
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 분석 패널
- splitlines
- 부트 스트래핑
- tableau
- 3기가 마지막이라니..!
- ARIMA
- ImageDateGenerator
- pmdarima
- sql
- python
- WITH ROLLUP
- 캐글 신용카드 사기 검출
- WITH CUBE
- 데이터 증식
- 리프 중심 트리 분할
- 스태킹 앙상블
- 로그 변환
- 그로스 마케팅
- 인프런
- 데이터 정합성
- XGBoost
- 그룹 연산
- lightgbm
- 마케팅 보다는 취준 강연 같다(?)
- 데이터 핸들링
- Growth hacking
- DENSE_RANK()
- 캐글 산탄데르 고객 만족 예측
- 컨브넷
- 그로스 해킹
Archives
- Today
- Total
LITTLE BY LITTLE
[1] 케라스 창시자에게 배우는 딥러닝 - 딥러닝의 기초 (이론) 본문
https://codebaragi23.github.io/books/DeepLearningFromKeras/summary/
책 소개
단어 하나, 코드 한 줄 버릴 것이 없다!파이썬과 케라스로 배우는 딥러닝 핵심 원리!
codebaragi23.github.io
목차
더보기
제 1부. 딥러닝의 기초
- 딥러닝이란?
- 딥러닝 이전 : 머신러닝의 간략
- 왜 딥러닝일까? 왜 지금일까?
제 2부. 신경망의 수학적 구성 요소
- 신경망과의 첫 만남
- 신경망을 위한 데이터 표현 - 스칼라,벡터,행렬,3D텐서와 고차원 텐서, ..
- 신경망의 톱니바퀴 : 텐서 연산
- 신경망의 엔진 : 그래디언트 기반 최적화
- 첫번째 예제 다시 살펴보기
- 요약
제 3부. 신경망 시작하기
- 신경망의 구조
- 케라스 소개
- 딥러닝 컴퓨터 셋팅
- 영화 리뷰 분류 : 이진 분류 예제
- 뉴스 기사 분류 : 다중 분류 예제
- 주택 가격 예측 : 회귀 문제
- 요약
제 4부. 머신러닝의 기본 요소
- 머신러닝의 네 가지 분류
- 머신러닝 모델 평가
- 데이터 전처리, 특성 공학, 특성 학습
- 과대적합과 과소적합
- 보편적인 머신러닝 작업 흐름
- 요약
제 5부.컴퓨터 비전을 위한 딥러닝
- 합성곱 신경망 소개
- 소규모 데이터셋에서 밑바닥부터 컨브넷 훈련하기
- 사전 훈련된 컨브넷 사용하기
- 컨브넷 학습 시각화
- 요약
제 6부. 텍스트와 시퀀스를 위한 딥러닝
- 텍스트 데이터 다루기
- 순환 신경망 이해하기
- 순환 신경망의 고급 사용법
- 컨브넷을 사용한 시퀀스 처리
- 요약
제 7부. 딥러닝을 위한 고급 도구
- Sequential 모델을 넘어서 : 케라스의 함수형 API
- 케라스 콜백과 텐서보드를 사용한 딥러닝 모델 검사와 모니터링
- 모델의 성능을 최대화로 끌어올리기
- 요약
제 8부. 생성 모델을 위한 딥러닝
- LSTM으로 텍스트 생성하기
- 딥드림
- 뉴럴 스타일 트랜스퍼
- 변이형 오토인코더를 사용한 이미지 생성
- 적대적 생성 신경망 소개
- 요약
제 9부. 결론
- 핵심 개념 리뷰
- 딥러닝의 한계
- 딥러닝의 미래
- 빠른 변화에 뒤처지지 않기
- 맺음말
제 1부. 딥러닝의 기초
- 딥러닝이란?
- 딥러닝 이전 : 머신러닝의 간략
- 왜 딥러닝일까? 왜 지금일까?
- 포함 관계 : 인공지능 > 머신러닝 > 딥러닝
- 전통적인 프로그래밍은 규칙과 데이터로 해답을 찾았다면, 머신 러닝은 해답과 데이터로 규칙을 찾아낸다.
- 머신러닝은 샘플과 기댓값이 주어졌을 때 데이터 처리 작업을 위한 실행 규칙을 찾는 것
- 세가지가 필요하다.
- 예를 들어 '이미지 태깅에 대한 작업'이라면
- 입력 데이터 포인트(ex.사진),
- 기대 출력(ex. '강아지','고양이'와 같은 태그
- 알고리즘의 성능을 측정하는 방법(을 통해서 수정, 수정 단계를 학습 이라 칭함)
- 머신러닝과 딥러닝의 핵심 문제는 '의미있는 출력으로의 변환'
- 즉, 입력 데이터를 기반으로 기대 출력에 가깝게 만드는 유용한 표현의 학습 (표현이란, 데이터를 일코딩하거나 묘사하기 위해 데이터를 바라보는 다른 방법)
머신러닝
- 예를 들어, 컬러 이미지는 RGB 포맷(빨-노-파)과 HSV 포맷(색상-채도-명도)이 있는데, "이미지에 있는 모든 빨간색 픽셀을 선택"하고자 한다면, RGB 포맷에서 더 쉽고, "이미지의 채도를 낮추는" 것은 HSV 포맷에서 더 쉽기에, 머신러닝 모델은 입력데이터에서 이런식으로 적절한 표현을 찾는 것이다.
- 이러한 데이터 변환과정은 분류 작업과 같은 문제를 더 쉽게 해결할 수 있게 해준다.

- 위와 같은 예시 데이터가 주어졌다고 해보자. 포인트의 좌표(X,Y)를 입력으로 받고, 그 포인트가 빨간색인지 흰색인지 출력하는 알고리즘을 개발하려 한다.
- 입력은 '포인트의 좌표'
- 기대 출력은 '포인트의 색깔'
- 알고리즘의 성능은 정확히 분류한 포인트의 비율을 사용하여 측정함
- 흰색 포인트와 빨간색 포인트를 완벽히 구분하기 위해 새로운 데이터 표현 필요
- 사용할 수 있는 변환 방법 중 하나는 다음과 같은 좌표 변환
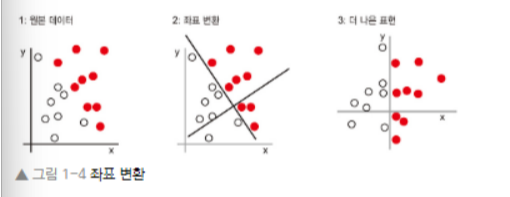
- 포인트에 대한 새로운 좌표 = 새로운 데이터 표현
- 그리고 좋은 표현을 찾았다. 이 표현을 사용하면 색깔 분류 문제를 "X>0 인 것은 빨간색 포인트이다." 혹은 "X<0인 것은 흰색 포인트이다."라는 간단한 규칙으로 나타낼 수 있다.
- 이렇게 기본적으로 분류 문제를 해결한 것은 새로운 표현이다. 우리가 직접 좌표 변환을 정했지만, 만약 시스템적으로 가능한 여러 좌표변환을 찾아서, 그 중 몇퍼센트가 정확히 분류되었는지를 피드백으로 사용한다면, 그것이 머신러닝이다.
- 머신러닝은 가능성있는 공간을 사전에 정의하고, 피드백 신호의 도움을 받아 입력 데이터에 대한 유용한 변환을 찾는 것
딥러닝
- 딥러닝은 머신러닝의 특정한 한 분야, 연속된 층에서 점진적으로 의미있는 표현을 배우는데 강점이 있다. 데이터로부터 표현을 학습하는 새로운 방식
- 딥러닝에서 '딥'은 연속된 층으로 표현을 학습한다는 개념에서 딥러닝이라고 불린다.
- 층들을 모두 훈련데이터에 노출해서 자동으로 학습시킨다. (한편 머신러닝 접근법은 1-2개의 데이터 표현층을 학습하는 경향이 있다.그래서 얕은 학습이라 부르기도 한다.)
- 딥러닝에서는 기본 층을 겹겹이 쌓아 구성한 신경망 이라는 모델을 거의 항상 사용하여 표현층을 학습한다.
- 이미지 안의 숫자를 인식하기 위해서 이미지를 어떻게 변환하는지 살펴보자.
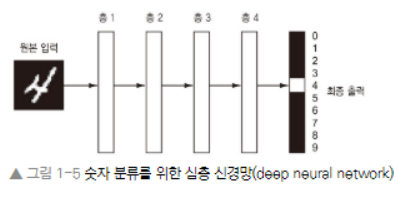
- 위의 그림에서 볼 수 있듯이, 최종 출력에 대해 점점 더 많은 정보를 가지지만, 원본 이미지와는 점점 더 다른 표현으로 숫자 이미지가 변환된다.
- 심층 신경망을 정보가 연속된 필터를 통과하면서, 순도높게 정제되는 다단계 정보 추출작업으로 생각할 수 있음

- 즉 딥러닝이란, 기술적으로 데이터 표현을 학습하기 위한 다단계 처리 방식
딥러닝의 작동 원리
- 머신러닝은 많은 입력과 타깃의 샘플을 관찰하며 입력(ex.이미지)을 타깃(ex.고양이 레이블)에 매핑하는 것
- 심층 신경망은 이러한 입력-타깃 매핑을 간단한 데이터 변환기(=층)을 많이 연결하여 수행하는 것
- 이런 데이터 변환은 샘플에 노출됨으로써 학습이 이루어짐
- 층에서 입력 데이터가 처리되는 상세 내용은 층의 가중치에 저장되어 있음 (즉, 어떤 층에서 일어나는 변환은 그 층의 가중치를 파라미터로 가지는 함수로 표현됨)
- 학습은 주어진 입력을 정확한 타깃에 매핑하기 위해 신경망의 모든 층에 있는 가중치 값을 찾는 것을 의미
- 하지만 모든 파라미터의 정확한 값을 찾는 것은 어렵기에 ( 하나를 바꾸면 다른 것에 영향 끼침 ) 조정하려면 먼저 "관찰"해야 한다. 신경망의 출력을 제어하려면 출력이 기대하는 것보다 얼마나 벗어났는지 측정해야함. (이것이 신경망의 손실함수 또는 목적함수가 담당하는 일이다.예측도 측정을 위해 이 함수가 차이를 점수로 계산)
- 기본적인 딥러닝 방식은 이 점수를 피드백 신호로 사용하여, 손실점수가 감소되는 방향으로 가중치 값을 조금씩 수정하는 것 ( 이 수정 과정은 딥러닝의 핵심 알고리즘인 역전파 알고리즘을 구현한 옵티마이저가 담당한다. )
- 초기에는 네트워크의 가중치가 랜덤으로 할당되어 랜덤한 변환을 연속적으로 수행
- 자연스럽게 출력은 기대한 것과 멀어지고 손실 점수는 매우 높을 것.
- 하지만, 네트워크가 모든 샘플을 처리하면서 가중치가 조금씩 올바른 방향으로 조정되고, 손실점수가 감소함
- 이를 훈련 반복이라 하며, 충분한 횟수만큼 반복하면 손실 함수를 최소화하는 가중치 값을 산출함
- 최소한의 손실을 내는 네트워크가 타깃에 가능한 가장 가까운 출력을 만드는 모델이 된다.
나이브 베이즈
- 입력 데이터의 특성이 모두 독립적이라고 가정하고 베이즈 정리를 적용하는 머신러닝 분류 알고리즘
로지스틱 회귀
- 이름 때문에 혼동하기 쉽지만, 회귀 알고리즘이 아니라 분류 알고리즘이다.
- 분류 작업에 대한 감을 빨리 얻기 위해서 데이터에 적용할 첫 번째 알고리즘으로 선택하는 경우가 많음
커널 방법 - 서포트 벡터 머신
- 머신러닝의 새로운 접근 방법인 커널 방법이 인기를 얻자, 신경망은 빠르게 잊혔다.
- 커널 방법은 분류 알고리즘의 한 종류이며, 서포트 벡터 머신이 가장 유명하다.
- SVM은 분류 문제를 해결하기 위해 2개의 다른 범주에 속한 데이터 포인트 그룹 사이에 좋은 결정 경계를 찾는다.
- 결정 경계는 훈련 데이터를 2개의 범주에 대응하는 영역으로 나누는 직선이나 표면으로 생각할 수 있다.
- 새로운 데이터 포인트를 분류하려면 결정 경계 어느쪽에 속하는지를 확인하기만 하면 된다.
- 결정 경계를 찾는 과정은
- 하나의 hyperplane으로 표현될 수 있는 경우, 새로운 고차원 표현으로 데이터를 매핑
- 초평면과 각 클래스의 가장 가까운 데이터 포인트 사이의 거리가 최대가 되는 최선의 결정경계를 찾는다. 이 단계를 마진 최대화(margin maximization)이라 부르고, 이 과정으로 결정경계가 훈련 데이터셋 이외에도 새로운 샘플에 잘 일반화되도록 해줌
- 분류문제를 간단히 하기위해 데이터를 고차원 표현으로 매핑하는 방법은 컴퓨터로 구현하기 어렵기에, 커널 기법이 등장한 것
- 좋은 결정 초평면을 찾기 위해서 좌표를 구할 필요 없이, 두 데이터 포인트 사이의 거리를 계산할 수만 있으면 된다.
- 커널 함수는 '원본 공간에 있는 두 데이터 포인트를 명시적으로 새로운 표현으로 변환하지 않고, 타깃 표현 공간에 위치했을 때의 거리를 매핑해주는 계산 가능한 연산' / 일반적으로 데이터로부터 학습되지 않고, 직접 만들어야한다. SVM에서 학습되는 것은 분할 초평면 뿐이다.
- SVM의 단점은 대용량의 데이터셋에 확장되기 어렵고, 이미지 분류같은 지각에 관련된 문제에서 좋은 성능을 내지 못한 것
- 얕그리고 얕은 학습 방법이기 때문에 지각에 관련된 문제에 SVM을 적용하려면 먼저 수동으로 유용한 표현을 추출해야하는데 ( 이 단계는 '특성 공학[feature engineering]'이라 한다. ) 이는 매우 어렵고 불안정함
결정 트리 (Decision Tree), 랜덤 포레스트, 그래디언트 부스팅 머신(GBM)
- 결정 트리는 flow chart와 같은 구조를 가지며, 입력 데이터 포인트를 분류하거나 주어진 입력에 대해 출력값을 예측한다.
- 시각화하고 이해하기 쉽다.
- 학습된 파라미터는 데이터에 관한 질문으로, 예를 들면 '데이터에 있는 2번째 특성이 3.5보다 큰가?'와같은 질문이 될 수 있다.
- 랜덤 포레스트 알고리즘은 결정트리 학습에 기초한 것이다. 안정적이고, 실전에서 유용함
- 서로 다른 결정 트리를 많이 만들고, 그 출력을 앙상블하는 방법을 사용
- 얕은 학습에 해당하는 작업에서도 거의 항상 2번째로 좋은 알고리즘
- 그래디언트 부스팅 머신은 랜덤 포레스트와 비슷하게, 약한 예측 모델인 결정 트리를 앙상블하는 것을 기반으로 한다.
- 이 알고리즘은 이전 모델에서 놓친 데이터 포인트를 보완하는 새로운 모델을 반복적으로 훈련함으로써 머신 러닝 모델을 향상하는 방법인 그래디언트 부스팅을 사용
- 결정 트리에 그래디언트 부스팅 기법을 적용하면, 비슷한 성질을 가지면서 대부분 랜덤 포레스트를 능가하는 모델을 만듦
딥러닝의 특징
- 딥러닝은 머신러닝에서 가장 중요한 단계인 특성 공학을 완전히 자동화하기 때문에 문제해결을 쉽게 만들어줌
- 얕은 학습인 이전의 머신러닝은 입력 데이터를 고차원 비선형 투영(SVM)이나 결정 트리같은 간단한 변환을 통해 하나 또는 2개의 연속된 표현 공간으로만 변환한다. 그래서 복잡한 문제에 필요한 정제된 표현은 이런방식으로는 얻어지지 못하는 경우가 많음. 그래서 사람이 직접 초기 입력 데이터를 여러방식으로 변환해야하는데, 이를 특성공학이라 한다.
- 그에 반해 딥러닝은 이 단계를 자동화한다. 특성을 찾는 대신, 모든 특성을 학습할 수 있다.
- 머신러닝의 고도의 다단계 작업 과정을 하나의 end-to-end 딥러닝 모델로 대체 가능
- 그 원리
- 3개의 층을 가진 모델에서 최적의 1번째 표현 층은 1개의 층이나, 2개의 층을 가진 모델에서 최적의 1번째 층과 달라야함
- 딥러닝 변환 능력은 모델이 모든 표현 층을 순차적이 아니라(=greedily) 동시에 공동으로 학습하게 만듦
- 그래서 공동 특성 학습 능력 덕분에 모델이 내부 특성 하나에 맞추어질 때마다 이에 의존하는 다른 특성이 사람개입 없이 자동으로 변화에 적응하게 되는 것
- 그 원리
- 딥러닝이 데이터로부터 학습하는 방법에서 중요한 2가지 특성은
- 층을 거치면서 점진적으로 더 복잡한 표현이 만들어진다는 것
- 이런 점진적인 중간 표현이 공동으로 학습된다는 것
- 각 층은 상위 층과 하위 층의 표현이 변함에 따라 함께 바뀐다.
- 위 2가지 특성이 머신러닝 접근법보다 딥러닝이 성공하게 된 이유
- 그래디언트 부스팅 머신은 주로 구조적인 데이터인 경우에 사용되고, (거의 항상 XGBoost 라이브러리 사용)
- 딥러닝은 이미지 분류 같은 지각에 관한 문제에 사용됨
- 즉, 오늘날 머신러닝 적용을 위해 알아야할 두가지 기술은 1)그래디언트 부스팅 머신 2)지각에 관한 문제를 위한 딥러닝 이다.
- 딥러닝은 이전의 많은 머신러닝 방법과는 다르게, 처음부터 다시 시작하지 않고 추가되는 데이터로도 훈련할 수 있다. 즉, 대규모 제품에 사용되는 모델에는 아주 중요한 기능인 '연속적인 온라인 학습(online earning)'을 가능케함
- 더불어 훈련된 딥러닝 모델은 다른 용도로 쓰일 수 있어 재사용이 가능 (ex. 이미지 분류를 위해 훈련된 딥러닝 모델을 비디오 처리 작업 과정에 투입시킬 수 있음)
- 아주 작은 데이터셋에도 딥러닝 모델을 적용할 수 있음
- 더 복잡하고 강력한 모델을 만들기 위해 이전의 작업을 재활용할 수 있음
- 딥러닝은 이미지 분류 같은 지각에 관한 문제에 사용됨
'데이터 분석 > 케라스 창시자에게 배우는 딥러닝' 카테고리의 다른 글
| [5] 케라스 창시자에게 배우는 딥러닝 - 5. 컴퓨터 비전을 위한 딥러닝( 합성곱 신경망 소개, MaxPooling, 고양이vs강아지 분류 예제, 데이터 증식) (0) | 2022.08.16 |
|---|---|
| [4] 케라스 창시자에게 배우는 딥러닝 - 4. (머신러닝) 분류, 특성 공학, 특성 학습, 과/소적합, 해결법(가중치 규제,드롭아웃 추가..) (1) | 2022.08.11 |
| [3,실습] 케라스 창시자에게 배우는 딥러닝 - 신경망 시작하기 (분류/회귀 문제 풀어보기 (1) | 2022.08.09 |
| [3] 케라스 창시자에게 배우는 딥러닝 - 신경망 시작하기(분류/예측 예제 풀어보기) (0) | 2022.08.08 |
| [2] 케라스 창시자에게 배우는 딥러닝 - 신경망의 수학적 구성 요소 (1) | 2022.08.08 |
'데이터 분석/케라스 창시자에게 배우는 딥러닝' Related Articles
more




Comments