
- 분류 전체보기 (192)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- XGBoost
- 캐글 산탄데르 고객 만족 예측
- python
- 그로스 해킹
- pmdarima
- lightgbm
- 데이터 정합성
- tableau
- WITH CUBE
- 그로스 마케팅
- splitlines
- 부트 스트래핑
- 컨브넷
- 인프런
- 마케팅 보다는 취준 강연 같다(?)
- DENSE_RANK()
- 분석 패널
- ARIMA
- Growth hacking
- 그룹 연산
- 캐글 신용카드 사기 검출
- 3기가 마지막이라니..!
- 스태킹 앙상블
- 데이터 핸들링
- ImageDateGenerator
- WITH ROLLUP
- 로그 변환
- 데이터 증식
- 리프 중심 트리 분할
- sql
- Today
- Total
LITTLE BY LITTLE
[6]실전! 텐서플로2를 활용한 딥러닝 컴퓨터비전 - 객체 탐지 모델2 ( Faster R-CNN 이어서) 본문
Faster R-CNN
아키텍처 ( 두 단계로 작동)
- 관심 영역(ROI, Region of Interest) 추출 - 각 이미지에 대하여 약 2,000개의 ROI를 생성한다.
- 분류 단계(혹은 탐지 단계) - 2,000개 각각에 대해 합성곱 네트워크의 입력에 맞춰 정사각형으로 크기를 조정함
- 이 단계에서 CNN을 사용하여 ROI를 분류한다.
1단계. 영역 제안
- RPN (Region Proposal Network, 영역 제안 네트워크)를 사용하여 ROI를 생성한다.
- 합성곱 계층을 사용한다. (<= 속도가 빠름)
- 앵커 박스를 사용한다.
- 9개 크기의 앵커 박스 사용
- 세로로 긴 직사각형, 가로로 긴 직사각형, 정사각형 각각 3개씩
- 특징 볼륨을 생성하기 위해서 어떤 백본(=마지막 단계에서 사용되는 특징 추출기)이라도 사용 가능하다.
- 그리드를 사용한다. (크기는 특징 볼륨에 따라 달라짐)
- 마지막 계층은 숫자를 출력한다. (이 숫자를 사용하여 앵커 박스를 객체에 맞는 적절한 경계 상자로 정교화시킬 수 있다.)

1-1. 입력으로 이미지를 받아들이고, 여러 합성곱 계층을 적용한다.
1-2. 특징 볼륨을 출력한다. (합성곱 필터가 특징 볼륨에 적용된다.) : 필터 크기는 3X3XD, D는 특징볼륨의 depth
1-3. 특징 볼륨의 각 위치에서 중간 단계로 1xD 벡터를 생성한다.
1-4. 두 형제 1X1 합성곱 계층은 객체성 점수와 경계 상자 좌표를 계산한다
* K개의 경계 상자마다 두 개의 객체성 점수가 있으며, 앵커 박스의 좌표를 개선하기 위해 사용될 4개의 부동 소수점 수도 있다.
2단계. 분류
- 최종 경계 상자를 출력한다.
- 이전 단계의 ROI리스트와 입력 이미지에서 계산된 특징 볼륨을 두 개의 입력으로 받는다.
- 영역-제안 단계에서 계산된 특징맵을 재사용한다.
- 가중치 공유 : 다른 CNN을 사용하기 위하여 두 개의 백본에 대한 가중치를 저장
- 계산 공유 : 하나의 입력 이미지에 대해 두 개 대신 한 개의 특징 볼륨만 계산함으로써 계산 성능 향상
- 각 ROI에 대해 합성곱 계층이 적용되어 클래스 예측과 경계 상자 개선에 대한 정보를 얻는다.
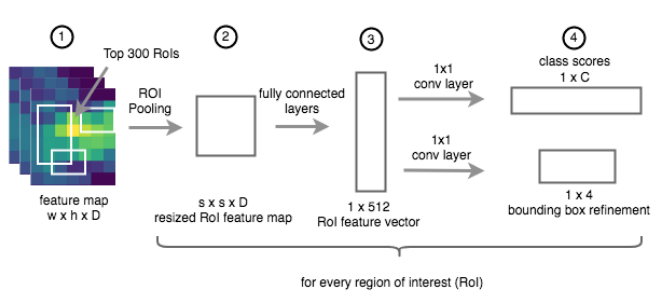
2-1. RPN(영역 제안)단계로부터 특징맵과 ROI를 받는다.
- 원본 이미지 좌표계로 생성된 ROI가 => 특징맵 좌표계로 전환됨
- 예제에서 CNN의 보폭은 16이다 => 좌표는 16으로 나누어진다.
2-2. 각 ROI크기를 조정해 완전 연결 계층의 입력과 맞춘다.
2-3. 완전 연결 계층을 적용하고, 여기에서 특징 벡터를 얻는다.
2-4. 두 개의 서로 다른 합성곱 계층을 적용한다. (하나는 분류 Classification을 처리하고, 다른 하나는 RoI 개선 Regression을 처리한다.)
위의 2-2 과정에서 사용된 관심 영역 풀링에 대해 알아보자.
관심 영역 풀링(ROI Pooling)
- 합성곱 네트워크가 모든 크기의 입력을 받을 수 있지만, 마지막의 완전 연결 계층은 입력으로 '고정된 크기의' 특징 볼륨을 받는다.
- 영역 제안의 크기가 다르기 때문에 마지막 계층을 그대로 사용할 수 없다.
- 이 문제를 피하기 위해 도입된 것이 관심 영역 풀링(RoI Pooling)기법이다.
- 다양한 크기의 특징맵 영역을 고정된 크기의 영역으로 전환시킨다.
- 크기가 조정된 특징 영역이 마지막 분류 계층에 전달될 수 있다.

=> 이런식으로 다양한 크기의 활성화 맵의 일부를 취하고, 이를 고정된 크기(max)로 변환하는 과정이다.
=> 최대-풀링 계층과 매우 유사하다. 차이점은 ROI풀링은 다양한 크기의 입력에 동작한다는 것
=> 입력 활성화 맵 하부 윈도우의 크기를 hXw, 목표 활성화 맵의 크기를 HXW라 한다.
=> 입력을 각 셀의 크기가 h/HXW/W인 그리드로 나눔으로써 동작한다.
=> ex. hXw = 5X4 , HXW = 2X2, h/HXw/W = 2.5 X 2
Faster R-CNN의 전체 아키텍처

- 네트워크의 두 부분이 각각 별도로 훈련됨
- 각 부분의 특징 추출기는 동일한 가중치를 공유하지 않음
- 대신에 공유하게 만드는 훈련 절차를 고안함
RPN(영역 제안) 훈련시키기
- 모든 제안 영역을 한번에 훈련시키기는 어렵다.
- 이미지의 대부분은 배경이라서, 대부분의 제안 영역은 '배경'을 예측하도록 훈련된다.
- 샘플링 기법을 선호한다.
- 256개의 실제 앵커 박스의 미니 배치가 구성되며, 128개는 양성, 128개는 음성이다.
- 여기서 양성은 객체를 포함한다는 사실을, 음성은 배경만 포함한다는 사실을 의미한다.
RPN 손실

- smoothL1 함수는 앞에서 사용했던 L2손실을 대체할 함수로 도입되었다.
- YOLO와 마찬가지로 pi*항 덕분에 객체를 포함한 앵커 박스에 대해서만 회귀 손실이 사용된다. 이 손실은 N(classification)과 N(regression) 두 부분으로 나뉘며, 이 두 값을 정규화 항이라고 한다. 미니 배치 크기를 바꾸더라도, 이 손실은 균형을 잃지 않을 것
- 람다는 밸런싱 매개변수이다. (논문 저자는 람다를 10으로 설정해 두 항의 전체 가중치를 동일하게 만듦)
- 요약하자면, RPN 손실은 YOLO 손실과 반대로 관심영역만 예측하기 대문에, 객체 클래스를 다루지 않는다. 손실과 미니 배치를 구성하는 방식을 제외하면 RPN은 여느 네트워크와 마찬가지로 역전파를 사용해 훈련된다.
R-CNN의 두 번째 단계를 Fast R-CNN 이라고도 한다.
Fast R-CNN 손실

- 근본적으로 RPN 손실과 유사하다.
- 훈련하는 동안 ID=0으로 설정해 항상 배경 클래스를 사용함
- 실제로 ROI가 배경 영역을 포함할 수 있고, 이를 배경으로 분류하는 일이 중요하다.
- 람다항은 배경 상자에 대해 경계 상자 오차에 패널티를 부과하는 것을 피한다.
훈련 계획(4-단계 교대 훈련)
- 네트워크 두 부분 사이 가중치를 공유해 모델이 빨라지고(=CNN이 한 번만 적용되기 때문) 가벼워짐
- 절차를 단순화하면
- RPN을 훈련해 허용할 만한 ROI 예측
- 훈련된 RPN의 출력(ROI)을 사용해 분류 파트를 별도로 훈련시킨다. (=> RPN과 분류 부분이 별도로 훈련되었기 때문에, 훈련이 끝나면 두 부분이 서로 다른 합성곱 가중치를 갖게 된다.)
- RPN의 CNN을 분류 부분의 CNN으로 교체, 합성곱 가중치를 공유하도록 만듦. => 공유한 CNN 가중치를 고정시키고 => RPN의 마지막 계층을 재훈련시킴
- 분류 부분의 마지막 계층을 RPN의 출력을 사용해서 다시 훈련한다.
- 위 절차가 끝나면, 합성곱 가중치를 공유하는 두 부분으로 이루어진 훈련된 네트워크를 얻게 된다.



