
- 분류 전체보기 (192)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 데이터 증식
- 데이터 정합성
- 3기가 마지막이라니..!
- WITH CUBE
- pmdarima
- ARIMA
- tableau
- 인프런
- ImageDateGenerator
- 데이터 핸들링
- 분석 패널
- XGBoost
- 캐글 신용카드 사기 검출
- splitlines
- WITH ROLLUP
- DENSE_RANK()
- 그로스 마케팅
- 스태킹 앙상블
- 캐글 산탄데르 고객 만족 예측
- 로그 변환
- 그룹 연산
- python
- 마케팅 보다는 취준 강연 같다(?)
- sql
- Growth hacking
- 컨브넷
- lightgbm
- 리프 중심 트리 분할
- 부트 스트래핑
- 그로스 해킹
- Today
- Total
LITTLE BY LITTLE
[2]실전! 텐서플로2를 활용한 딥러닝 컴퓨터비전 (CNN작업, 유효수용영역, 풀링계층, Lenet-5 구현) 본문
목차
1부. 컴퓨터 비전에 적용한 텐서플로2와 딥러닝
01. 컴퓨터 비전과 신경망
02. 텐서플로 기초와 모델 훈련 (케라스, 텐서보드, 애드온, 확장, 라이트, TensorFlow.js, 모델 실행 장소)
03. 현대 신경망 (다차원 데이터를 이용한 신경망, CNN작업, 유효수용영역, 훈련 프로세스 개선, 정규화 기법)
2부. 전통적 인식 문제를 해결하는 최신 솔루션
04. 유력한 분류 도구 (고급 CNN아키텍처의 이해 - VGG, GoogleLeNet, Inception,ResNet[잔차 네트워크], 전이학습)
05. 객체 탐지 모델 (YOLO, Faste R-CNN, 텐서플로 객체 탐지 API)
06. 이미지 보강 및 분할 (인코더-디코더로 이미지 변환, 노이즈 제거, 객체 분할)
3부. 컴퓨터 비전의 고급 개념 및 새 지평
07. 복합적이고 불충분한 데이터셋에서 훈련시키기 (입력 파이프라인, 데이터셋 보강, VAE와 GAN)
08. 동영상과 순환 신경망 (RNN, 장단기 메모리 셀, LSTM으로 동영상 분류하기)
09. 모델 최적화 및 모바일 기기 배포 (계산 및 디스크 용량 최적화, 온디바이스 머신러닝, MobileNet)
1-2. 텐서플로 기초와 모델 훈련
케라스를 사용한 간단한 컴퓨터 비전 모델
1) 데이터 준비
import tensorflow as tf
num_classes = 10
img_rows, img_cols = 28, 28
num_channels = 1
input_shape = (img_rows, img_cols, num_channels)
(x_train ,y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0=> 데이터를 임포트하고, 배열을 255.0으로 나눠 [0,255] 범위 내의 값을 [0,1] 범위내의 값으로 변환한다. 데이터를 정규화하는 대표적인 예로 보통 값을 [0,1]로 변환하거나, [-1,1]로 변환한다.
2) 모델 구성
- 두 개의 완전 연결 계층(=밀집 계층)으로 구성된 단순한 아키텍처 사용
- 계층을 선형으로 쌓아 구성하기 때문에 Sequential 함수를 호출한 후, 계층을 하나씩 차례로 추가한다.
- 평면화 계층(Flatten) : 이미지 픽셀을 표현하는 2차원 행렬을 취해서 1차원 배열로 전환한다.
- 완전 연결층을 추가하기 전에 이루어져야한다.
- 28 x 28 이미지는 784크기의 벡터로 변환된다.
- 크기가 128인 밀집 계층(Dense) : 이 계층의 784 픽셀 값을 128 x 784 크기의 가중치 행렬과 128 크기의 편향치 행렬을 사용해 128개의 활성화 값으로 전환한다.
- 전체 합치면 이는 100,480개의 매개변수를 의미
- 크기가 10인 밀집 계층 : 이 계층을 128개의 활성화 값을 최종 예측 값으로 전환한다. 확률의 합이 1이 되게 "소프트 맥스"활성화 함수 사용(분류 모델의 마지막 계층에서 사용되는 활성화 함수)
- model.summary() 사용시 모델의 설명,출력,가중치 확인 가능, 이 아키텍처 설정과 가중치가 초기화되면 모델은 주어진 작업을 위해 훈련받을 준비가 된 것
- 평면화 계층(Flatten) : 이미지 픽셀을 표현하는 2차원 행렬을 취해서 1차원 배열로 전환한다.
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation = 'relu' ))
model.add(tf.keras.layers.Dense(num_classes, activation = 'softmax'))3) 모델 훈련
생성한 모델의 .compile()을 호출하는 과정은 반드시 필요하다. 다음과 같은 인수가 지정되어야한다.
- Optimizer : 경사 하강법 수행 구성 요소
- sgd를 케라스에 전달한다는 것은 tk.keras.optimizers.SGD() 를 전달하는 것과 동일함
- Loss : 최적화해야할 metrcis, 여기서는 교차-엔트로피 손실함수 선택
- sparse_categorciaLcrossentropy와 categorical_crossentropy의 차이점은, 전자는 실제 레이블을 입력으로 직접 받는 반면에, 후자는 그 전에 실제 레이블을 원-핫 레이블로 인코딩되어 받음(수작업으로 레이블 변환할 필요X)
- Metrics : 훈련하는 동안 모델의 성능을 시각적으로 보여주기 위해 평가되는 추가적인 거리 함수(metric functions)
그 후에 .fit() 메소드를 호출한다.
model.compile(optimizer = 'sgd', loss= 'sparse_categorical_crossentropy', metrics=['accuracy'])
callbacks = [tf.keras.callbacks.TensorBoard('./keras')]
model.fit(x_train, y_train, epochs=25, verbose=1, validation_data = (x_test, y_test), callbacks=callbacks)[Out]
Epoch 25/25
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0883 - accuracy: 0.9763 - val_loss: 0.1031 - val_accuracy: 0.9709
<keras.callbacks.History at 0x7fa0264120d0>97.63%의 정확도를 얻었다.
텐서플로2와 케라스 자세히 알아보기
- 텐서플로 기본 구성요소인 Tensor 객체는 수치 값을 저장하기 위해 사용된다.
- Tensor 객체의 요소
- Type : string, float32, float16, int8 ..
- Shape : 데이터 차원, 예를 들어 형상이 ( ) 이면 스칼라, ( n ) 이면 크기가 n인 벡터, ( n, m )이면 크기가 nxm인 2차원 행렬
- 부분적으로 형상을 알 수 없는 텐서가 있을 수 있다.
- ex. (None, None, 3) => 다양한 크기의 이미지를 받는 모델, 높이와 너비는 알 수 없으나 채널 개수는 RGB에 대응하는 3으로 알고 있어 설정함
- Rank : 차원 개수, 0이면 스칼라, 1이면 벡터, 2이면 2차원 행렬
- Tensor 객체의 요소
- 텐서플로 그래프
- 텐서플로는 유향 비순환 그래프(DAB, directed acyclic graph)로 연산을 표현한다.
- 그래프 구성 : flatten => dense => dense_1
- 텐서플로는 파이썬 연산자를 오버로딩하기 때문에 tf.add(a,b) = a+b
- 케라스 모델과 계층
- Model 객체의 메소드와 속성
- .inputs, .outputs : 모델 입력과 출력에 접근
- .layers : 모델 계층과 형상 목록
- .summary : 모델 아키텍처 출력
- .save() : 훈련에서 모델, 아키텍처의 현 상태 저장, 후에 훈련 재개시 유용, 모델은 tf.keras.models.load_model()로 파일로부터 인스턴스화 될 수 있음
- .save_weights() : 모델의 가중치만 저장
- Model 객체의 메소드와 속성
- 콜백
- .fit() 메소드에 전달할 수 있는 유틸리티 함수
- CSVLogger : 훈련 정보를 csv파일에 로그로 남김
- EarlyStopping : 손실 혹은 메트릭이 더이상 개선되지 않으면 훈련 중지, 과적합 피할 때 유용
- LearningRateScheduler : 스케줄에 따라 세대마다 학습률 변경
- ReduceROnPlateau : 손실이나 메트릭이 더이상 개선되지 않으면 학습률을 자동으로 감소시킴
- tk.keras.callbacks.Callback의 서브클래스를 생성함으로써 맞춤형 콜백 생성 가능
- .fit() 메소드에 전달할 수 있는 유틸리티 함수
책에서 이어서 정리
1-3. 현대 신경망


- 완전 연결 네트워크의 문제점
- 매개변수의 폭발적인 증가
- RGB 이미지가 커지거나, 네트워크가 깊어질수록 매개변수 개수는 급격히 증가한다.
- 공간 추론의 부족
- 모든 픽셀 값이 계층별로 '원래 위치와 상관없이' 결합되므로, 픽셀 사이의 근접성 개념이 완전연결 계층(Fully-Connected) 계층에서 손실된다.
- 매개변수의 폭발적인 증가
- => CNN(컨브넷) 도입
- CNN
- 3차원 데이터를 입력으로 취하고, 뉴런을 그와 비슷한 볼륨으로 정렬
- 각 뉴런은 이전 계층에서 이웃한 영역에 속한 일부요소에만 접근
- 이 영역을 뉴런의 수용 영역(=필터 크기)라 함
- CNN 작업 - 합성곱 계층
- '다차원성'과 '지역적 연결성'을 효율적으로 활용
- N개의 다양한 뉴런의 집합을 갖는 합성곱 계층은 형상이 D x k x k 인 N개의 가중치 행렬(필터 또는 커널이라고도 함)과 N개의 편향값으로 정의됨
- 완전 연결 계층과 달리, 합성곱 계층에서는 데이터 차원이 매개변수 개수에 영향을 주지 않음
- 입력 이미지 크기가 커져도, 튜닝해야할 매개변수 개수에 영향 주지 X
- 합성곱 계층은 그 어떤 이미지에도 그 차원의 수와 관계없이 적용될 수 있음
- 훈련을 통해 합성곱 계층의 필터는 특정 '지역 특징'에 반응하는데 탁월해짐
- EX. 1번째 합성곱 계층에서는 커널마다 특정 저차원 특징(선의 방향, 색의 변화)에 활성화하기 위해 학습 시키고,
- 계층이 깊어질수록 그 결과를 사용해 얼굴 형태, 특정 객체의 윤곽과 같이 좀 더 추상적이고 발전된 특징의 위치를 찾음
- 각 필터는 특정 이미지의 특징에 그 위치와 상관없이 반응할 것
- 동일한 출력 채널에 연결된 모든 뉴런이 똑같은 가중치와 편향값을 공유함으로써 매개변수의 개수를 더 줄일 수 있다.
- 초매개변수로 계층의 출력 크기를 제어한다.
- 필터 개수 N
- 필터/커널 크기 k
- k는 커널의 앞 글자를 따온 것
- 일반적으로 수평 및 수직 보폭은 물론 수평 및 수직 패딩에도 동일한 값이 사용된다.
- 보폭(stride) s
- 보폭은 필터가 움직이는 정도
- 필터가 움직일 때 이미지 패치와 필터 사이의 내적을 위치마다 계산할지(stride=1) & s위치마다 계산할지(stride=s) 정의한다.
- 보폭이 커지면, 결과 특징 맵은 희소해진다.
- 패딩 값(=입력 주변에 추가할 빈 행과 열의 개수) p
- 이미지 크기를 원본 컨텐츠 주변에 0으로 된 행과 열을 추가해 인위적으로 키울 수 있다.
- 패딩은 필터가 이미지를 차지할 수 있는 '위치의 수'를 증가시킨다. 따라서 적용할 패딩 값(입력 주변에 추가할 빈 행과 열의 개수)을 지정할 수 있다.
- 위의 매개변수들은 계층 연산 뿐만 아니라, 계층의 출력 형상에도 영향을 준다.
- 초매개변수 조정은 객체 분할같은 애플리케이션, 즉 출력 분할 마스크가 입력 이미지와 동일한 크기를 갖기를 원할 때에 특히 편리하다.
- 텐서플로/케라스 메소드
- 이미지 합성곱의 경우 기본적으로 tf.nn.conv2d() 사용
- 주요 매개변수
- Input : 형상이 (B,H,W,D)인 입력 이미지의 배치 [B는 배치 크기]
- Filter : N개의 필터가 쌓여 형상이 (Kh, Kw, D, N)인 텐서가 됨
- Strides : 배치로 나눈 입력의 각 차원에 대한 보폭을 나타내는 4개의 정수 리스트
- 일반적으로 [1, Sh, Sw, 1] 사용 => 이미지 2개의 공간 차원에만 맞춤형stride 적용
- padding : 배치로 나눈 입력의 각 차원 전후에 붙이는 패딩을 나타내는 4x2개의 정수 리스트나 사전 정의된 패딩 중 무엇을 사용할지 정의하는, 'valid'나 'same'같은 문자열
- name : 이 연산을 식별하는 이름 (분명하고 가독성이 높은 그래프를 생성할 때 유용함)
- CNN
Discovering CNNs' Basic Operations
%matplotlib inline
!pip install scikit-image
!pip install matplotlib
import tensorflow as tf
import matplotlib
from matplotlib import pyplot as plt
from skimage import io #이미지 읽는 패키지image = io.imread("./res/bird_pic_by_benjamin_planche.png")print("Image shape: {}".format(image.shape))
plt.imshow(image, cmap=plt.cm.gray)Image shape: (680, 608)
Image shape: (680, 608)
이미지를 텐서플로우에 저장하기 위해 텐서 형태로 변환하기
image = tf.convert_to_tensor(image, tf.float32, name="input_image")데이터 로딩시 (Batch size, Height, Width, Channel)형태로 해야하므로 비슷한 형태의 차원 만들어주기
image = tf.expand_dims(image, axis=0)=> Expand tensor, adding a dimension at position 0
이미지의 채널 수(RGB)에 따라 마지막 텐서의 크기를 조절해주어야 하는데, 흑백이미지이므로 제일 마지막 Channel개수를 1로 설정하기
image = tf.expand_dims(image, axis=-1)
print("Tensor shape: {}".format(image.shape))[Out]
Tensor shape: (1, 680, 608, 1)Convolution

블러 처리(가우시안 블러)에 많이 사용되는 3x3 필터를 적용해보자
kernel = tf.constant([[1/16, 2/16, 1/16],
[2/16, 4/16, 2/16],
[1/16, 2/16, 1/16]], tf.float32, name="gaussian_kernel")
Convolution 방법을 사용하려면 텐서의 모양이 (k,k,D,N)이어야 한다. (정사각형 필터의 경우 크기는k,개수는N)
여기서는 D=1, N=1이지만 이러한 값을 명시적으로 표현하기 위해 커널을 재구성하여야 한다.
kernel = tf.expand_dims(tf.expand_dims(kernel, axis=-1), axis=-1)커널로 이미지 필터링을 진행하려면 tf.nn.Conv2d() 호출
blurred_image = tf.nn.conv2d(image, kernel, strides = [1,1,1,1], padding="SAME")결과물 바로 복구하기 (텐서플로2에서 가능)
blurred_res = blurred_image.numpy()
blurred_res = blurred_res[0, ..., 0]
plt.imshow(blurred_res, cmap=plt.cm.gray)=> 첫번째 이미지를 선택함으로써 Unbatch시켜줌, depth dimension도 삭제함

윤곽 검출(컨투어)을 설정해보자
kernel = tf.constant([-1, -1, -1],[-1,8,-1],[-1,-1,-1]],tf.float32, name="edge_kernel")
kernel = tf.expand_dims(tf.expand_dims(kernel, axis=-1), axis=-1)
실제 결과물에 미치는 영향을 자세히 보기위해 filter의 stride를 크게 설정
edge_image = tf.nn.conv2d(image, kernel, strides=[1,2,2,1], padding="SAME")
edge_res = edge_image.numpy()[0,...,0]
plt.imshow(edge_res, cmap=plt.cm.gray)[Out]

=> 이미지의 윤곽에 보이는 흰색 테두리를 없애주자.
=> 생긴 이유는 커널 필터에 의해 윤곽으로 감지된 zero padding(패딩 값을 same으로 설정함)때문
=> 실제로 image에 pad를 채우지 않으면 사라짐
edge_image = tf.nn.conv2d(image, kernel, strides=[1,2,2,1], padding="VALID")
edge_res = edge_image.numpy()[0, ...,0]
plt.imshow(edge_res, cmap=plt.cm.gray)[Out]

- 경우에 따라 0보다 더 복잡한 값으로 패딩해야할 경우, tf.pad() 메소드 사용 후 단순히 패딩으로 'VALID'를 사용하여 합성곱 연산을 인스턴스화한다.
- 그 외에도 1차원 데이터를 위한 tfnn
CNN 작업 - 풀링 계층(Pooling)
- CNN(컨브넷)과 일반적으로 함께 사용되는 계층 유형으로는 '풀링(pooling)'이 있다.
- 이 풀링 계층에는 훈련 가능한 매개변수가 없다. 각 뉴런은 자기 윈도우(수용 영역)의 값을 취하고 사전에 정의된 함수로 계산한 하나의 출력 반환
- 보편적으로 사용되는 2개 기법
- 최대 풀링 : 풀링된 영역의 깊이마다 최댓값만 반환
- 평균 풀링 : 풀링된 영역의 깊이마다 평균을 계산
- 보통 풀링 계층은 풀링 함수를 패치에 겹치지않게 적용하기 위해 '윈도우/커널 크기'와 동일한 크기와 보폭 값을 사용함 (=>데이터의 공간 차원을 줄여 매개변수 전체 개수, 계산 시간 단축, 즉 "패딩과 보폭 매개변수를 통해 결과 텐서의 차원을 제어")
- 훈련 가능한 커널이 없다는 점 빼고는 합성곱 계층과 비슷한 초매개변수를 가지고있어 데이터 차원을 제어하는 사용하기 쉬운 솔루션
- 텐서플로/케라스 메소드 tf.nn.max_pool() / tf.nn.avg_pool()
- value : (B,H,W,D)
- ksize : 차원별 윈도우 크기를 나타내는 4개의 정수 리스트, [1,k,k,1]을 일반적으로 사용
- strides : 보폭을 나타내는 4개의 정수 리스트, tf.nn.conv2d()와 유사
- padding : 사용할 알고리즘을 정의하는 문자열("VALID"또는 "SAME")
- name : 이 연산을 식별할 이름(명확하고 가독성 높은 그래프 생성에 유용)
avg_pooling 수행
avg_pooled_image = tf.nn.avg_pool(image, ksize=[1,2,2,1], strides=[1,2,2,1], padding="SAME")
avg_res = avg_pooled_image.numpy()[0,...,0]
plt.imshow(avg_res, cmap=plt.cm.gray)
=> 평균 풀링 수행 후 주어진 이미지의 dimension이 절반인 300으로 바뀐 것을 확인할 수 있다.
max_pooling 수행
max_pooled_image = tf.nn.max_pool(image, kszie=[1,10,10,1], strides=[1,2,2,1], padding="SAME")
max_res = max_pooled_image.numpy()[0,...,0]
plt.imshow(max_res, cmap=plt.dm.gray)
같은 결과 출력을 위해 더 높은 수준의 API를 사용해 간결하게 만들 수 있다.
avg_pool = tf.keras.layers.AvgPool2D(pool_size=k, strides=[s,s], padding='valid')
max_pool = tf.keras.layers.MaxPool2D(pool_size=k, strides=[s,s], padding='valid)CNN 작업 - 완전 연결 계층(FC)
- 완전 연결 계층 = Fully Conncted Layer = FC = 밀집 연결된 계층 = 밀집 계층
- CNN에서 일반 네트워크와 같은 방식으로 FC계층이 사용된다.
- CNN에서의 사용법
- 먼저 계층에 전달되는 입력 텐서를 단차원으로 평면화해야함 (flatten)
- 일반적으로 네트워크의 마지막 계층에서 사용 (ex.다차원 특징을 1차원 분류 벡터로 변환하기 위해 사용됨)
- (+) 공간적으로 거리가 먼 특징을 결합하기 위해 뉴런이 전체 입력 맵에 접근하는 것이 유리함
- (-) 앞서 언급했듯이, 공간 정보의 손실이나 매개변수가 많아진다는 단점
- (-) 다른 CNN계층과는 달리, 밀집 계층은 입력과 출력 크기에 의해 정의되기에, 다른 형상을 갖는 입력에는 동작하지 않아, 다양한 크기의 이미지에 적용되기 어려움
- 텐서플로/케라스 메소드
- 매개변수로 보폭이나 패딩은 받지 않음
- 대신에 뉴런/출력 크기의 개수를 나타내는 units를 받음
- 다차원 텐서를 밀집 계층에 전달하기 전에 평면화(flatten)해야한다는 사실 기억
fc = tf.keras.layers.Dense(units=output_size, activation='relu')유효 수용 영역(ERF, Effective Receptive Field)
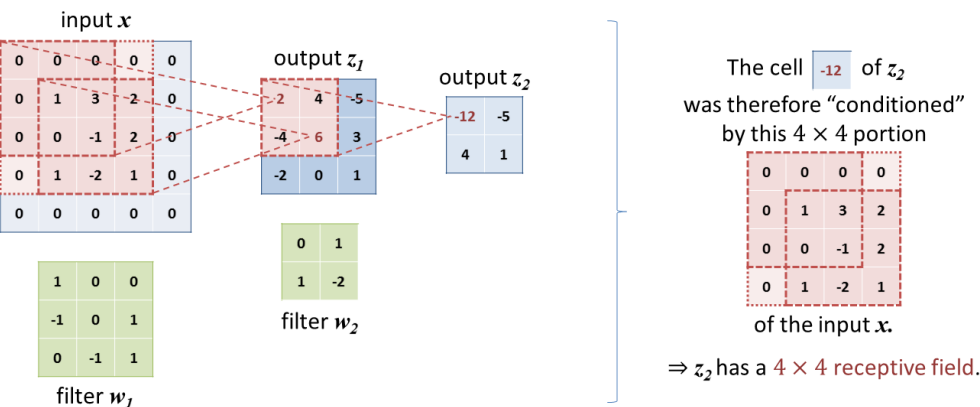
- 입력 이미지에서 거리가 먼 요소를 상호 참조
- 결합하는 네트워크 능력에 영향을 줄 수 있어 딥러닝에서 중요한 개념
- 수용 영역은 뉴런이 연결된 이 계층의 로컬 영역을 나타내지만, ERF는 '입력 이미지의 영역'을 정의해 주어진 계층을 위한 뉴런 활성화에 영향을 미친다.
텐서플로로 CNN 구현하기
첫 합성곱 신경망으로 LeNet-5 구현

num_classes = 10
img_rows, img_cols, img_ch = 28, 28, 1
input_shape = (img_rows, img_cols, img_ch)(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_trian = x_train.reshape(x_train.shape[0], *input_shape)
x_test = x_test.reshape(x_test.shape[0], *input_shape)Simple Convolution Layer 구현(▼)
class SimpleConvolutionLayer(tf.keras.layers.Layer):
def __init__(self, num_kernels=32, kernel_size=(3, 3), strides=(1, 1), use_bias=True):
"""
Initialize the layer.
:param num_kernels: Number of kernels for the convolution
:param kernel_size: Kernel size (H x W)
:param strides: Vertical and horizontal stride as list
:param use_bias: Flag to add a bias after covolution / before activation
"""
# First, we have to call the `Layer` super __init__(), as it initializes hidden mechanisms:
super().__init__()
# Then we assign the parameters:
self.num_kernels = num_kernels
self.kernel_size = kernel_size
self.strides = strides
self.use_bias = use_bias
def build(self, input_shape):
"""
Build the layer, initializing its parameters according to the input shape.
This function will be internally called the first time the layer is used, though
it can also be manually called.
:param input_shape: Input shape the layer will receive (e.g. B x H x W x C)
"""
# We are provided with the input shape here, so we know the number of input channels:
num_input_channels = input_shape[-1] # assuming shape format BHWC
# Now we know how the shape of the tensor representing the kernels should be:
kernels_shape = (*self.kernel_size, num_input_channels, self.num_kernels)
# For this example, we initialize the filters with values picked from a Glorot distribution:
glorot_uni_initializer = tf.initializers.GlorotUniform()
self.kernels = self.add_weight(name='kernels',
shape=kernels_shape,
initializer=glorot_uni_initializer,
trainable=True) # and we make the variable trainable.
if self.use_bias: # If bias should be added, we initialize its variable too:
self.bias = self.add_weight(name='bias',
shape=(self.num_kernels,),
initializer='random_normal', # e.g., using normal distribution.
trainable=True)
def call(self, inputs):
"""
Call the layer and perform its operations on the input tensors
:param inputs: Input tensor
:return: Output tensor
"""
# We perform the convolution:
z = tf.nn.conv2d(inputs, self.kernels, strides=[1, *self.strides, 1], padding='VALID')
if self.use_bias: # we add the bias if requested:
z = z + self.bias
# Finally, we apply the activation function (e.g. ReLU):
return tf.nn.relu(z)
def get_config(self):
"""
Helper function to define the layer and its parameters.
:return: Dictionary containing the layer's configuration
"""
return {'num_kernels': self.num_kernels,
'kernel_size': self.kernel_size,
'strides': self.strides,
'use_bias': self.use_bias}첫 합성곱 신경망 LeNet-5 구현 (▼)
from tensorflow.keras import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Denseclass LeNet5(Model):
def __init__(self, num_classes):
"""
Initialize the model.
:param num_classes: Number of classes to predict from
"""
super(LeNet5, self).__init__()
# We instantiate the various layers composing LeNet-5:
# self.conv1 = SimpleConvolutionLayer(6, kernel_size=(5, 5))
# self.conv2 = SimpleConvolutionLayer(16, kernel_size=(5, 5))
# ... or using the existing and (recommended) Conv2D class:
self.conv1 = Conv2D(6, kernel_size=(5, 5), padding='same', activation='relu')
self.conv2 = Conv2D(16, kernel_size=(5, 5), activation='relu')
self.max_pool = MaxPooling2D(pool_size=(2, 2))
self.flatten = Flatten()
self.dense1 = Dense(120, activation='relu')
self.dense2 = Dense(84, activation='relu')
self.dense3 = Dense(num_classes, activation='softmax')
def call(self, inputs):
"""
Call the layers and perform their operations on the input tensors
:param inputs: Input tensor
:return: Output tensor
"""
x = self.max_pool(self.conv1(inputs)) # 1st block
x = self.max_pool(self.conv2(x)) # 2nd block
x = self.flatten(x)
x = self.dense3(self.dense2(self.dense1(x))) # dense layers
return x이제 만들어진 Lenet-5 CNN으로 MNIST를 분류하는데 적용해보자
batched_input_shape = tf.TensorShape((None, *input_shape))
model.build(input_shape=batched_input_shape)
model.summary()[Out]
Model: "le_net5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 156
conv2d_1 (Conv2D) multiple 2416
max_pooling2d (MaxPooling2D multiple 0
)
flatten (Flatten) multiple 0
dense (Dense) multiple 48120
dense_1 (Dense) multiple 10164
dense_2 (Dense) multiple 850
=================================================================
Total params: 61,706
Trainable params: 61,706
Non-trainable params: 0
_________________________________________________________________컴파일
model = LeNet5(num_classes)
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics=['accuracy'])콜백 Early Stopping, TensorBoard
callbacks = [
tf.keras.callbacks.EarlyStopping(patience=5, monitor='val_loss'),
tf.keras.callbacks.TensorBoard(log_dir='./logs', histogram_freq=1, write_graph=True)]모델에 통과시켜 훈련하기(에러해결하기)
history = model.fit(x_train, y_train,
batch_size=32, epochs=80, validation_data=(x_test, y_test),
verbose=2, # change to `verbose=1` to get a progress bar
# (we opt for `verbose=2` here to reduce the log size)
callbacks=callbacks)다음 : 훈련 프로세스 개선(89p부터)



