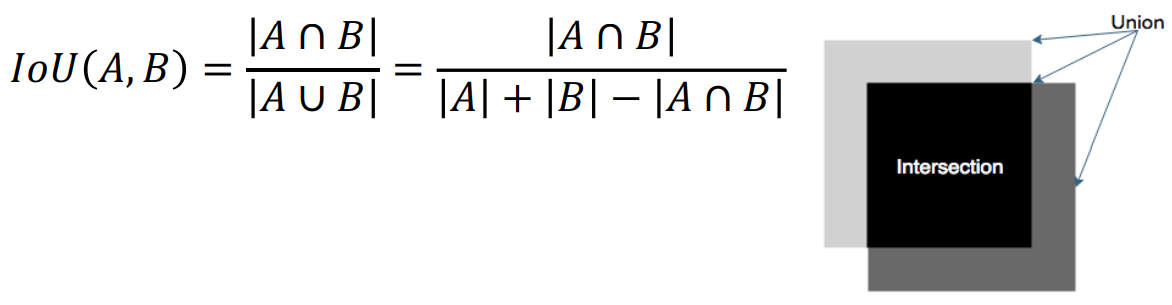
=> 교집합만 사용하지 않는 이유는
- 교집합은 절대적 수치일 뿐, 상대적이지 않기 때문
- 두 개의 큰 상자가 두 개의 작은 상자보다 훨씬 많은 픽셀이 잡힌다.(위 그림 참고)
- IoU는 항상 0과 1사이의 값을 가진다.
- AP를 계산할 때 IoU가 특정 임계값을 넘으면 두 상자가 겹쳐진다고 말한다.
- 일반적으로 IoU는 0.5로 정한다.
YOLO
- (+) 속도가 빠른 것으로 유명하다.
- (-) Faster R-CNN이 정확도 측면에서 YOLO를 능가한다.
- (-) 객체를 탐지하는 방식 때문에 작은 크기의 물건 탐지에서는 어려움을 겪음
- (-) 훈련 세트에서 너무 많이 벗어난 객체(ex. 모양,가로/세로 비율이 이례적)를 적절히 탐지하는 일에도 어려움을 겪음
- YOLO의 핵심 아이디어
- 객체 탐지를 위한 '단일 회귀 문제'로 재구성
- 단순히 w X h 그리드로 나눈다. (슬라이딩 윈도우나 다른 복잡한 기법 사용하지 X)
- YOLO로 추론하기
- 추론 : 입력을 받아 결과를 계산하는 절차를 의미 (=회귀문제에서의 예측)
- 훈련 : 모델의 가중치를 학습하는 절차
- 모델의 훈련 이전에 추론 사용 불가
- YOLO 백본
- YOLO의 계층 출력
- 앵커 박스 소개
- YOLO가 앵커 박스를 개선하는 방법
- 상자를 사후 처리하기
- NMS(Non-maximum suppression, 비최댓값 억제)
YOLO 백본
: 특징 추출기 : 마지막 계층에서 사용될 의미있는 특징을 이미지로부터 출력하는 역할을 함

- 백본의 마지막 계층은 크기가 w X h X D 인 특징 볼륨 출력 (width X height X depth)
- w X h 는 그리드의 크기
- D는 특징 볼륨의 깊이 (VGG-16 = 512)
- 그리드의 크기는 다음 두 요인에 따라 달라진다.
- 전체 특징 추출기의 보폭 : VGG-16의 보폭은 16으로, 출력된 특징 볼륨이 입력 이미지보다 16배 작다는 뜻
- 입력 이미지의 크기 : 특징 볼륨 크기는 이미지 크기에 비례하므로, 입력 크기가 작을 수록, 그리드 크기도↓
- YOLO의 마지막 계층은 크기가 1X1인 합성곱 필터로 구성됨
- YOLO의 계층 출력
- 경계 상자마다 (C+5)개의 숫자를 예측해야 한다.(C는 클래스 개수)
- 경계상자 관련 값들을 계산하기 위한 다음의 숫자를 예측해야한다.

앵커박스(=사전 정의된 상자, prior box)
- 앵커박스의 도입
- 앵커박스는 경계 상자의 좌표(x,y,w,h)를 직접 출력하지 않는 이유와 관련이 있다.
- 객체 크기가 다양해서 수많은 오차가 발생하기 때문
- 훈련 데이터셋의 객체가 대부분 크면, 네트워크는 w와 h가 매우 크다고 예측할 것
- 작은 객체에서 훈련된 모델을 사용할 때 이 네트워크는 대체로 실패할 것
- 이 문제를 해결하기 위해서 앵커박스가 도입되었다.
- 앵커박스는 네트워크를 훈련시키기 이전에 결정되는 일련의 경계상자 크기이다.
- 앵커 박스의 집합은 일반적으로 작고, 실제로 3~25 사이의 다양한 크기를 가짐
- 네트워크는 가장 근접한 앵커박스의 개선에 사용됨 - 앵커박스의 보정에 위의 t값들이(4개) 필요한 것
- 앵커박스의 크기는 데이터셋마다 다르기 때문에, 모델을 훈련시키기 전에 데이터를 분석하여 앵커 박스의 크기를 선택할 것을 권고하였다.
- YOLO가 앵커박스를 개선하는 방법
- 최종 경계 상자 좌표 계산 공식 YOLOv2를 이용한다.
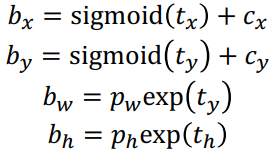

상자를 사후 처리하기
- 예측된 경계 상자의 좌표와 크기와 함께 신뢰도와 클래스 확률을 얻게 됨
- 신뢰도를 클래스 확률과 곱하고, 높은 확률만 유지하게 임계값 설정
ex.

=> filtered_scores가 0이 아닌 값을 포함한다. = 임계값으로 정한 0.3보다 큰 클래스가 최소 하나 있다는 의미
NMS(비최대값 억제, Non-maximum suppression)
- 객체가 여러 그리드 셀에 걸쳐 있어 한 번 이상 탐지되는 것을 보정하기 위함
- 사후 처리 파이프라인의 마지막 단계
- 확률이 가장 높은 상자와 겹치는 상자들을 제거
- 최대값을 갖지 않는 상자들을 제거
- 확률 기준 모든 상자 정렬, 먼저 가장 확률이 높은 상자를 취함
- 각 상자에 대해 다른 모든 상자와의 IoU를 계산함
- 특정 임계값(보통 0.5-0.9)을 넘는 상자를 제거
YOLO '추론' 과정 요약
1. 입력 이미지를 받아 CNN 백본을 사용해서 특징 볼륨 계산
2. 합성곱 계층으로 '앵커 박스' 보정, '객체성 점수' 계산, '클래스 확률' 계산
3. 이 출력으로 '경계 상자의 좌표' 계산
4. 임계값보다 낮은 상자를 걸러내고, 남은 상자는 비최대값 억제 기법을 사용하여 사후 처리

YOLO 백본 훈련 방법
- YOLO 모델 = [백본 + YOLO 헤드] <= 두 부분으로 구성
- 백본으로 사용될 수 있는 아키텍처는 많다.
- 전이학습 기법을 사용해 ImageNet의 도움으로 전형적인 분류 작업을 하도록 훈련
YOLO 손실
- YOLO에서 예측하는 정보
- 경계 상자 좌표의 크기
- 객체가 경계 상자 안에 있을 신뢰도
- 클래스에 대한 점수
- 손실이 부정확한 값에 패널티를 부과
- 단, 경계 상자에 아무 객체도 포함되어 있지 않으면, 사용되지 않기 때문에 패널티 부과해서는 X
경계 상자 손실
- 람다 : 손실에 가중치 부여
- 그리드 각 부분 i 에 대해 합계를 내고, 그리드의 이 부분에 포함된 각 상자 j에 대해 합계를 낸다.
- 1ijobj : 그리드의 i번째 부분의 j번째 경계 상자가 해당 객체를 탐지한다면 1이 되는 함수
- x, y, w, h : 경계 상자의 좌표와 크기
- 제곱근 : 크기가 작은 경계 상자에 대한 오차의 크기가 큰 경계 상자에 대한 오차보다 더 큰 패널티 부과
객체 신뢰도 손실
- Cij : 그리드의 i번째 부분에서 j번째 상자에 객체가 포함될 신뢰도
- 1noobj ij : 그리드의 i번째 부분에서 j번째 경계 상자에 객체가 탐지되지 않았을 때 1이 되는 함수
분류 손실
- 올바른 객체 클래스가 예측되도록 함
- 전체 YOLO 손실 = 3개 손실의 합
훈련 기법
- 데이터 보강 & 드롭 아웃 사용
- 다중-척도 훈련 : N개의 분기마다 다른 크기의 입력 사용 => 다양한 입력차원에서 정확히 예측하는 법을 학습
- 이미지 분류 작업에 대해 사전훈련이 되어있다.
- 번-인(BURN-IN) 사용 : 손실 폭발을 피하기 위해 훈련 초기에 학습률을 감소시킴
'4-2 > 이미지 딥러닝' 카테고리의 다른 글
'4-2/이미지 딥러닝' Related Articles
more




Comments