
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 그룹 연산
- tableau
- 마케팅 보다는 취준 강연 같다(?)
- 로그 변환
- 3기가 마지막이라니..!
- python
- pmdarima
- XGBoost
- 부트 스트래핑
- 리프 중심 트리 분할
- 캐글 신용카드 사기 검출
- 그로스 마케팅
- DENSE_RANK()
- lightgbm
- 데이터 정합성
- 캐글 산탄데르 고객 만족 예측
- WITH CUBE
- 그로스 해킹
- 스태킹 앙상블
- sql
- 분석 패널
- 인프런
- splitlines
- ARIMA
- Growth hacking
- 데이터 핸들링
- 컨브넷
- WITH ROLLUP
- 데이터 증식
- ImageDateGenerator
- Today
- Total
LITTLE BY LITTLE
[12] 파이썬 머신러닝 완벽 가이드 - 6.차원 축소(6-2.PCA) / 7. 군집화(7-2.군집평가 : 실루엣 분석) 본문
[12] 파이썬 머신러닝 완벽 가이드 - 6.차원 축소(6-2.PCA) / 7. 군집화(7-2.군집평가 : 실루엣 분석)
위나 2022. 9. 16. 00:006. 차원 축소
- 차원 축소의 개요
- PCA (Principal Component Anlysis)
- LDA (Linear Discriminant Anlysis)
- SVD (Singular Value Decomposition)
- NMF (Non-Negative Matrix Factorization)
- 정리
7. 군집화
K-평균 알고리즘 이해- 군집 평가
- 평균 이동 (Mean shift)
- GMM(Gaussian Mixture Model)
- DBSCAN
- 군집화 실습 - 고객 세그먼테이션
- 정리
- 회귀
- 다항 회귀와 과(대)적합/과소적합 이해
- 규제 선형 모델 - 릿지, 라쏘, 엘라스틱 넷
- 로지스틱 회귀
- 회귀 트리
- 회귀 실습 - 자전거 대여 수요 예측
- 회귀 실습 - 캐글 주택 가격 : 고급 회귀 기법
- 정리
- 텍스트 분석
- 텍스트 분석 이해
- 텍스트 사전 준비 작업(텍스트 전처리) - 텍스트 정규화
- Bag of Words - BOW
- 텍스트 분류 실습 - 20 뉴스그룹 분류
- 감성 분석
- 토픽 모델링 - 20 뉴스그룹
- 문서 군집화 소개와 실습 (Opinion Review 데이터셋)
- 문서 유사도
- 한글 텍스트 처리 - 네이버 영화 평점 감성 분석
- 텍스트 분석 실습 - 캐글 mercari Price Suggestion Challenge
- 정리
- 추천 시스템
- 추천 시스템의 개요와 배경
- 콘텐츠 기반 필터링 추천 시스템
- 최근접 이웃 협업 필터링
- 잠재요인 협업 필터링
- 콘텐츠 기반 필터링 실습 - TMDV 5000 영화 데이터셋
- 아이템 기반 최근접 이웃 협업 필터링 실습
- 행렬 분해를 이용한 잠재요인 협업 필터링 실습
- 파이썬 추천 시스템 패키지 - Surprise
- 정리
6. 차원 축소
6-1. 차원 축소의 개요
- 대표적인 차원 축소 알고리즘 PCA , LDA, SVD, NMF에 대해 알아보자.
- 차원 축소란, 매우 많은 피처로 구성된 다차원 데이터셋의 차원을 축소해 새로운 차원의 데이터셋을 생성하는 것
- 차원 축소는 '피처가 많을 때의 문제점'을 해결
- 일반적으로 차원이 증가하면, 데이터 포인트 간의 거리가 멀어져 희소(Sparse)한 구조를 가지게됨
- 많은 피처로 구성된 데이터는 적은 차원에서 학습된 모델보다 예측 신뢰도가 떨어짐
- 또한, 피처가 많을 경우 개별 피처간의 상관관계가 높을 가능성이 크다.
- 선형회귀와 같은 선형 모델에서는 입력 변수 간의 상관관계가 높으면 다중 공선성 문제 발생 =>성능 저하
- 차원 축소의 또 다른 기능
- 시각적으로 데이터를 압축해서 표현함으로써 직관적으로 데이터를 해석할 수 있다.
- 학습 데이터의 크기가 줄어들어 학습에 필요한 처리 능력도 줄일 수 있다.
- 차원 축소는 크게 '피처 선택'과 '피처 추출'로 나뉜다.
- 피처 선택 : 말 그대로 특정 피처에 종속성이 강한 불필요한 피처는 아예 제거하고, 특징을 잘 나타내는 피처만 선택하는 것
- 피처 추출 : 기존 피처를 저차원의 중요 피처로 압축해서 추출하는 것, 새롭게 추출된 중요 특성은 기존의 피처와는 완전히 다른 값이 됨
- 단순 압축이 아니다. 피처를 함축적으로 더 잘 설명할 수 있는 또 다른 공간으로 매핑해 추출하는 것
- ex. 학생 평가요소인 [모의고사 성적, 내신 성적, 수능 성적, 봉사활동, 대외활동 등] 여러가지 피처로 되어있는 데이터셋이라면, 이를 '학업 성취도', '문제 해결력'과 같이 더 함축적인 요약 특성으로 추출 가능
- 이렇 듯 함축적인 특성 추출은 기존 피처가 전혀 인지하기 어려웠던 "잠재적인 요소"를 추출하는 것
- 차원 축소는 '이미지 예측'에도 쓰임
- 매우 많은 픽셀로 이루어진 이미지 데이터에서 잠재된 특성을 피처로 도출해 함축적 형태의 이미지 변환과 압축을 수행할 수 있다.
- 변환된 이미지는 원본 이미지보다 훨씬 적은 차원이기 때문에 이미지 분류 등 분류 수행시 과적합 영향력이 작아져 원본 데이터로 예측하는 것보다 성능이 좋음
- 이미지 자체가 가지고있는 차원 수가 커서, 비슷한 이미지라도 적은 픽셀의 차이가 잘못된 예측으로 이어질 수 있음. 따라서 이런 경우 차원축소가 예측 성능이 도움이 된다.
- 차원 축소는 텍스트 문서의 숨겨진 의미를 추출할 때에도 쓰임
- 차원 축소 알고리즘은 문서 내 단어들의 구성에서 숨겨져있는 Semantic 의미나 토픽을 잠재 요소로 간주하고 이를 찾아낼 수 있다.
- SVD와 NMF는 이러한 시맨틱 토픽 모델링을 위한 기반 알고리즘으로 사용된다.
- 차원 축소는 '피처가 많을 때의 문제점'을 해결
6-2. PCA (Principal Component Analysis)
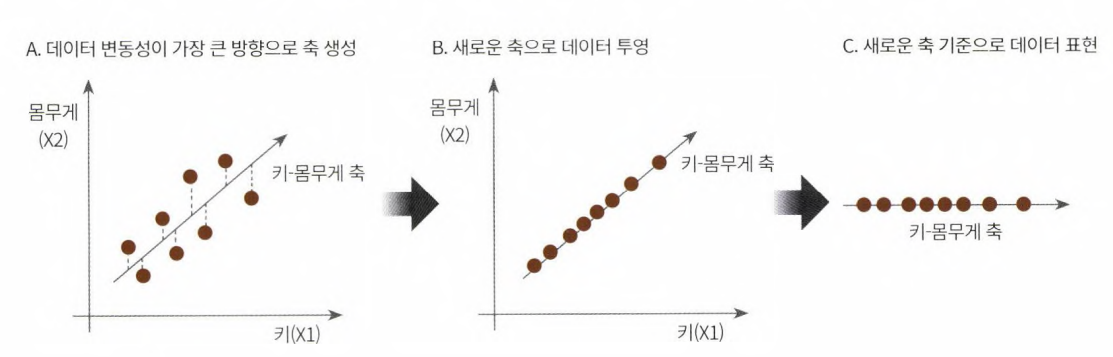
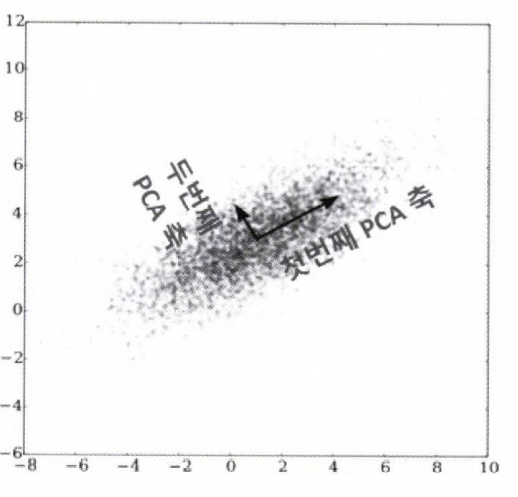
- PCA는 여러 변수 간에 존재하는 상관관계를 이용해 이를 대표하는 주성분을 추출해 차원을 축소하는 기법
- PCA로 차원을 축소할 때에는 기존 데이터의 정보 유실이 최소화되는 것이 당연함
- 이를 위해 PCA는 가장 높은 분산을 가지는 데이터의 축을 찾아 이 축으로 차원을 축소함, 이것이 PCA의 주성분이 된다.
- 즉, '분산'이 데이터의 특성을 가장 잘 나타내는 것으로 간주
- EX. 키와 몸무게 2개의 피처를 가지고 있는 데이터셋 (위 그림)
- 2개의 피처를 한 개의 주성분을 가진 데이터셋으로 차원 축소
- 데이터 변동성이 가장 큰 방향으로 '축'을 생성
- 새롭게 생성된 축으로 데이터를 투영하는 방식
- PCA는
- 제일 먼저 가장 큰 데이터 변동성(Varaince)을 기반으로 첫 번째 벡터 축을 생성,
- 두 번째축은 이 벡터 축에 직각이되는 벡터(직교 벡터)를 축으로 한다.
- 세 번째 축은 다시 두 번째 축과 직각이 되는 벡터를 설정하는 방식으로 축을 생성한다.
- 생성된 벡터 축에 원본 데이터를 투영하면 벡터 축의 개수만큼의 차원으로 원본 데이터가 축소된다.
- 보통 PCA는 다음과 같은 스텝으로 수행된다.(
자세한 수식 생략..)- 입력 데이터셋의 공분산 행렬 생성
- 공분산 행렬의 고유벡터와 고유값 계산
- 고유값이 가장 큰 순으로 K개(PCA변환 개수만큼)만큼 고유벡터 추출
- 고유값이 가장 큰 순으로 추출된 고유벡터를 이용해 새롭게 입력 데이터 변환
붓꽃 데이터로 실습
from sklearn.datasets import load_iris
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
iris = load_iris()# 넘파이 => 판다스 DF로 변환
columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
irisDF = pd.DataFrame(iris.data, columns=columns)
irisDF['target'] = iris.target
irisDF.head(3)[Out]

# 데이터 셋 분포를 보기위해 2차원으로 시각화
# setosa는 세모, versicolor는 네모, virginica는 동그라미
markers = ['^','s','o']
# setosa의 target 값은 0, versicolor는1, virginica는2, 각 타겟별로 다른 모양으로 산점도 표시
for i, marker in enumerate(markers):
x_axis_data = irisDF[irisDF['target'] ==i]['sepal_length']
y_axis_data = irisDF[irisDF['target']==i]['sepal_width']
plt.scatter(x_axis_data, y_axis_data, marker=marker, label=iris.target_names[i])
plt.legend()
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.show()[Out]
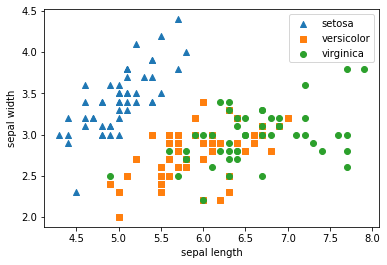
=> Setosa(파란색)는 width가 3보다 크고, length는 6이하인 곳에 일정하게 분포
=> Versicolor(주황색)와 virginica(초록색)의 경우, width와 length로는 분류가 어려운 조건임을 알 수 있다.
이제 PCA로 4개 속성을 2개로 압축한 뒤, 2개의 PCA 속성으로 붓꽃 데이터 품종 분포를 2차원으로 시각화해보자.
PCA 하기 전에 스케일링 (정규화)
# target 값 제외, 모든 속성을 정규화
from sklearn.preprocessing import StandardScaler
iris_scaled = StandardScaler().fit_transform(irisDF.iloc[ : , :-1])PCA
- sklearn.decomposition에서 import
- n_components를 인자로 받음
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
# fit()과 transform()을 호출해 pca 변환 데이터 반환
pca.fit(iris_scaled)
iris_pca = pca.transform(iris_scaled)
print(iris_pca.shape)[Out]
(150, 2)PCA 변환된 컬럼 명 지정
# PCA 변환된 데이터의 컬럼 명을 각각 pca_component_1, pca_component_2로 명명
pca_columns = ['pca_component_1', 'pca_component_2']
irisDF_pca = pd.DataFrame(iris_pca, columns=pca_columns)
irisDF_pca['target'] = iris.target
irisDF_pca.head(3)[Out]

# 다시 시각화
markers = ['^', 's', 'o']
# pca_component_1을 x축, pca_component_2를 y축으로 scatter plot 수행
for i, marker in enumerate(markers):
x_axis_data = irisDF_pca[irisDF_pca['target']==i]['pca_component_1']
y_axis_data = irisDF_pca[irisDF_pca['target']==i]['pca_component_2']
plt.scatter(x_axis_data, y_axis_data, marker=marker, label=iris.target_names[i])
plt.legend()
plt.xlabel('pca_component_1')
plt.ylabel('pca_component_2')
plt.show()[Out]
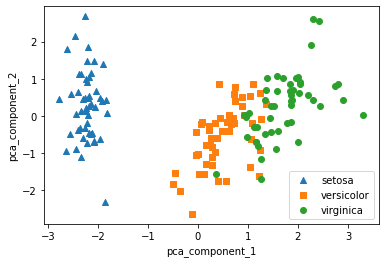
PCA 하기 전과 비교(▼)

=> PCA로 변환한 후에도 setosa(파란색)은 명확히 구분 가능
=> veriscolor과 virginica는 pca_component_1 축을 기반으로 겹치는 부분이 존재하긴 하지만, 비교적 잘 구분되었다.
=> 이는 PCA의 첫 번째 새로운 축인 pca_component_1이 원본 데이터의 변동성을 잘 반영했기 때문
PCA 컴포넌츠별로 차지하는 원본 데이터의 변동성 비율을 explained_variance_ratio_ 속성을 통해 알아보자
print(pca.explained_variance_ratio_)[Out]
[0.72962445 0.22850762]=> 첫 번째 pca 변환 요소인 pca_component_1이 전체 변동성의 약 72.9%를 차지한다.
=> 두 번째 pca_component_2가 약 22.8%차지
=> 따라서 PCA를 2개 요소로만 변환해도 원본데이터의 변동성을 약 95% 설명할 수 있다는 의미
이번에는 원본 붓꽃 데이터셋과 PCA로 변환된 데이터셋에 각각 분류를 적용한 후 결과를 비교해보자.
- Estimator는 RandomForestClassifier 이용
- cross_val_score()로 3개의 교차 검증세트로 정확도 결과 비교
# 원본 데이터에 랜덤 포레스트 적용
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
import numpy as np
rcf = RandomForestClassifier(random_state=156)
scores = cross_val_score(rcf, iris.data, iris.target, scoring='accuracy', cv=3)
print('원본 데이터 교차 검증 개별 정확도:', scores)
print('원본 데이터 평균 정확도:', np.mean(scores))# PCA 변환한 데이터셋에 랜덤 포레스트 적용
pca_X = irisDF_pca[['pca_component_1', 'pca_component_2']]
scores_pca = cross_val_score(rcf, pca_X, iris.target, scoring='accuracy', cv=3)
print('PCA 변환 데이터 교차 검증 개별 정확도:', scores_pca)
print('PCA 변환 데이터 평균 정확도:', np.mean(scores_pca))[Out]
원본 데이터 교차 검증 개별 정확도: [0.98 0.94 0.96]
원본 데이터 평균 정확도: 0.96
PCA 변환 데이터 교차 검증 개별 정확도: [0.88 0.88 0.88]
PCA 변환 데이터 평균 정확도: 0.88=> PCA 변환 차원 개수에 따라 예측 성능이 떨어질 수밖에 없다.
=> 10%의 정확도 하락은 비교적 큰 성능 수치의 감소지만,
=> 4개의 속성이 2개로, 속성 개수가 50% 감소한 것을 고려한다면, PCA 변환 후에도 원본 데이터의 특성을 상당 부분 유지하고 있음을 알 수 있다.
좀 더 많은 피처를 가진 데이터셋의 예측 영향도 변화를 살펴보자 (신용카드 고객 데이터 사용)
https://archive.ics.uci.edu/ml/ datasets/ default+of+credit+card+clients
https://archive.ics.uci.edu/ml/
archive.ics.uci.edu

* pd.read_excel에러 해결
> pip uninstall xlrd==1.1.0
> pip install xlrd==1.2.0
그 다음 런타임 재시작
or
> pip install openpyxl
import pandas as pd
# header로 의미없는 행 제거, iloc으로 기존 id 제거
df = pd.read_excel('/content/credit_card.xls',sheet_name='Data', header=1).iloc[0:, 1:]
print(df.shape)
df.head()[Out]
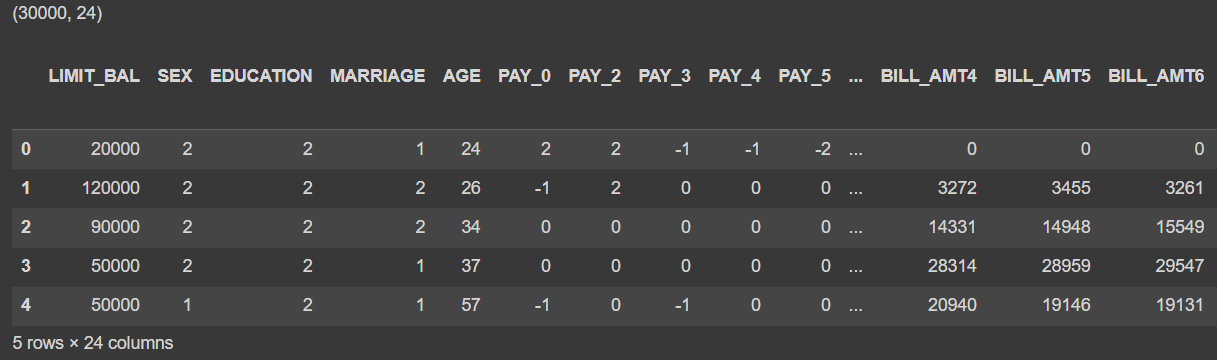
=> 신용 카드 데이터는 30,000개의 레코드와 24개의 속성을 가지고 있다.
=> default payment next month : 타깃 변수로, '다음 달 연체 여부'를 의미, 연체일경우 '1', 정상납부는 '0'
컬럼명이 길어서 default로 변경하고, y_target 변수로 저장하고, 피처 데이터에서 타깃 변수 제외한 별도의 df 만들기
df.rename(columns={'PAY_0':'PAY_1', 'default payment next month':'default'}, inplace=True)
y_target = df['default']
X_features = df.drop('default', axis=1)23개의 속성들 사이의 상관도가 매우 높다. 먼저 corr()으로 상관도를 구한 뒤 sns.heatmap으로 시각화해보자
# 상관도 시각화
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
corr = X_features.corr()
plt.figure(figsize=(14,14))
sns.heatmap(corr, annot=True, fmt='.1g')[Out]
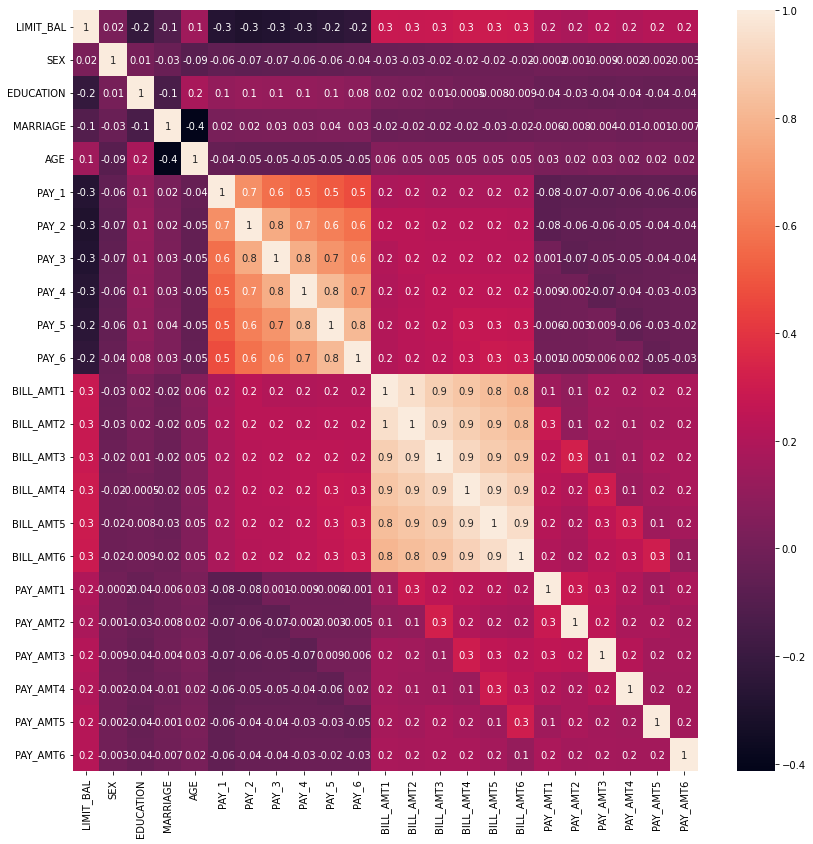
=> 색이 연할수록 상관도가 높은 것
=> Bill_amt 1부터 6까지 6개 속성끼리 상관도가 0.9이상으로 매우 높음
=> Pay_1 부터 6까지 6개 속성 역시 상관도가 높음
=> 이렇게 높은 상관도를 가진 속성들은 소수의 pca만으로도 자연스럽게 속성들의 변동성 수용 가능
위 12가지 속성을 2개 컴포넌트로 pca변환 뒤 변동성을 알아보자
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# BILL_AMT1 ~ BILL_AMT6 까지 6개 속성명 생성
cols_bill = ['BILL_AMT' + str(i) for i in range(1,7)]
print('대상 속성명:', cols_bill)# 2개의 PCA 속성을 가진 PCA 객체 생성하고, explained_variance_ratio_ 계산을 위해 fit() 호출
scaler = StandardScaler()
df_cols_scaled = scaler.fit_transform(X_features[cols_bill])
pca = PCA(n_components=2)
pca.fit(df_cols_scaled)
print('PCA Component별 변동성:', pca.explained_variance_ratio_)[Out]
대상 속성명: ['BILL_AMT1', 'BILL_AMT2', 'BILL_AMT3', 'BILL_AMT4', 'BILL_AMT5', 'BILL_AMT6']
PCA Component별 변동성: [0.90555253 0.0509867 ]=> 단 2개의 pca 컴포넌트만으로도 6개 속성의 변동성을 약 95%이상 설명할 수 있다.
=> 특히 첫 번째 pca 축으로 90%의 변동성을 수용할 정도로 6개 속성의 상관도가 매우 높다는 의미
이번에는 원본 데이터 셋과 PCA변환한 데이터셋 분류 예측 결과를 비교해보자
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
rcf = RandomForestClassifier(n_estimators=300, random_state=156)
scores = cross_val_score(rcf, X_features, y_target, scoring='accuracy', cv=3)
print('CV=3인 경우의 개별 Fold세트별 정확도:', scores)
print('평균 정확도:{0:.4f}'.format(np.mean(scores)))from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 원본 데이터셋에 먼저 StandardScaler 적용
scaler = StandardScaler()
df_scaled = scaler.fit_transform(X_features)
# 6개 컴포넌트를 가진 pca수행하고 cross_val_score()로 분류 예측 수행
pca = PCA(n_components=6)
df_pca = pca.fit_transform(df_cols_scaled)
scores_pca = cross_val_score(rcf, df_pca, y_target, scoring='accuracy', cv=3)[Out]
CV=3인 경우의 개별 Fold세트별 정확도: [0.8083 0.8196 0.8232]
평균 정확도:0.8170
CV=3인 경우의 PCA 변환된 개별 fold 세트별 정확도: [0.7752 0.7806 0.7789]
PCA 변환 데이터 세트 평균 정확도: 0.7782=> 원본 데이터에 비해 약 4%의 성능저하만 발생하였다. 4%의 예측 성능 저하는 미비한 성능 저하로 보기는 힘들지만, 전체 속성의 1/4정도로 이정도 예측 성능 유지는 pca의 뛰어난 압축능력을 보여준다.
=> PCA는 차원축소를 통해 데이터를 쉽게 인지하는데도 활용이 되지만, 더 활발히 적용되는 영역은 컴퓨터 비전분야이다. 특히 얼굴 인식의 경우 Eigen-face라고 불리는 pca변환으로 원본 얼굴 이미지를 변환해 사용하는 경우가 많다.
7. 군집화
7-2. 군집 평가(Cluster Evaluation)
- 앞서 붓꽃 데이터셋의 경우 (7-1) 결과값에 품종을 뜻하는 타깃 레이블이 있었고, 군집화 결과를 레이블과 비교하여 얼마나 군집화가 효율적으로 되었는지 짐작 가능하였다.
- 하지만 대부분의 군집화 데이터셋은 비교할만한 타깃 레이블을 갖고있지 않음
- 또한 군집화는 분류(Classification)과 유사해보일 수 있으나, 성격이 많이 다르다.
- 데이터 내에 숨어 있는 별도의 그룹을 찾아서 의미를 부여하거나 동일한 분류 값에 속하더라도 그 안에서 더 세분화된 군집화를 추구하거나, 서로 다른 분류 값의 데이터도 더 넓은 군집화 레벨화 등의 영역을 가지고 있다.
- 군집화가 효율적으로 되었는지 평가할 수 있는 방법인 '실루엣 분석'에 대해 알아보자. (비지도학습의 특성상, 정확한 성능 평가는 어려움)
실루엣 분석의 개요
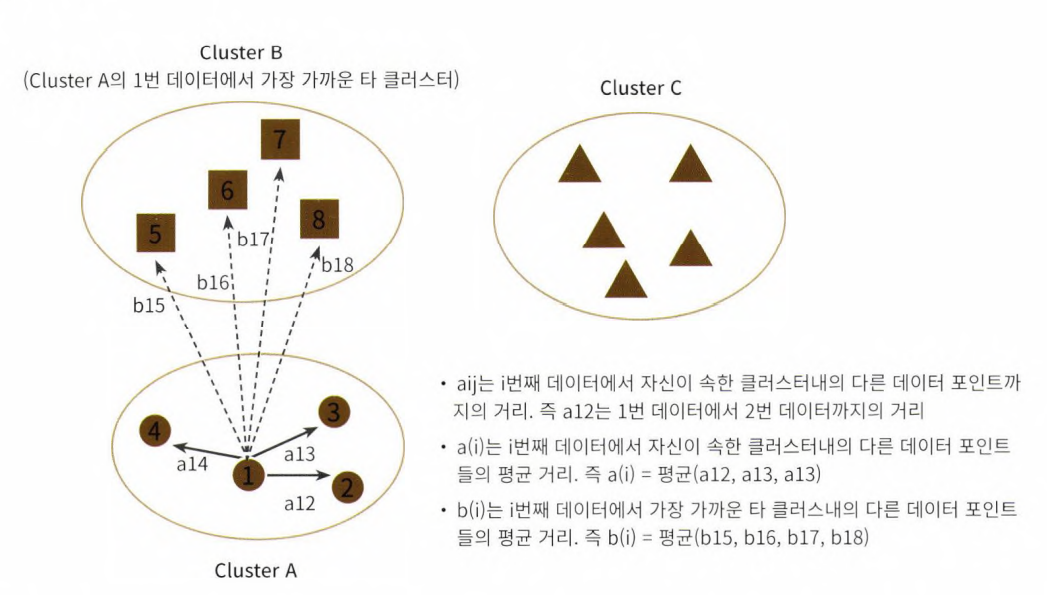
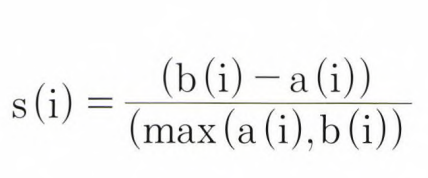
- 실루엣 분석은 각 군집간의 거리가 얼마나 효율적으로 분리되어 있는지를 나타낸다.
- '효율적으로 잘 분리되었다'의 의미 = '다른 군집과의 거리는 떨어져있고, 동일 군집 끼리의 데이터는 잘 뭉쳐있다.'
- 군집화가 잘 될수록 개별 군집은 비슷한 정도의 여유공간을 가지고 떨어져 있을 것
- 실루엣 계수 : 개별 데이터가 가지는 군집화 지표
- 개별 데이터가 가지는 실루엣 계수는 해당 데이터가 같은 군집 내의 데이터와 얼마나 가깝게 군집화 되어있고, 다른 군집의 데이터와는 얼마나 멀리 분리되어있는지 나타내는 지표
- -1에서 1 사이의 값을 가지며, 1로 가까워질수록 근처의 군집과 더 멀리 떨어져있다는 것이고, 0으로 가까워질수록 근처의 군집과 가까워진다는 뜻, -1 값은 아예 다른 군집에 데이터 포인트가 할당되었음을 의미
- 사이킷런 실루엣 분석 메소드
- sklearn.metrics.silhouette_samples(X, labels,metric='euclidean', **kwds)
- 인자로 X feature 데이터셋, 각 피처 데이터셋이 속한 군집 레이블 값인 labels 데이터 입력
- 각 데이터 포인트의 실루엣 계수 반환
- sklearn.metrics.silhouette_score(X, labels, metric='euclidean', sample_size=None, **kwds)
- 인자로 X feature 데이터셋, 각 피처 데이터셋이 속한 군집 레이블 값인 labels 데이터 입력
- 전체 데이터의 실루엣 계수 값을 평균해 반환
- 즉, np.mean(silhoouette_samples())이다.
- 일반적으로 이 값이 높을수록 군집화가 어느정도 잘 되었다고 판단할 수 있음 (절대적X)
- 좋은 군집화의 조건
- 전체 실루엣 계수의 평균값인 silhouette_score()의 값이 0~1사이의 값을 가짐, 1에 가까울 수록 좋음
- 하지만 개별 군집의 평균값의 편차가 크지 않아야 한다.
- 즉, 개별 군집의 실루엣 계수 평균값이 전체 실루엣 계수의 평균 값에서 크게 벗어나지 않아야함
- sklearn.metrics.silhouette_samples(X, labels,metric='euclidean', **kwds)
붓꽃 데이터셋을 이용한 군집 평가
from sklearn.preprocessing import scale
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
# 실루엣 분석 평가 지표 값을 구하기 위한 API 추가
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline
iris = load_iris()
feature_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
irisDF = pd.DataFrame(data=iris.data, columns=feature_names)
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=300, random_state=0).fit(irisDF)
irisDF['cluster'] = kmeans.labels_
# iris의 모든 개별 데이터의 실루엣 계수 값을 구함
score_samples = silhouette_samples(iris.data, irisDF['cluster'])
print('silhouette_samples() return 값의 shape', score_samples.shape)
# irisDF에 실루엣 계수 칼럼 추가
irisDF['silhouette_coeff'] = score_samples
# 모든 데이터의 평균 실루엣 계수 값을 구함
average_score = silhouette_score(iris.data, irisDF['cluster'])
print('붓꽃 데이터 셋 Silhouette Analysis Score:{0:.3f}'.format(average_score))
irisDF.head()[Out]
silhouette_samples() return 값의 shape (150,)
붓꽃 데이터 셋 Silhouette Analysis Score:0.553
=> 평균 실루엣 계수 값이 약 0.553이다.
=> 1번 군집의 경우, 0.8이상의 높은 실루엣 계수 값을 나타냄 => 평균에 비해 많이 높음 => 다른 실루엣 계수값이 평균보다 낮기 때문
group by로 군집별 평균 실루엣 계수 값을 알아보자
irisDF.groupby('cluster')['silhouette_coeff'].mean()[Out]
cluster
0 0.417320
1 0.798140
2 0.451105
Name: silhouette_coeff, dtype: float64=> 1번 군집은 0.79인데 반해, 0번은 약 0.41, 2번은 0.45으로 상대적으로 평균값이 1번에 비해 낮다.
군집별 평균 실루엣 계수의 시각화를 통한 군집 개수 최적화 방법

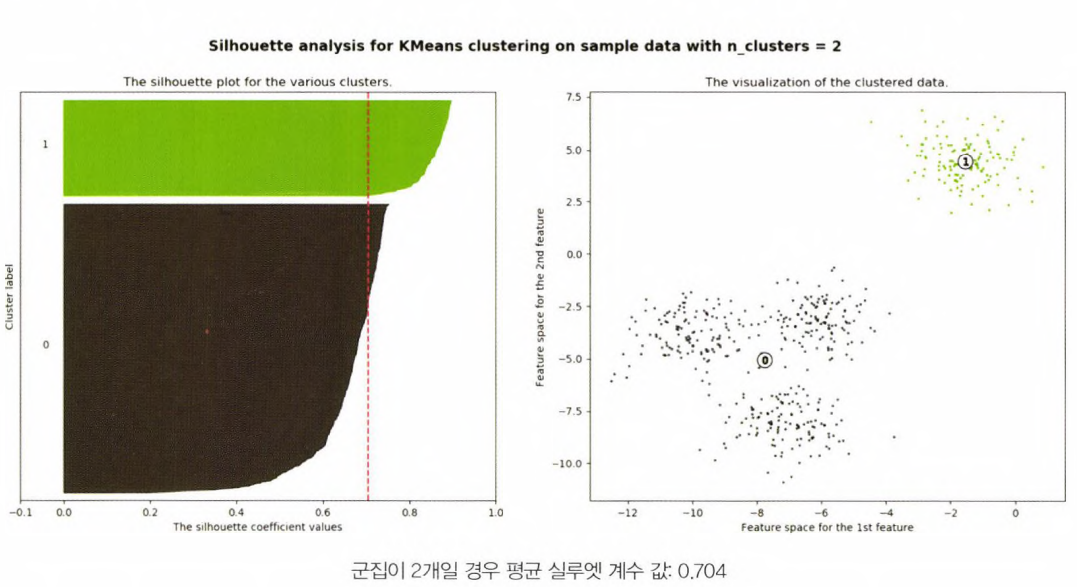

- 평균 실루엣 계수로 군집 개수를 최적화하는 방법에 대해 알아보자.
- 첫 번째 경우는 위의 그림1과 같이 주어진 데이터에 대해 군집개수 2개로 정했을 때
- 이때 평균 실루엣 계수 silhouette_score는 약 0.704로 매우 높게 나타남
- 하지만 최적이 아님 => 1번 군집의 모든 데이터는 평균 실루엣 계수값 이상이지만, 0번 군집의 경우는 평균보다 적은 데이터 값이 매우 많음
- 두 번째 경우는 위의 그림2와 같이 데이터에 대해 군집개수 3개로 정했을 때
- 전체 데이터의 평균 실루엣 계수 값은 약 0.588
- 1,2번 군집의 경우 평균보다 높은 실루엣 계수 값을 갖고있지만, 0번은 모두 평균보다 낮다.
- 0번의 경우 내부 데이터간의 거리도 멀지만, 2번 군집과도 가깝게 위치하고있기 때문
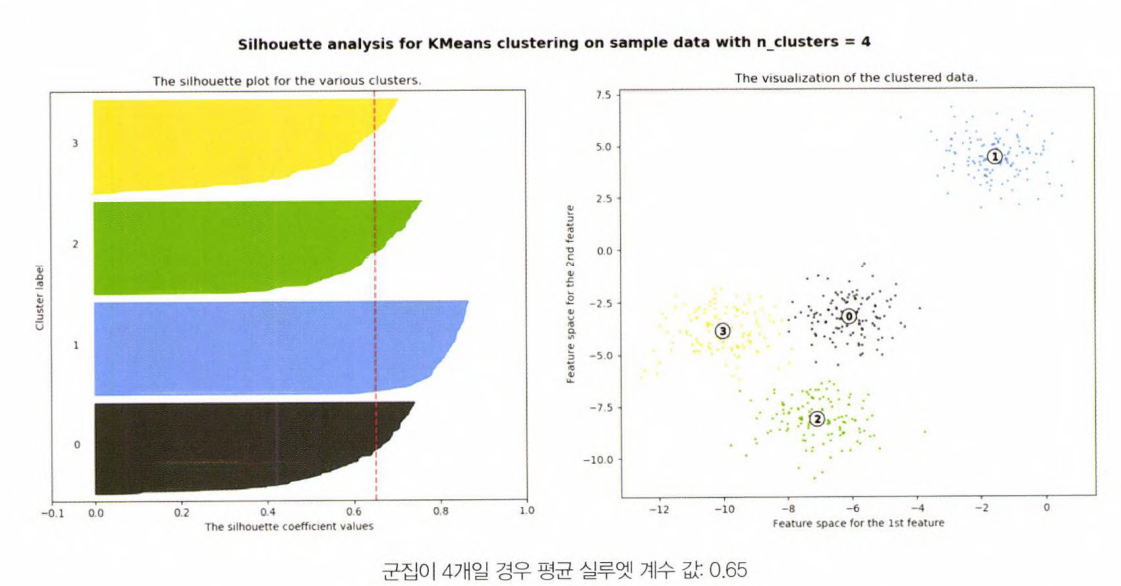
- 세 번째 경우는 위의 그림3과 같이 데이터에 대해 군집개수 4개로 정했을 때
- 전체 데이터의 평균 실루엣 계수 값은 약 0.65
- 왼쪽 그림에서 보듯이 개별 군집의 평균 실루엣 계수 값이 비교적 균일하게 위치하고 있다.
- 1번 군집의 경우 모든 데이터가 평균보다 높은 계수 값을 가지고 있다.
- 0번,2번의 경우 절반이상이 평균보다 높은 계수값을, 3번 군집의 경우만 약 1/3정도가 평균보다 높은 계수값을 갖고 있음
- =>따라서 군집이 2개인 경우보다 평균 실루엣 계수 값은 더 낮지만 4개인경우가 가장 이상적이라 판단 가능
- 첫 번째 경우는 위의 그림1과 같이 주어진 데이터에 대해 군집개수 2개로 정했을 때
Visualize_silhouette()로 평균 실루엣 계수 값을 시각화하여 군집 개수를 정할 때 사용
*함수 정의 참고
### 여러개의 클러스터링 갯수를 List로 입력 받아 각각의 실루엣 계수를 면적으로 시각화한 함수 작성 def visualize_silhouette(cluster_lists, X_features): from sklearn.datasets import make_blobs from sklearn.cluster import KMeans from sklearn.metrics import silhouette_samples, silhouette_score import matplotlib.pyplot as plt import matplotlib.cm as cm import math # 입력값으로 클러스터링 갯수들을 리스트로 받아서, 각 갯수별로 클러스터링을 적용하고 실루엣 개수를 구함 n_cols = len(cluster_lists) # plt.subplots()으로 리스트에 기재된 클러스터링 수만큼의 sub figures를 가지는 axs 생성 fig, axs = plt.subplots(figsize=(4*n_cols, 4), nrows=1, ncols=n_cols) # 리스트에 기재된 클러스터링 갯수들을 차례로 iteration 수행하면서 실루엣 개수 시각화 for ind, n_cluster in enumerate(cluster_lists): # KMeans 클러스터링 수행하고, 실루엣 스코어와 개별 데이터의 실루엣 값 계산. clusterer = KMeans(n_clusters = n_cluster, max_iter=500, random_state=0) cluster_labels = clusterer.fit_predict(X_features) sil_avg = silhouette_score(X_features, cluster_labels) sil_values = silhouette_samples(X_features, cluster_labels) y_lower = 10 axs[ind].set_title('Number of Cluster : '+ str(n_cluster)+'\n' \ 'Silhouette Score :' + str(round(sil_avg,3)) ) axs[ind].set_xlabel("The silhouette coefficient values") axs[ind].set_ylabel("Cluster label") axs[ind].set_xlim([-0.1, 1]) axs[ind].set_ylim([0, len(X_features) + (n_cluster + 1) * 10]) axs[ind].set_yticks([]) # Clear the yaxis labels / ticks axs[ind].set_xticks([0, 0.2, 0.4, 0.6, 0.8, 1]) # 클러스터링 갯수별로 fill_betweenx( )형태의 막대 그래프 표현. for i in range(n_cluster): ith_cluster_sil_values = sil_values[cluster_labels==i] ith_cluster_sil_values.sort() size_cluster_i = ith_cluster_sil_values.shape[0] y_upper = y_lower + size_cluster_i color = cm.nipy_spectral(float(i) / n_cluster) axs[ind].fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_sil_values, \ facecolor=color, edgecolor=color, alpha=0.7) axs[ind].text(-0.05, y_lower + 0.5 * size_cluster_i, str(i)) y_lower = y_upper + 10 axs[ind].axvline(x=sil_avg, color="red", linestyle="--")
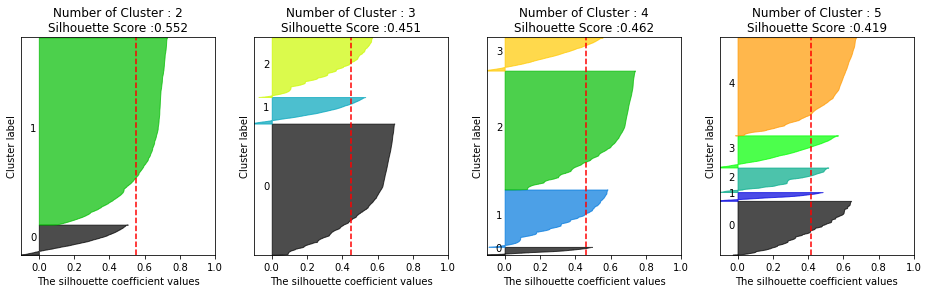
피처 데이터셋 X_features에 대해서 군집이 2,3,4,5개일 때의 군집별 평균 실루엣 계수 값 시각화
visualize_silhouette([2,3,4,5], X_features)[Out]
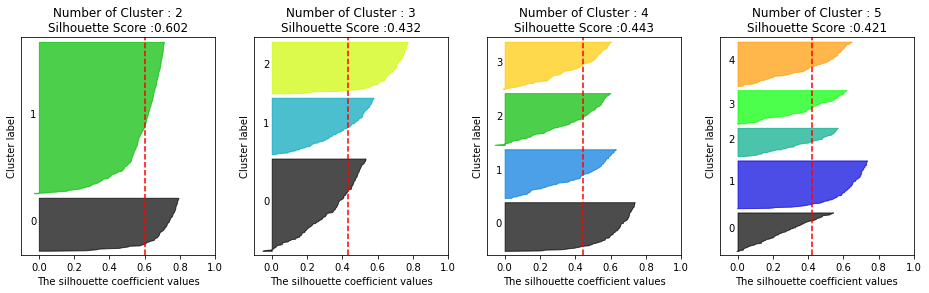
이번에는 make_blobs() 함수를 통해 4개 군집 중심의 500개 2차원 데이터셋을 만들고 k-평균으로 군집화할때, 2,3,4,5개 중 최적의 군집 개수를 시각화로 알아보자.
# make_blob를 통해 군집화를 위한 4개의 군집 중심의 500개 2차원 데이터셋 생성
from sklearn.datasets import make_blobs
X,y = make_blobs(n_samples=500, n_features=2, centers=4, cluster_std=1,
center_box=(-10,0,10,0),shuffle=True, random_state=1)
# 군집 개수가 2개, 3개, 4개, 5개일 때의 군집별 실루엣 계수 평균값을 시각화
visualize_silhouette([2,3,4,5],X)[Out]
from sklearn.datasets import load_iris
iris = load_iris()
visualize_silhouette([2,3,4,5],iris.data)[Out]
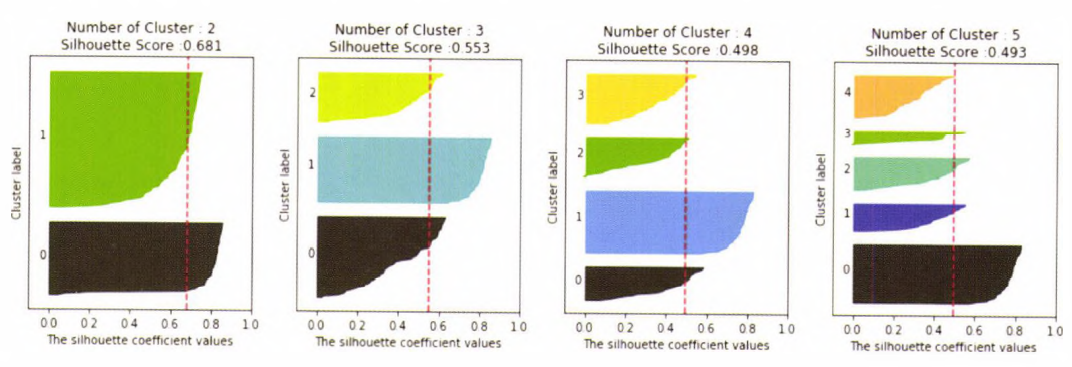
이번에는 붓꽃 데이터를 이용해 k-평균 수행시 최적의 군집 개수를 알아보자.
from sklearn.datasets import load_iris
iris = load_iris()
visualize_silhouette([2,3,4,5],iris.data)[Out]

1. PCA는 비슷한 피처가 많이 존재 (ex. bill_1, bill_2, bill_3...)할 때 하나로 묶어 다중공선성 방지
=> 따라서 주로 피처의 개수가 많을 때 사용
2. corr()로 피처의 상관도 파악 후에 상관도가 높은 피처가 많이 존재할 경우 사용
3. 군집분석은 분류와 비슷한 문제이나, 동일한 분류값 안에서 더 세분화된 군집화를 추구할 때 사용
4. 군집분석은 비지도학습이라 정확한 평가가 어려움 - 실루엣 분석



