
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 분석 패널
- 3기가 마지막이라니..!
- 데이터 핸들링
- splitlines
- WITH CUBE
- python
- sql
- WITH ROLLUP
- 그로스 마케팅
- 캐글 신용카드 사기 검출
- 그로스 해킹
- 부트 스트래핑
- 그룹 연산
- ARIMA
- 리프 중심 트리 분할
- 인프런
- Growth hacking
- 로그 변환
- tableau
- pmdarima
- 컨브넷
- 데이터 증식
- 데이터 정합성
- lightgbm
- ImageDateGenerator
- DENSE_RANK()
- 캐글 산탄데르 고객 만족 예측
- 마케팅 보다는 취준 강연 같다(?)
- XGBoost
- 스태킹 앙상블
- Today
- Total
LITTLE BY LITTLE
[3] 케라스 창시자에게 배우는 딥러닝 - 신경망 시작하기(분류/예측 예제 풀어보기) 본문
제 3부. 신경망 시작하기
- 신경망의 구조
- 케라스 소개
- 딥러닝 컴퓨터 셋팅
- 영화 리뷰 분류 : 이진 분류 예제
- 뉴스 기사 분류 : 다중 분류 예제
- 주택 가격 예측 : 회귀 문제
- 요약
목차
제 4부. 머신러닝의 기본 요소
- 머신러닝의 네 가지 분류
- 머신러닝 모델 평가
- 데이터 전처리, 특성 공학, 특성 학습
- 과대적합과 과소적합
- 보편적인 머신러닝 작업 흐름
- 요약
제 5부.컴퓨터 비전을 위한 딥러닝
- 합성곱 신경망 소개
- 소규모 데이터셋에서 밑바닥부터 컨브넷 훈련하기
- 사전 훈련된 컨브넷 사용하기
- 컨브넷 학습 시각화
- 요약
제 6부. 텍스트와 시퀀스를 위한 딥러닝
- 텍스트 데이터 다루기
- 순환 신경망 이해하기
- 순환 신경망의 고급 사용법
- 컨브넷을 사용한 시퀀스 처리
- 요약
제 7부. 딥러닝을 위한 고급 도구
- Sequential 모델을 넘어서 : 케라스의 함수형 API
- 케라스 콜백과 텐서보드를 사용한 딥러닝 모델 검사와 모니터링
- 모델의 성능을 최대화로 끌어올리기
- 요약
제 8부. 생성 모델을 위한 딥러닝
- LSTM으로 텍스트 생성하기
- 딥드림
- 뉴럴 스타일 트랜스퍼
- 변이형 오토인코더를 사용한 이미지 생성
- 적대적 생성 신경망 소개
- 요약
제 9부. 결론
- 핵심 개념 리뷰
- 딥러닝의 한계
- 딥러닝의 미래
- 빠른 변화에 뒤처지지 않기
- 맺음말
제 3부. 신경망 시작하기
3-1. 신경망의 구조
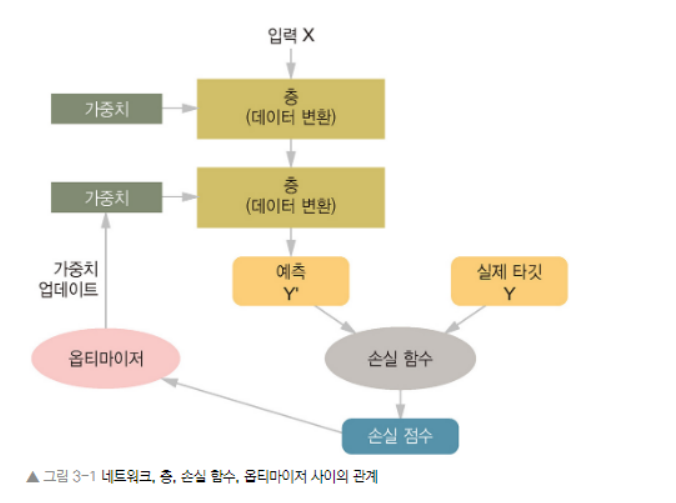
- 신경망 훈련에는 다음 요소들이 관련되어 있다.
- 네트워크(또는 모델)를 구성하는 층
- 입력 데이터와 그에 상응하는 타깃
- 학습에 사용될 피드백 신호를 정의하는 손실 함수
- 학습 진행 방식을 결정하는 옵티마이저
- 위 그림은 이들간의 상호작용을 나타낸다.
- 연속된 층으로 구성된 네트워크가 입력 데이터를 예측으로 매핑한다.
- 손실함수는 예측과 타깃을 비교하여 네트워크 예측이 기댓값이 얼마나 잘 맞는지를 측정하는 손실 값을 만듦
- 옵티마이저는 손실값을 사용하여 네트워크 가중치 업데이트
3.1.1. 층 : 딥러닝의 구성 단위
- 신경망의 핵심 데이터 구조로, 하나 이상의 텐서를 입력으로 받아 하나 이상의 텐서를 출력하는 데이터 처리 모듈
- 층이 없어도, 가중치라는 층의 상태를 가진다. 가중치는 확률적 경사 하강법에 의해 학습되는 하나 이상의 텐서로, 여기에 네트워크가 학습한 지식이 담겨있다.
- 층마다 적절한 텐서 포맷과 데이터 처리 방식이 다르다.
- (samples, features) 크기의 2D텐서가 저장된 간단한 벡터 데이터는 1)완전 연결층 , 2)밀집 (연결)층에 의해 처리되는 경우가 많음. (케라스에서는 Dense 클래스)
- (samples, timesteps, features) 크기의 3D텐서로 저장된 시퀀스 데이터는 보통 LSTM 같은 순환 층에 의해 처리된다.
- 4D 텐서로 저장되어 있는 이미지 데이터는 일반적으로 2D 합성곱 층에 의해 처리된다.
- 케라스에서는 호환 가능한 층을 엮어 데이터 변환 파이프라인을 구성함으로써 딥러닝 모델을 만든다.
- 여기에서 층 호환성은 각 층이 특정 크기의 입력 텐서만 받고, 특정 크기의 출력 텐서를 반환한다는 사실을 의미
from keras import layers
layer = layers.Dense(32,input_shape = (784, )) # 32개 유닛으로 밀집된 층- 첫번째 차원이 784인 2D 텐서만 입력으로 받는 층을 만들었다. (배치 차원인 0번째 축은 지정하지않아서, 어떤 배치 크기도 입력을 받을 수 있다.)
- 이 층을 차원크기가 32로 변환된 텐서를 출력할 것이다.
- 따라서 이 층에는 32차원의 벡터를 입력으로 받는 하위 층이 연결되어야 한다.
- 케라스에서는 모델에 추가된 층을 자동으로 상위층의 크기에 맞추기 때문에 호환성은 걱정하지 않아도된다.
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32,input_shape=(784, )))
model.add(layers.Dense(10))- 두번째 층에서는 input_shape 매개변수를 지정하지 않았다.그 대신, 앞선 층의 출력 크기를 입력크기로 자동 채택함
3.1.2. 모델 : 층의 네트워크
- 딥러닝 모델은 층으로 만든 비순환 유향 그래프 ( Directed Acyclic Graph, DAG) 이다. 가장 일반적인 예가 하나의 입력을 하나의 출력으로 매핑하는 층을 순서대로 쌓는 것
- 자주 등장하는 네트워크 구조
- 가지(branch)가 2개인 네트워크
- 출력이 여러개인 네트워크
- 인셉션 블록
- 네트워크 구조는 '가설 공간' 정의.
- 앞서 설명했듯이, 머신러닝은 '가능성 있는 공간을 사전에 정의하고, 피드백 신호의 도움을 받아, 입력 데이터에 대한 유용한 변환을 찾는 것'
- 네트워크 구조를 선택함으로써 가능성있는 공간(=가설 공간)을 입력데이터에서 출력 데이터로 매핑하는 일련의 특정 텐서 연산으로 제한하게 된다. 우리가 찾아야할 것은 이런 텐서연산에 포함된 가중치 텐서의 좋은 값
3.1.3. 손실 함수와 옵티아미저 : 학습 과정을 조절하는 열쇠
- 네트워크 구조 조정 후, 두가지를 더 선택해야한다.
- 손실함수(=목적 함수) : 훈련하는 동안 최소화될 값, 성공 지표
- 옵티마이저 : 손실함수를 기반으로 네트워크가 어떻게 업데이트될지 결정, 특정 종류의 확률적 경사 하강법(SGD) 구현
- 여러개의 출력을 내는 신경망은 여러개의 손실함수를 가질 수 있지만, 경사 하강법 과정은 하나의 스칼라 손실값을 기준으로 함. 따라서, 손실이 여러개인 네트워크에서는 모든 손실이 평균을 내서 하나의 스칼라 양으로 합쳐짐
- 문제에 맞는 올바른 목적 함수를 선택하는 것이 중요 (네트워크가 손실을 최소화하기 위해 편법을 사용할 수 있기 때문)
- ex. '모든 인류의 평균 행복지수를 최대화하기'와 같은 잘못된 목적함수에서 SGD로 훈련된 멍청하지만 전지전능한 AI가 있다고 가정했을 때, 이 문제를 쉽게 해결하려고 이 AI가 몇 사람을 남기고 모든 인류를 죽여서 남은 사람의 행복에 초점을 맞출 수도 있다. 평균 행복은 얼마나 많은 사람이 남겨져있는지와 상관없기 때문
- 모든 신경망은 단지 손실 함수를 최소화하기만 한다. 목적함수를 현명하게 선택해야한다.
- 올바른 손실함수를 선택하는 간단한 지침
- 2개의 클래스가 있는 분류 문제 - 크로스 엔트로피(binary crossentropy)
- 여러개의 클래스가 있는 분류 문제 - 범주형 크로스 엔트로피(categorical crossentropy)
- 회귀 문제 - 평균 제곱 오차
- 시퀀스 학습 문제 - CTC(Connection Temporal Classification)
- 완전히 새로운 연구할시에만 독자적인 목적 함수를 만들게 된다.
3-2. 케라스 소개
- 케라스는 거의 모든 종류의 딥러닝 모델을 간편하게 만들고 훈련시킬 수 있는 파이썬을 위한 딥러닝 프레임워크이다.
- 케라스의 특징
- 동일한 코드로 CPU와 GPU에서 실행 가능
- 사용하기 쉬운 API를 가지고 있어 딥러닝 모델의 프로토타입을 빠르게 만들 수 있다.
- (컴퓨터 비전을 위한) 합성곱 신경망, (시퀀스 처리를 위한) 순환 신경망을 지원하며 이 둘을 자유롭게 조합하여 사용 가능
- 다중 입력이나 다중 출력 모델, 층의 공유, 모델 공유 등 어떤 네트워크 구조도 만들 수 있다. 즉, 적대적 생성 신경망 (Generative Adversarial Network, GAN)부터 뉴럴 튜링 머신(Neural Turing Machine)까지 케라스는 기본적으로 어떤 딥러닝 모델에서 적합함
3.2.1. 케라스, 텐서플로, 씨아노, CNTK
- 케라스
- 케라스는 딥러닝 모델을 만들기 위한 고수준의 구성 요소를 제공하는 모델 수준의 라이브러리이다.
- 텐서 조작이나 미분 같은 저수준의 연산을 다루지 않는다.
- 그 대신 케라스의 백엔드 엔진에서 제공하는 최적화되고 특화된 텐서 라이브러리를 사용한다.
- 하나의 텐서 라이브러리에 국한되어 구현되어있지 않고, 모듈 구조로 구성

- 텐서플로, CNTK, 씨아노는 딥러닝을 위한 주요 플랫폼이다.
- 케라스로 작성한 모든 코드는 아무 변경없이 이런 백엔드 중 하나를 선택해서 실행시킬 수 있다.
- 개발하는 중간에 하나의 백엔드가 특정 작업에 더 빠르다고 판단되면 언제든지 백엔드를 바꿀 수 있어 유용
- 가장 널리 사용되고, 확장성이 뛰어나며 상용 제품에 쓸 수 있기 때문에 대부분의 딥러닝 작업에 텐서플로 백엔드고 기본으로 권장됨
- 위 3가지를 사용하기 때문에, 케라스는 CPU와 GPU에서도 작동 가능
- CPU에서 실행될 때 텐서플로는 Eigen이라 불리는 저수준 텐서 연산 라이브러리 이용
- GPU에서는 NVIDIA CUDA 심층 신경망 라이브러리(cuDNN)라고 불리는 고도의 최적화된 딥러닝 연산 라이브러리 이용
3.2.2. 케라스를 사용한 개발 - 빠르게 둘러보기
- 앞서 MNIST예제처럼 전형적인 케라스 작업흐름은 아래와 같다.
- 입력 텐서와 타깃 텐서로 이루어진 훈련 데이터를 정의한다.
- 입력과 타깃을 매핑하는 층으로 이루어진 네트워크(또는 모델)를 정의한다.
- 손실 함수, 옵티마이저, 모니터링하기 위한 측정 지표를 선택하여 학습과정을 설정한다.
- 훈련 데이터에 대해 모델의 fit() 메소드를 반복적으로 호출한다.
- 2가지 모델 정의 방법
- Sequential 클래스 (가장 자주 사용)
- 함수형 api (임의의 구조를 만들 수 있는 비순환 유향 그래프를 만듦)
# Sequential 클래스를 사용하여 정의한 2개의 층으로된 모델
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32,activation='relu',input_shape=(784,))) #첫번째 층에 입력 데이터의 크기가 전달된 점에 주목
model.add(layers.Dense(10,activation='softmax'))
# 위와 같은 모델을 함수형 API를 사용하여 만들어보자.
input_tensor = layers.Input(shape=(784,))
x = layers.Dense(32,activation = 'relu')(input_tensor) #함수형 API사용시, 모델이 처리할 데이터 텐서를 만들고
output_tensor = layers.Dense(10,activation='softmax')(x)
model = models.Model( inputs=input_tensor ,outputs=output_tensor) #마치 함수처럼 이 텐서에 층을 적용- 모델 구조가 정의된 후에는 Sequential 모델을 사용했는지, 함수형 api를 사용했는지 상관없다. 이후 단계는 동일함
- 컴파일 단계에서 학습과정이 설정된다. 여기에서 모델이 사용할 옵티마이저와 손실 함수, 훈련하는 동안 모니터링하기 위해 필요한 측정 지표를 지정한다.
손실함수를 사용하는 가장 흔한 경우의 예
from keras import optimizers
model.compile(optimizer = optimizers.RMSprop(lr=0.0001),
loss = 'mse',
metrics=['accuracy'])- 마지막으로 입력 데이터의 넘파이 배열을 (그리고 이에 상응하는 타깃 데이터를) 모델의 fit() 메소드에 전달함으로써 학습 과정이 이루어진다. 이는 사이킷런이나 다른 머신 러닝 라이브러리에서 하는 방식과 비슷함
model.fit(input_tensor, target_tensor, batch_size = 128, epochs=10)
3-4. 영화 리뷰 분류 : 이진 분류 예제
3.4.1. IMDB 데이터셋
- 인터넷 영화 데이터베이스로부터 가져온 양극단의 리뷰 5만개로 이루어져있다.
- 훈련 데이터 2만 5,000개, 테스트 데이터 2만 5,000개로 나뉘어 있고, 50%는 긍정, 50%는 부정리뷰이다.
- 이 데이터는 전처리되어 있어 각 리뷰(단어 시퀀스)가 숫자 시퀀스로 변환되어있다. 각 숫자는 사전에있는 고유한 단어를 나타냄
from keras.datasets import imdb
(train_data, train_labels), (test_data, trest_labels) = imdb.load_data(num_words=10000)- num_words=10000 매개변수는 훈련 데이터에서 가장 자주 나타나는 단어 1만개만 사용하겠다는 의미이다.
- 변수 train_data와 test_data는 리뷰의 목록이다. 각 리뷰는 단어 인덱스의 리스트이다.(인코딩된 단어 시퀀스)
- train_labels와 test_labels는 부정을 나타내는 0과, 긍정을 나타내는 1의 리스트
train_data[0]
# [1,14,22,15, ... 178, 32]
train_lables[0]
# 1max([max(sequence) for sequence in train_data])
# 9999- 가장 자주 등장하는 단어 1만개로 제한했기 때문에, 단어 인덱스는 9,999를 넘지 않는다.
리뷰 데이터 하나를 원래 영어 단어로 어떻게 바꾸는지 보자.
word_index = imdb.get_word_index() # word_index는 단어와 정수 인덱스를 매핑한 딕셔너리
# 정수 인덱스와 단어를 매핑하도록 뒤집기
reverse_word_index = dict([(value,key) for (key,value) in word_index.items()])
# 리뷰 디코딩하기. 0,1,2는 '패딩', '문서 시작', '사전에 없음'을 위한 인덱스이므로 3을 뺀 것
decoded_review = ' '.join([reverse_word_index.get(i-3,'?') for i in tran_data[0]])* dict.get(key, default=None) : get() 메소드의 리턴값은 key값 (딕셔너리에서)
* 인코딩 (encoding): 문자열을 바이트로 변환하는 과정 / 디코딩 (decoding) : 바이트를 문자열로 변환하는 과정
[바이트(byte) 컴퓨터 기본 저장단위]
3.4.2 데이터 준비
- 신경망에 숫자 리스트를 주입할 수는 없기 때문에, 리스트를 텐서로 바꿔야한다. 두가지 방법이 있다.
- 같은 길이가 되도록 리스트에 패딩(padding)을 추가하고, (samples, sequence_length) 크기의 정수 텐서로 반환한다. 그 다음, 이 정수 텐서를 다룰 수 있는 층을 신경망의 첫번째 층으로 사용한다.(=embedding 층)
- 리스트를 원-핫 인코딩하여 0과 1의 벡터로 변환한다. 예를 들어 시퀀스 [3,5]를 인덱스 3과 5의 위치는 1이고, 그 외에는 모두 0인 10,000차원의 벡터로 각각 변환한다. 그 다음, 부동 소수 벡터 데이터를 다룰 수 있는 Dense 층을 신경망의 첫번째 층으로 사용한다.
위에서 두번째 방식을 사용해서 신경망에 주입할 숫자리스트를 텐서로 바꿔보자. (정수 시퀀스를 이진 행렬로 인코딩하기)
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
# results = 크기가 (len(sequences),dimension)이고 모든 원소가 0인 행렬
results = np.zeros((len(sequences),dimension))
for i, sequence in enumerate(sequences):
results[i,sequence] = 1. # result[i]에서 특정 인덱스크기를 1로 만들기
return results #for문하고 indent 맞추는 것 주의
x_train = vectorize_sequences(train_data) # 훈련 데이터를 벡터로 변환
x_test = vectorize_sequences(test_data) # 테스트 데이터를 벡터로 변환* enumerate() : 인덱스(index)와 원소를 동시에 접근하면서 루프를 돌리기 위해서 파이썬의 내장 함수인 enumerate()를 이용하면 되는데, for 문의 in 뒷 부분을 enumerate() 함수로 한 번 감싸주기만 하면 된다.
(예시)
>>> for entry in enumerate(['A', 'B', 'C']):
... print(entry)
...
(0, 'A')
(1, 'B')
(2, 'C')* 그리고 enumerate() 함수는 기본적으로 인덱스와 원소로 이루어진 튜플(tuple)을 만들어준다. 따라서 인덱스와 원소를 각각 다른 변수에 할당하고 싶다면 인자 풀기(unpacking)를 해줘야함
*시작 인덱스 변경
루프를 돌리다보면 인덱스를 0이 아니라, 1로 시작하고 싶을 때가 있다. 이럴 때는 enumerate() 함수를 호출할 때 start 인자에 시작하고 싶은 숫자를 넘기면 된다.
>>> for i, letter in enumerate(['A', 'B', 'C'], start=1):
... print(i, letter)
...
1 A
2 B
3 C* enumerate() 원리
- 파이썬에서 for 문은 내부적으로 in 뒤에 오는 목록을 대상으로 계속해서 next() 함수를 호출하고 있다고 생각할 수 있다. 따라서, 일반 리스트를 iter() 함수에 넘겨 반복자(iterator)로 만든 후 next() 함수를 호출해보면 원소들이 차례로 얻어지는 것을 알 수 있다.
- 결국, enumerate() 함수는 인자로 넘어온 목록을 기준으로 인덱스와 원소를 차례대로 접근하게 해주는 반복자(iterator) 객체를 반환해주는 함수이다.
이제 샘플은 다음과 같이 나타난다.
x_train[0]
# array([0., 1., 1., ..., 0., 0., 0.])
# 레이블(y)은 쉽게 벡터로 바꿀 수 있다.
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')3.4.3 신경망 모델 만들기
- 입력 데이터가 벡터고, 레이블은 스칼라(1또는0)이다. 간단한 문제에 잘 작동하는 네트워크 종류는 relu 활성화 함수를 사용한 완전 연결층 (즉, Dense(16,activation='relu'))을 그냥 쌓은 것이다.
- Dense층에 전달한 매개변수(16)는 온닉 유닛의 개수이다.
- 은닉 유닛(hidden unit)은 '층이 나타내는 표현 공간에서 하나의 차원'이 된다.
- 하지만 은닉 유닛은 층이 나타내는 표현 공간에서 하나의 차원이 된다.
- Dense층에 전달한 매개변수(16)는 온닉 유닛의 개수이다.
앞서 2장에서 우리는 relu 활성화 함수를 사용한 Dense 층을 다음 텐서 연산을 연결하여 구현헀다.
output = relu(dot(W,input)+b)- " 16개의 은닉 유닛이 있다 "는 것은 가중치 행렬 W의 크기가 (input_dimension,16)이라는 뜻이다.
- 입력 데이터와 W를 점곱하면, 입력 데이터가 16차원으로 표현된 공간으로 투영된다. (그리고 편향 벡터 b를 더하고, relu 연산 적용)
- 표현 공간의 차원이란? - '신경망이 내재된 표현을 학습할 때 가질 수 있는 자유도'
- 즉, 은닉 유닛을 늘리면 (= 표현 공간을 더 고차원으로 만들면) 신경망이 더욱 복잡한 표현을 학습할 수 있지만, 계산 비용이 커지고, 원치않는 패턴을 학습할 수도있다.
- 훈련 데이터에서는 성능이 향상되지만, 테스트 데이터에서는 그렇지 않은 패턴이다.
- 표현 공간의 차원이란? - '신경망이 내재된 표현을 학습할 때 가질 수 있는 자유도'
- Dense 층을 쌓을 때 2가지 구조상의 결정이 필요
- 얼마나 많은 층을 사용할지 - (일반적) 16개의 은닉 유닛을 가진 2개의 은닉 층
- 각 층에 얼마나 많은 은닉 유닛을 둘 것인지 - (일반적) 현재 리뷰의 감정을 스칼라 값의 예측으로 출력하는 세번째 층
- 위 두가지를 결정하는데 도움되는 "일반적인 원리"
- 중간에 있는 은닉 층은 '활성화 함수'로 relu 사용 (*relu"는 음수를 0으로 만드는 함수)
- 마지막 층은 확률(0과1사이의 점수, 어떤 샘플이 타깃'1'일 가능성이 높다는 것은 그 리뷰가 긍정적일 가능성이 높다는 것)을 출력하기 위해 '시그모이드 활성화 함수' 사용
- 시그모이드는 임의의 값을 [0,1]사이로 압축하므로, 출력 값을 확률처럼 해석할 수 있다.
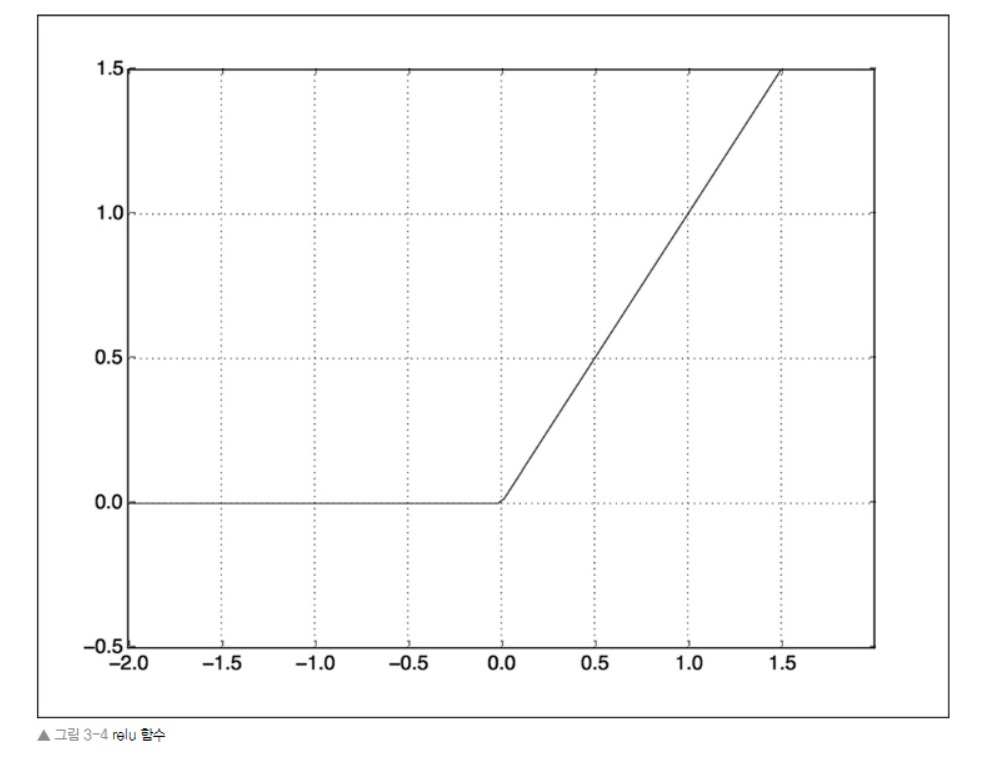
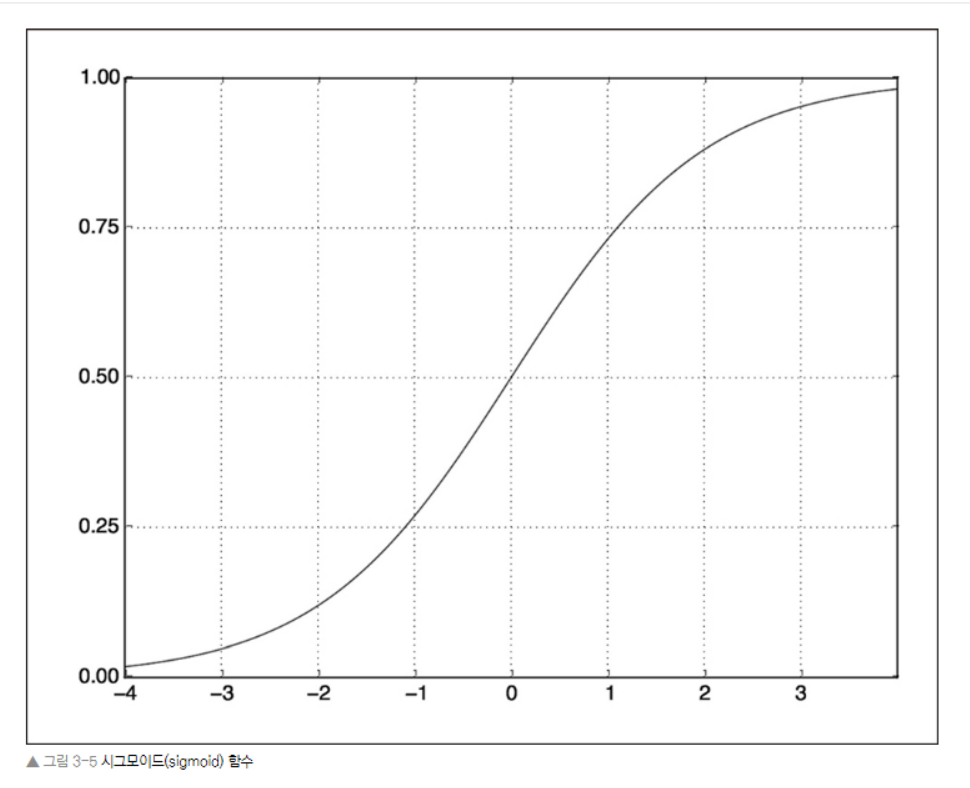

위의 일반적인 원리를 따르는 신경망을 케라스로 구현해보자.
# 모델 정의하기
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))- 이제 마지막으로 손실함수와 옵티마이저를 선택해야한다.
- 이진 분류 문제고, 신경망의 출력이 확률이기 때문에 (네트워크의 끝에 시그모이드 활성화 함수를 사용한 하나의 유닛으로 된 층을 놓음) binary_crossentropy 손실이 적합 (mean_squared_error도 사용 가능)
- 크로스 엔트로피는 정보 이론 분야에서 온 개념으로, 확률 분포 간의 차이를 측정한다.
- 여기에서는 원본 분포와 예측 분포 사이를 측정
- 이진 분류 문제고, 신경망의 출력이 확률이기 때문에 (네트워크의 끝에 시그모이드 활성화 함수를 사용한 하나의 유닛으로 된 층을 놓음) binary_crossentropy 손실이 적합 (mean_squared_error도 사용 가능)
모델 컴파일하기 ( rmsprop 옵티마이저와 binary_crossentropy 손실 함수로 모델을 설정하는 단계)
*훈련하는 동안 정확도로 모니터링 (metrics=['accuracy'])
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])- 케라스에 rmsprop, binary_crossentropy, accuracy가 포함되어 있어서, 옵티마이저, 손실함수, 측정 지표를 문자열로 지정하는 것이 가능함
- 옵티마이저의 매개변수를 바꿔야할 경우 : 아래 코드처럼 옵티마이저 파이썬 클래스를 이용해서 객체를 직접 만들어 optimizer 변수에 전달
# 옵티마이저 설정
from keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss = 'binary_crossentropy',
metrics=['accuracy'])* RMSprop이란? (lr은 learning rate)
- 딥러닝에서 각 노드의 weight를 조정할 때, batch마다 gradient를 계산해 일정 비율(learning rate)로 weight를 업데이트한다.
- 이때 learning rate값이 크면 weight는 발산하게되고, 또 너무 작으면 수렴하는속도가 느려 학습시간이 오래걸릴것이다.
- 그래서 gradient를 이용해 weight를 적절하게 업데이트 하는 여러가지 방법들이 있으며 자주사용되는 AdaGrad, RMSProp, Adam 3가지 방법 중 하나가 RMSprop이다.
- 옵티마이저에 측정 함수를 전달해야할 경우 : 아래 코드처럼 loss와 metrics 변수에 함수 객체 전달
# 손실과 측정을 함수 객체로 지정하기
from keras import losses
from kers import metrics
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss=losses.binary_crossentropy,
metrics=[metrics.binary_accuracy])
* 활성화 함수에 대해서
- relu와 같은 활성화 함수 (비선형성 이라고도 부른다.)가 없으면, Dense층은 선형적 연산인 점곱과 덧셈 2개로 구성되는데, → output = dot(W,input) + b
- 그러므로 이 층은 입력에 대한 선형 변환(아핀 변환)만을 학습할 수 있다.
- 이 층의 가설 공간은 입력데이터를 16차원의 공간으로 바꾸는 가능한 모든 선형 변환의 집합
- 이런 가설공간은 매우 제약이 많으며, 선형 층을 깊게 쌓아도 여전히 하나의 선형 연산이기 때문에 층을 여러개로 구성하는 장점이 없다. (즉, 층을 추가해도 가설 공간이 확장되지 않음)
- 가설 공간을 풍부하게 만들어 층을 깊게 만드는 장점을 살리기 위해서는 비선형성 또는 활성화함수를 추가해야한다.
- 그 중 relu가 딥러닝에서 가장 인기 있는 활성화함수. (그 외에 prelu, elu 도 있다.)
3.4.4 훈련 검증
- 훈련 중 처음 본 데이터에 대한 모델의 정확도를 측정하기 위해서는, 원본 훈련 데이터에 10,000의 샘플을 떼어 검증 세트로 만들어야한다.
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]- 이제 모델을 512개의 샘플씩 미니 배치를 만들어 20번의 에포크동안 훈련시킨다.
- x_train과 y_train 텐서에 있는 모든 샘플에 대해 20번 반복한다.
- 동시에 따로 떼어놓은 1만개의 샘플에서 손실과 정확도를 측정
- 이렇게 하려면 validation_data 매개변수에 검증 데이터에 전달해야함
# 모델 훈련
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])
history = model.fit(partial_x_train, partial_y_train, epochs=20,batch_size=512,
validation_data=(x_val,y_val))- 전체 훈련은 20초 이상 걸린다. 에포크가 끝날 때마다 1만개의 검증 샘플 데이터에서 손실과 정확도를 계산하기 때문에 약간씩 지연된다.
- model_fit() 메소드는 History 객체를 반환한다. 이 객체는 훈련하는 동안 모든 정보를 담고있는 딕셔너리인 history 속성을 갖고 있다.
history_dict = history.history
history_dict.keys()
# [u'acc', u'loss', u'val_acc', u'val_loss']- 위 딕셔너리는 훈련과 검증하는 동안, 모니터링할 측정 지표당 하나씩 모두 4개의 항목을 담고있다.
matplotlib 으로 훈련,검증 데이터에 대한 손실과 정확도를 그려보자.
# 훈련과 검증 손실
import matplotlib.pyplot as plt
history_dict = history.history
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1,len(loss)+1)
plt.plot(epochs, loss, 'bo', label='Training loss') #bo는 파란색 점
plt.plot(epochs, val_loss, 'b', label='Validation loss') # b는 파란색 실선
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()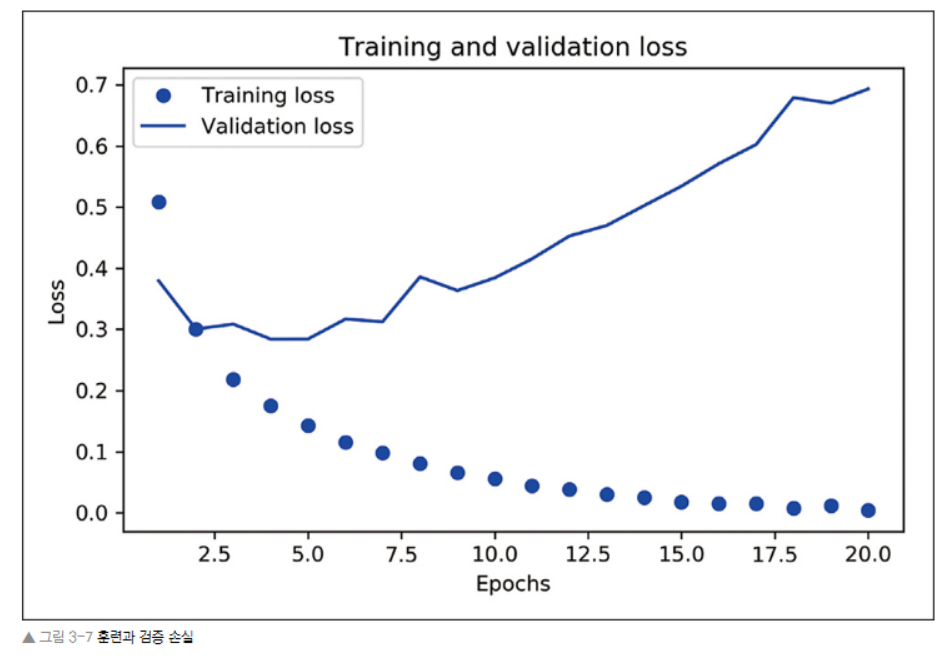
# 훈련과 검증 정확도
plt.clf() # 그래프 초기화
acc = history_dict['acc']
val_acc = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Traning and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
- 위 그림을 보면, 훈련 손실이 에포크마다 감소하고 훈련 정확도는 에포크마다 증가한다. (dot 그래프)
- 경사 하강법 최적화를 사용했을 때 반복마다 최소화되는 것이 손실이기 때문
- 검증 손실과 정확도는 훈련 손실과 정확도와 다르다.
- 네번째 에포크에서 그래프가 역전된다.
- 앞서 훈련 세트에서 잘 작동하는 모델이 처음 보는 데이터에서는 잘 작동하지 않을 수 있다는 사실을 보여줌 = 과대적합(overfitting) - 두번째 에포크 이후부터 훈련 데이터에 과도하게 최적화되어, 훈련 데이터에 특화된 표현을 하습해서, 훈련 세트 이외의 데이터에는 일반화되지 못함
처음부터 다시 새로운 신경망을 네 번의 에포크 동안만 훈련하고 테스트 데이터에서 평가해보자.
model = models.Sequential()
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
model.compile(optimizer='rmsprop', loss = 'binary_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=4, batch_size=512)
results = model.evaluate(x_test,y_test)
# 최종 결과
results
# [0,3231545869159698, 0.87348]- 단순한 방식으로 정확도가 87%가 나왔다. 최고 수준의 기법을 사용할시 95%에 가까운 성능을 얻을 수 있다.
3.4.5 훈련된 모델로 새로운 데이터에 대해 예측하기
모델을 훈련시킨 후, predict 메소드로 어떤 리뷰가 긍정일지 예측 가능
model.predict(x_test)
# array([[0.98006207] [0.99758697] ..., [0.82167041] [0.02885115] [0.65371346], dtype=float32)3.4.6 추가 실험 : 앞서 사용한 일반적인 원리 적용과 다르게 할경우 어떻게 되는지 확인해보자.
( 성능 안좋아짐 )
- 2개의 은닉 층 사용 → 1개 또는 3개의 은닉층 사용
- 층의 은닉 유닛을 추가하거나 줄여보자. (32개 유닛, 64개 유닛 ..)
- binary_crossentropy 대신 mse 손실함수를 사용해보자.
- relu 대신에 tanh 활성화 함수를 사용해보자.
3.4.7 정리 - 영화 이진 분류 예제를 통해 배운 것들
" 이진 분류 "
1. 원본 데이터를 신경망에 텐서로 주입하기 위해서 많은 전처리가 필요단어 시퀀스는 이진 벡터로 인코딩 될 수 있고, 다른 인코딩 방식도 있다.
2. relu 활성화 함수와 함께 Dense 층을 쌓은 네트워크는 (감성 분류를 포함하여) 여러 종류의 문제에 적용할 수 있어, 앞으로 자주 사용될 것
3. (출력 클래스가 2개인) 이진 분류 문제에서는 네트워크는 하나의 유닛과 sigmoid 활성화 함수를 가진 Dense 층으로 끝나야한다.
4. 이 신경망의 출력은 확률을 나타내는 0과 1사이의 스칼라 값이다.이진 분류 문제에서 이런 스칼라 시그모이드 출력에 대해 사용할 손실 함수는 binary_crossentropy이다.
5. rmspop 옵티마이저는 문제에 상관없이 일반적으로 충분히 좋은 선택
6, 훈련 데이터에 대해 성능이 향상됨에 따라 신경망은 과대적합되기 시작하고, 이전에 본적 없는 데이터에서는 결과가 점점 나빠지게 된다. 항상 훈련 세트 이외의 데이터에서 성능을 모니터링해야한다.
3-5. 뉴스 기사 분류 : 다중 분류 예제
- 이전 절에서는 완전 연결된 신경망을 사용하여, 벡터 입력을 어떻게 2개의 클래스로 분류하는지 보았다. 2개이상의 클래스가 있다면 어떻게 해야할까?
- 이 절에서는 로이터뉴스를 46개의 상호 배타적인 토픽으로 분류하는 신경망을 만들어볼 것이다. 클래스가 많기 때문에 이 문제는 '다중 분류'의 예이다. 각 데이터 포인트가 정확히 하나의 범주로 분류되기 때문에 좀 더 정확히 말하면 단일 레이블 다중 분류 (single-label, multiclass classification) 문제이다. 각 데이터 포인트가 여러개의 범주(예를 들어 토픽)에 속할 수 있다면 이것은 다중 레이블 다중분류 문제가 된다.
3.5.1 로이터 데이터셋
- 텍스트 분류를 위해 널리 사용됨
- 46개의 토픽이 있고, 어떤 토픽은 다른 것에 비해 데이터가 많음
- 각 토픽은 훈련 세트에 최소한 10개의 샘플을 가지고 있음
from keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)- IMDB 데이터셋처럼 num_words=10000 매개변수는 데이터에서 가장 자주등장하는 단어 1만개로 제한
len(train_data)
# 8982
len(test_data)
# 2246
train_data[10]
# [1, 245, 273, 207, 156, 53, 74, 160, 26, 14, 46, 296, 26, 39, 74, 2979, 3554, 14, 46,
# 4689, 86, 61, 3499, 44795, 14, 61, 451, 4329, 17, 12]- 훈련 샘플은 8982개, 테스트 샘플은 2246개이다. 그리고 IMDB 리뷰처럼 각 샘플은 정수 리스트이다.(단어 인덱스)
어떻게 단어로 디코딩하는지 알아보자.
#로이터 데이터셋을 텍스트로 디코딩
word_index = reuters.get_word_index()
reverse_word_index = dict([(value,key) for (key,value) in word_index.items()])
decoded_newswire = ' '.join([reverse_word_index.get(i-3,'?') for i in train_data[0])
# 0,1,2는 '패딩', '문서 시작', '사전에 없음'을 위한 인덱스라서 3을 뺀다.# 샘플에 연결된 레이블은 토픽의 인덱스로 0과 45사이의 정수이다.
train_labels[10]
# 33.5.2 데이터 준비
데이터를 벡터로 변환하자. (데이터 인코딩)
# 데이터를 벡터로 인코딩하기
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences),dimension))
for i, sequence in enumerate(sequences):
results[i,sequence] = 1.
return results
x_train = vectorize_sequences(train_data) #훈련 데이터 벡터 변환
x_test = vectorize_sequences(test_data) # 테스트 데이터 벡터 변환- 앞 절에서의 과정과 유사하다. 레이블을 벡터로 바꾸는 방법은 1) 레이블의 리스트를 정수 텐서로 변환, 2) 원-핫 인코딩 사용 2가니이고, 원-핫 인코딩이 범주형 데이터에 널리 사용되기 때문에 범주형 인코딩이라고도 부른다.
# 원-핫 인코딩 코드 예시
def to_one_hot(labels, dimension=46):
results=np.zeros((len(labels),dimension))
for i, label in enumerate(labels):
results[i,labels] = 1.
return results
one_hot_train_labels = to_one_hot(train_labels) # 훈련 레이블 벡터 변환
one_hot_test_labels = to_one_hot(test_labels) # 테스트 레이블 벡터 변환- 케라스에는 원-핫 인코딩을 위한 내장함수가 있기에, 위처럼 함수를 만들 필요가 없다. → to_categorical()
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)3.5.3 모델 구성
- 여기까지는 앞의 이진 분류 예제와 비슷해보인다. 두 예제 모두 짧은 텍스트를 분류한다는 공통점이 있다. 하지만, 다중 분류 예제에 새로운 제약사항이 추가되었다. 출력 클래스의 개수가 2 에서 46개로 늘어난 점이다. 출력공간의 차원이 훨씬 커졌다.
- 이전 예제처럼 Dense 층을 쌓으면 바로 이전 층의 출력에서 제공한 정보만 사용할 수 있다.
- 한 층이 분류문제에 필요한 일부 정보를 누락하면 그 다음 층에서 이를 복원할 방법이 없다. ( ↔ 각 층은 잠재적으로 정보의 병목이 될 수 있다. )
- 이전 예제에서는 16차원을 가진 중간층을 사용했지만, 16차원 공간은 46개의 클래스를 구분하기에 너무 제약이 많다. 규모가 작은 층은 유용한 정보를 완전히 잃게 되는 정보의 병목 지점처럼 동작할 수 있다.
더 큰 규모의 층이 필요하다. 64개 유닛을 사용해보자.
# 모델 정의하기
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))- 위 코드에서 주목해야할점 두가지
- 마지막 Dense 층의 크기가 46 = 각 입력 샘플에 대해서 46차원의 벡터를 출력한다는 의미
- 이 벡터의 각 원소(각 차원)는 각기 다른 출력 클래스가 인코딩 된 것
- 마지막 층에 softmax 활성화 함수가 사용되었다. (MNIST 예제에서도 사용했었음)
- 각 입력 샘플마다 46개의 출력 클래스에 대한 확률분포를 출력한다. 즉, 46차원의 출력 벡터를 만들며, output[i]는 어떤 샘플이 클래스 i에 속할 확률이다. 46개의 값을 모두 더하면 1이 된다.
- 이런 문제에 최선의 손실함수는 categorical_crossentropy이다. (앞에서 나왔었다. 두 확률 분포사이의 거리 측정)
- 여기서는 네트워크가 출력한 확률 분포와 진짜 레이블의 분포 사이의 거리, 두 분포 사이의 거리를 최소화하면 진짜 레이블에 가까운 출력을 내도록 모델을 훈련하게 됨
- 마지막 Dense 층의 크기가 46 = 각 입력 샘플에 대해서 46차원의 벡터를 출력한다는 의미
모델 컴파일하기
모델 컴파일
model.compile(optimizer='rmsprop', loss='categorical_crossentropy',metrics=['accuracy']3.5.4 훈련 검증
훈련 데이터에서 1,000개의 샘플을 떼어서 검증세트로 사용하자.
# 검증 세트 준비
x_va = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]20번의 에포크로 모델을 훈련시키자.
# 모델 훈련하기
history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=512,
validation_data=(x_val,y_val))손실과 정확도 곡선을 그려보자.
# 훈련과 검증 손실 그리기
import matplotlib.pyplot as plt
loss=history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(loss) + 1)
plt.plot(epochs, loss, 'bo', labels='Training loss')
plt.plot(epochs, val_loss, 'b', labels='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()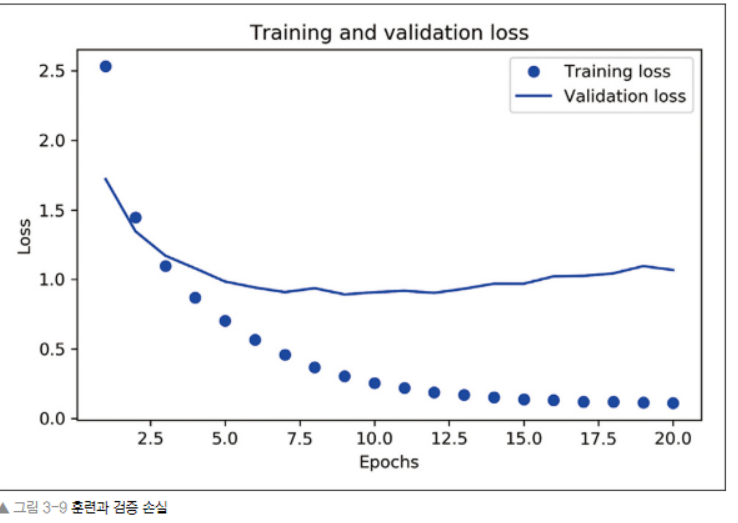
# 훈련과 검증 정확도 그리기
plt.clf() # 그래프 초기화
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
plt.plot(epochs,acc,'bo',label='Training acc')
plt.plot(eopchs,val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
- 그래프를 그려 확인해보니, 이 모델은 아홉 번째 에포크 이후 과대적합이 시작된다. 따라서, 아홉번의 에포크로 새로운 모델을 훈련하고 테스트 세트에서 평가하자.
모델을 처음부터 다시 훈련하기
# epochs=9로 처음부터 다시 훈련
model = models.Sequential()
model.add(layers.Dense(64, activation='relu',input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46,activation='softmax'))
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])
model.fit(partial_x_train, partial_y_train, epochs=9, batch_size=512,
validation_data=(x_val,y_val))
results = model.evaluate(x_test, one_hot_test_labels)
#최종 결과는 다음과 같다.
results
# [1.022498257544459, 0.7756010686194165 ]- 대략 78%의 정확도를 달성했다.
- 균형 잡힌 이진 분류 문제에서 무작위로 분류시 50%의 정확도를 달성한다.
- 이 문제는 불균형한 데이터셋을 사용하므로 무작위로 분류시 18%정도를 달성한다.
- 따라서 78%면 좋은 편
불균형 데이터셋을 무작위로 분류시 18% 정확도
import copy
test_labels_copy = copy.copy(test_labels)
np.random.shuffle(test_labels_copy)
hits_array = np.array(test_labels_copy)
hits_array = np.array(test_labels) == np.array(test_labels_copy)
float(np.sum(hits_array)) / len(test_labels)
# 0.1825467497773823.5.5 새로운 데이터에 대해 예측하기
- 모델 객체는 predict 메소드는 46개의 토픽에 대한 확률분포를 반환한다. 테스트 데이터 전체에 대한 토픽을 예측해보자.
새로운 데이터에 대해 예측해보기
predictions = model.predict(x_test)
predictions[0].shape
# (46,) -> predictions의 각 항목은 길이가 46인 벡터
np.sum(predictions[0])
# 1.0 -> 이 벡터의 원소합은 1이다.
np.argmax(predictions[0])
# 3 -> 가장 큰 값이 예측 클래스가 된다. 즉, 가장 확률이 높은 클래스는 3이다.3.5.6 레이블과 손실을 다루는 다른 방법
- 레이블을 인코딩하는 두가지 방법 중 원-핫 인코딩을 사용했었다. 다른 방법인 정수 텐서로 변환하는 법에 대해 알아보자.
y_train = np.array(train_labels)
y_test = np.array(test_labels)- 이 방식을 사용하려면, 손실 함수 하나만 바꾸면 된다. 앞서 사용한 손실 함수 cateogorical_crossentropy는 레이블이 범주형 인코딩되어 있을 것이라 기대한다. 정수 레이블을 사용할 때에는 sparse_categorical_crossentroopy를 사용해야 한다.
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy',metrics=['accuracy'])* 위 함수는 categorical_crossentropy와 인터페이스만 다르지, 수학적으로는 동일하다.
3.5.7 충분히 큰 중간층을 두어야 하는 이유
- 출력이 46차원이기 때문에, 중간층의 히든 유닛이 46개보다 많이 적어서는 안된다.
- 왜 안되는지 알아보기 위해 46차원보다 훨씬 작은 층(ex.4차원)을 두면 두 정보의 병목이 어떻게 나타나는지 확인해보자. (정보 병목)
정보 병목이 있는 모델(X)
model = models.Sequential()
model.add(layers.Dense(64,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(4,activation='relu'))
model.add(layers.Dense(46,activation='softmax'))
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])
model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=128,
validation_data=(x_val,y_val))- 검증 정확도의 최고값이 71%로 나온다. 8%정도 감소되었다.
- 이러한 손실의 원인은 많은 정보를 중간층의 저차원 표현 공간으로 압축하려 했기 때문
- 이 네트워크는 필요한 정보 대부분을 4차원의 표현 안에 구겨넣었지만 전부는 넣지 못함
3.5.8 추가 실험
- 더 크거나 작은 층을 사용해보자 32개의 유닛, 128개의 유닛 등
- 여기에서 2개의 유닛층을 사용하였는데, 1개나 3개의 은닉층을 사용해보자.
3.5.9 정리
" 다중 분류 "
1. N개의 클래스로 데이터 포인트를 분류하려면 네트워크의 마지막 Dense 층의 크기는 N이어야 한다.
2. 단일 레이블, 다중 분류 문제에서는 N개의 클래스에 대한 확률 분포를 출력하기 위해 softmax활성화 함수를 사용해야 한다.
3. 이런 문제에는 항상 범주형 크로스엔트로피를 사용해야 한다.
(이 함수는 모델이 출력한 확률 분포와 타깃 분포 사이의 거리를 최소화한다.)
4. 다중 분류에서 레이블을 다루는 두가지 방법이 있다.
4-1. 레이블을 범주형 인코딩(원-핫 인코딩)하고, cateogircal_crossentropy 손실 함수를 사용
4-2. 레이블을 정수로 인코딩하고, sparse_cateogircal_crossentropy 손실 함수를 사용
5. 많은 수의 범주를 분류할 때 중간 층의 크기가 너무 작아 네트워크에 정보의 병목이 생기지 않도록 해야한다.
3-6. 주택 가격 예측 : 회귀 문제
- 앞서 다룬 2개의 분류 문제는 입력 데이터 포인트의 개별적인 레이블 하나를 예측하는 것이 목적이다.
- 머신 러닝 문제 중 회귀는 개별적인 레이블 대신에 연속적인 값을 예측한다.
- ex. 가상 데이터가 주어졌을 때 내일 기온을 예측하거나, 소프트웨어 명세가 주어졌을 때, 소프트웨어 프로젝트가 완료된 시간을 예측
3.6.1 보스턴 주택 가격 데이터셋
- 중반 보스턴 외곽 지역의 범죄율, 지방 세율등의 데이터가 주어졌을 때, 주택 가격의 중간 값을 예측해보자.
- 분류 문제에서 사용했던 데이터셋과의 차이점은
- 데이터 포인트가 506개로 비교적 개수가 적고, 404개는 훈련 샘플, 102개느느 테스트 샘플로 나누어져있다.
- 입력 데이터에 있는 각 특성(ex.범죄율)은 스케일이 서로 다르다. 어떤 값은 0과 1사이의 비율을 나타내고, 어떤 것은 1과 12사이의 값을 가지거나, 1과 100사이의 값을 가진다.
보스턴 주택 데이터셋 로드하기
from keras.datasets import boston_housing
(train_data, train_targets), (test_data, teset_targets) = boston_housing.load_data()
boston_housing.load_data()
train_data.shape
# (404,13)
test_data.shape
# (102,13)- 여기서 볼 수 있듯이 404개의 훈련 샘플과 102개의 테스트 샘플이 있고, 모두 13개의 수치 특성이 있다. 이 특성들은 1인당 범죄율, 주택당 평균 방의 개수, 고속도로 접근성 등이다.
- 타깃은 '주택의 중간 가격'으로 천달러 단위이다.
train_targets
# [ 15.2, 42.3, 50. ... 19.4, 19.4, 29.1]- 이 가격은 일반적으로 1만 달러에서 5만 달러 사이이다.
3.6.2 데이터 준비
- 상이한 스케일을 가진 값을 신경망에 주입시 문제가 된다. 따라서 스케일이 다른 데이터를 다룰시, 특성별로 정규화를 해주어야한다. (입력 데이터에 있는 각 특성(열)에 대해 특성의 평균을 빼고 표준편차로 나누는 것)
데이터 정규화하기
# 데이터 정규화
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std- 테스트 데이터를 정규화할 때 사용한 값이 훈련 데이터에서 계산한 값임을 주목하자. 머신러닝 작업 과정에서는 절대로 테스트 데이터에서 계산한 어떤 값도, 데이터 정규화처럼 간단한 작업일지라도 사용해서는 안된다,
3.6.3 모델 구성
- 샘플 개수가 적기 때문에 64개의 유닛을 가진 2개의 은닉 층으로 작은 네트워크를 구성하여 사용해보자.
- 훈련 데이터 개수가 적을수록 과대적합이 더 쉽게 일어나므로, 작은 모델을 사용하는 것이 과대적합을 피하는 방법 중 하나이다.
모델 정의하기
# 모델 정의하기
from keras import models
from keras import layers
def build_model():
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
return model- 이 네트워크의 마지막 층은 하나의 유닛을 가지고 있고, 활성화 함수가 없다. (=선형 층이라 부른다.)
- 이것이 전형적인 스칼라 회귀 (=하나의 연속적인 값을 예측하는 회귀)를 위한 구성이다.
- 활성화 함수를 적용하면 출력 값의 범위를 제한하게 되기 때문이다. (↓)
- 만약에 마지막 층에 sigmoid 활성화 함수를 적용하면, 네트워크가 0과 1사이의 값을 예측하도록 학습될 것이다. 하지만 여기서는 마지막 층이 순수 선형이므로 네트워크가 어떤 범위의 값이라도 예측하도록 자유롭게 학습된다.
- 이 모델은 mse 손실 함수를 사용하여 컴파일한다. 이 함수는 평균제곱 오차의 약어로, 예측과 타깃 사이의 거리의 제곱이다. 회귀문제에서 널리 사용되는 손실함수이다.
- 훈련하는 동안 모니터링을 위해 새로운 지표인 평균절대오차(Mean absoloute Error, MAE)를 측정한다. 예측과 타깃 사이의 거리의 절댓값이다.
- ex. 이 예제에서 MAE가 0.5면 예측이 500달러정도 차이가 난다는 뜻이다.
3.6.4 K-겹 검증을 사용한 훈련 검증
- 훈련에 사용할 에포크의 수와 같은 매개변수들을 조정하면서, 모델을 평가하기 위해 이전 예제에서 했던 것처럼 데이터를 훈련 세트와 검증 세트로 나눈다.
- 데이터 포인트가 많지 않아서, 나누고 나면 검증 세트도 매우 작아진다.(약 100개의 샘플)
- 결국 검증 세트와 훈련 세트로 어떤 데이터 포인트가 선택되었는지에 따라 검증 점수가 크게 달라진다.
- 검증 세트의 분할에 대한 검증 점수의 분산이 높아지기 떄문에, 신뢰있는 모델 평가를 할 수 없다. 따라서 이런 경우에 K fold 교차검증을 사용한다.
- k-fold cross validation : k개의 모델을 만들어, k-1개의 분할에서 훈련하고, 나머지 분할에서 평가하는 방법이다. 모델의 검증 점수는 k개의 검증 점수 평균이된다.
K fold cv 예제 코드
import numpy as np
k=4
num_val_samples = len(train_data) // k
num_epochs = 100
all_scores = [ ]
for i in range(k):
print('처리중인 폴드 #',i)
val_data = train_data[i * num_val_samples: (i+1) * num_val_samples]
val_targets = train_targets[i*num_val_samples: (i+1) * num_val_samples]
# 훈련 데이터 준비 : 다른 분할 전체
partial_train_data = np.concatenate( [train_data[:i * num_val_samples], train_data[(i+1)*
num_val_samples:]], axis=0)
partial_train_targets = np.concatenate([train_targets[:i *num_val_samples],
train_targets[(i+1)*num_val_samples:]], axis=0)
#케라스 모델 구성(컴파일 포함)
model = build_model()
model.fit(partial_train_data, partial_train_targets, epochs = num_epochs, batch_size=1, verbose=0)
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0) #검증 세트로 모델 평가
all_scores.append(val_mae)
# verbose=0이라 훈련 과정이 출력되지 않음
# num_epochs = 100으로 실행하면 다음과 같은 결과를 얻는다.
all_scores
# [2.0956787838794217, 2.2205937977098292, 2.859968412040484, 2.40535704039111]
np.mean(all_scores)
# 2.3953995083523267- 검증 세트가 다르므로, 검증 점수가 2.1에서 2.9까지 변화가 크다.
- 평균값(2.4)이 각각 점수보다 훨씬 신뢰할만하다. (이것이 kfold cv의 핵심이다.)
- 평균적으로 2400달러정도가 차이가 난다. 주택 가격의 범위가 1만달러에서 5만달러 사이인 것을 감안하면 비교적 큰 값이다.
신경망을 500 에포크동안 훈련해보고 각 에포크마다 모델이 얼마나 개선되는지 알아보자.
# 각 폴드에서 검증 점수를 로그에 저장하기
num_epochs = 500
all_mae_histories = [ ]
for i in range(k):
print('처리중인 폴드 #', i)
val_data = train_data[ i * num_val_samples: (i+1) * num_val_samples] #검증 데이터준비-k번째 분할
val_targets = train_targets[ i * num_val_samples: (i+1) * num_val_samples]
partial_train_data = np.concatenate( #훈련 데이터준비 - 다른 분할 전체
[train_data[:i * num_val_samples:]], axis=0)
partial_train_targets = np.concatenate([train_targets[:i * num_val_samples],
train_targets[(i+1)*num_val_samples:]], axis=0)
model = build_model() # 케라스 모델 구성(컴파일 포함)
history = model.fit(partial_train_data, partial_train_targets,
validation_data=(val_data, val_targets),
epochs = num_epochs, batch_size =1, verbose=0)
mae_history = history.history['val_mean_absolute_error']
all_mae_histories.append(mae_history)
# k fold 검증 점수 평균 기록
average_mae_history = [np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
# 검증점수 그래프
import matplotlib.pyplot as plt
plt.plot(range(1,len(average_mae_history) +1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Valiation MAE')
plt.show()
더 세부적으로 보자.
# 곡선의 다른 부분과 스케일이 많아, 다른 첫 10개의 데이터 포인트를 제외시키자.
# 부드러운 곡선을 얻기위해서 각 포인트를 이전 포인트의 지수 이동 평균으로 대체하자.
# 처음 10개의 데이터 포인트를 제외한 검증 점수 그리기
def smooth_curve(points, factor=0.9):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1-factor))
else:
smoothed_points.append(point)
return smoothed_points
smooth_mae_history = smooth_curve(average_mae_history[10:])
plt.plot(range(1,len(smooth_mae_history)+1), smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
- 그래프를 보면 검증 MAE가 80번째 에포크 이후에 줄어드는 것이 멈추었다. 이 지점 이후로 과대적합이 시작된다.
- 모델의 여러 매개변수에 대한 튜닝이 끝나면 (에포크수말고도 은닉 층의 크기도 조절 가능) 모든 훈련 데이터를 사용하고, 최상의 매개변수로 최종 실전에 투입될 모델을 훈련시킨다.
최종 모델 훈련하기
# 최종 모델 훈련
model = build_model() # 새롭게 컴파일된 모델 얻기
model.fit(train_data, train_targets, epochs=80, batch_size=16, verbose=0) #전체 데이터로 훈련시킴
tests_mse_score, test_mae_score = model.evaluate(test_data, test_targets)
# 최종 결과
test_mae_score
# 2.675027286305147
# 2,675달러정도 차이가 난다.
3.6.5 정리
" 스칼라 회귀 문제 "
1. 회귀는 분류에서와 다른 손실함수를 사용한다. MSE(평균 제곱오차)는 회귀에서 자주 사용되는 손실 함수
2. 회귀에서 사용되는 평가지표는 분류와 다르다. 당연히 정확도 개념은 회귀에 적용되지 않는다. 일반적인 회귀지표는 MAE(평균 절대 오차)이다.
3. 입력 데이터의 특성이 서로 다른 범위를 가지면 전처리 단계에서 각 특성을 개별적으로 스케일 조정해야한다.
4. 가용한 데이터가 적다면 K fold cv를 사용하는 것이 신뢰할 수 있는 모델 평가 방법이다.
5. 가용한 훈련 데이터가 적다면 과대적합을 피하기 위해 은닉 층의 수를 줄인 모델이 좋다.(1개 또는 2개.)
3-7. 요약
1. 이제 벡터 데이터로 가장 일반적인 머신러닝인 이진 분류, 다중 분류, 스칼라 회귀 작업을 다룰 수 있다.
2. 원본 데이터를 신경망에 주입하기 전, 전처리를 해야한다.
3, 데이터에 범위가 다른 특성이 있다면, 전처리 단계에서 각 특성을 독립적으로 스케일 조정해야한다.
4, 훈련이 진행됨에 따라 신경망의 과대적합이 시작되고, 새로운 데이터에 대해 나쁜 결과를 얻게된다.
5. 훈련 데이터가 많지 않으면, 과대적합을 피하기 위해 1개 또는 2개의 은닉 층을 가진 신경망을 사용한다.
6. 데이터가 많은 범주로 나뉘어져 있을 때, 중간층이 너무 작으면 '정보 병목'이 생길 수 있다.
7. 회귀는 분류와 다른 손실함수와 평가지표를 사용한다.
'데이터 분석 > 케라스 창시자에게 배우는 딥러닝' 카테고리의 다른 글
| [5] 케라스 창시자에게 배우는 딥러닝 - 5. 컴퓨터 비전을 위한 딥러닝( 합성곱 신경망 소개, MaxPooling, 고양이vs강아지 분류 예제, 데이터 증식) (0) | 2022.08.16 |
|---|---|
| [4] 케라스 창시자에게 배우는 딥러닝 - 4. (머신러닝) 분류, 특성 공학, 특성 학습, 과/소적합, 해결법(가중치 규제,드롭아웃 추가..) (1) | 2022.08.11 |
| [3,실습] 케라스 창시자에게 배우는 딥러닝 - 신경망 시작하기 (분류/회귀 문제 풀어보기 (1) | 2022.08.09 |
| [2] 케라스 창시자에게 배우는 딥러닝 - 신경망의 수학적 구성 요소 (1) | 2022.08.08 |
| [1] 케라스 창시자에게 배우는 딥러닝 - 딥러닝의 기초 (이론) (0) | 2022.07.28 |



