
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- sql
- 그로스 해킹
- 그로스 마케팅
- 분석 패널
- splitlines
- 캐글 신용카드 사기 검출
- 마케팅 보다는 취준 강연 같다(?)
- 리프 중심 트리 분할
- lightgbm
- XGBoost
- 그룹 연산
- pmdarima
- ImageDateGenerator
- 데이터 정합성
- 데이터 증식
- 데이터 핸들링
- WITH ROLLUP
- python
- DENSE_RANK()
- WITH CUBE
- ARIMA
- tableau
- 3기가 마지막이라니..!
- 캐글 산탄데르 고객 만족 예측
- 부트 스트래핑
- Growth hacking
- 스태킹 앙상블
- 인프런
- 로그 변환
- 컨브넷
- Today
- Total
LITTLE BY LITTLE
[2] 케라스 창시자에게 배우는 딥러닝 - 신경망의 수학적 구성 요소 본문
제 2부. 신경망의 수학적 구성 요소
- 신경망과의 첫 만남
- 신경망을 위한 데이터 표현 - 스칼라,벡터,행렬,3D텐서와 고차원 텐서, ..
- 신경망의 톱니바퀴 : 텐서 연산
- 신경망의 엔진 : 그래디언트 기반 최적화
- 첫번째 예제 다시 살펴보기
- 요약
목차
제 3부. 신경망 시작하기
- 신경망의 구조
- 케라스 소개
- 딥러닝 컴퓨터 셋팅
- 영화 리뷰 분류 : 이진 분류 예제
- 뉴스 기사 분류 : 다중 분류 예제
- 주택 가격 예측 : 회귀 문제
- 요약
제 4부. 머신러닝의 기본 요소
- 머신러닝의 네 가지 분류
- 머신러닝 모델 평가
- 데이터 전처리, 특성 공학, 특성 학습
- 과대적합과 과소적합
- 보편적인 머신러닝 작업 흐름
- 요약
제 5부.컴퓨터 비전을 위한 딥러닝
- 합성곱 신경망 소개
- 소규모 데이터셋에서 밑바닥부터 컨브넷 훈련하기
- 사전 훈련된 컨브넷 사용하기
- 컨브넷 학습 시각화
- 요약
제 6부. 텍스트와 시퀀스를 위한 딥러닝
- 텍스트 데이터 다루기
- 순환 신경망 이해하기
- 순환 신경망의 고급 사용법
- 컨브넷을 사용한 시퀀스 처리
- 요약
제 7부. 딥러닝을 위한 고급 도구
- Sequential 모델을 넘어서 : 케라스의 함수형 API
- 케라스 콜백과 텐서보드를 사용한 딥러닝 모델 검사와 모니터링
- 모델의 성능을 최대화로 끌어올리기
- 요약
제 8부. 생성 모델을 위한 딥러닝
- LSTM으로 텍스트 생성하기
- 딥드림
- 뉴럴 스타일 트랜스퍼
- 변이형 오토인코더를 사용한 이미지 생성
- 적대적 생성 신경망 소개
- 요약
제 9부. 결론
- 핵심 개념 리뷰
- 딥러닝의 한계
- 딥러닝의 미래
- 빠른 변화에 뒤처지지 않기
- 맺음말
2-1. 신경망과의 첫 만남
- 케라스 파이썬 라이브러리를 사용하여 손글씨 분류를 학습하는 구체적인 신경망 예제를 살펴보자.
- 문제 설명
- 흑백 손글씨 숫자 이미지를 10개의 범주(0~9)로 분류하는 문제
- mnist 데이터셋 사용
- 6만개의 훈련 이미지와 1만개의 테스트 이미지로 구성된 데이터셋

* 머신러닝에서 분류문제의 범주 category 는 "클래스(class)"라 하고, 데이터 포인트는 "샘플"이라 하고, 특정 샘플의 클래스는 "레이블(label)"이라 한다.
1. 케라스에서 MNIST 데이터셋 적재하기
from keras.datasets import mnist
(train_images, train_labels), (test_images, tests_labels)2.
- train_images와 train_labels가 모델이 학습해야할 훈련 세트를 구성한다. 모델은 이 두개로 구성된 테스트셋에서 테스트될 것이다.
- 이미지는 넘파이 배열로 인코딩 되어 있고, 레이블은 0부터 9까지의 숫자 배열이다.
- 텐서(tensor)라 부르는 다차원 넘파이 배열에 데이터를 저장하는 것부터 시작
- 머신러닝 시스템 대부분 일반적으로 텐서를 기본 데이터 구조로 사용한다.
- 텐서는 머신러닝의 기본 구성요소이고, 구글의 텐서플로 이름을 여기서 따왔다.
- 다음 장에서 텐서에 대해 이어서 설명
- 이미지와 레이블은 일대일 관계
훈련 데이터를 살펴보자.
train_image.shape
# (60000, 28, 28)
len(train_labels)
# 60000
train_labels
# array([5,0,4,,,5,6,8],dtype=uint8)테스트 데이터를 살펴보자.
test_images.shape
# (10000, 28, 28)
len(test_labels)
# 10000
test_labels
# array([7,2,1,,,4,5,6],dtype=uint8)다섯번째 샘플을 matplotlib 라이브러리를 사용해 확인해보자.
import matplotlib.pyplot as plt
digit = train_images[4]
plt.imshow(digit,cmap=plt.cm.binary)
plt.show()
3. 작업 순서는 다음과 같다.
- 먼저 훈련 데이터 train_images와 train_labels를 네트워크에 주입한다.
- 네트워크는 이미지와 레이블을 연관시킬 수 있도록 학습된다.
- 마지막으로 test_images에 대한 예측을 네트워크에 요청한다.
- 이 예측이 test_labels와 맞는지 확인한다.
- 신경망을 만들어보자.
from keraas import models
from keras import layers
network = models.Sequential()
network.add(layers.Dense(512,activation='relu',input_shape=(28*28,)))
network.add(layers.Dense(10,activation='softmax'))- 신경망의 핵심 구성요소는 일종의 데이터 처리 필터라고 생각할 수 있는 층 (layer) 이다.
- 즉, 층은 주어진 문제에 더 의미있는 표현을 입력된 데이터로부터 추출한다.
- 대부분의 딥러닝은 간단한 층을 연결하여 구성되어 있고, 점진적으로 데이터를 정제하는 형태를 띠고있다.
- 딥러닝 모델은 데이터 정체필터(층)가 연속되어 있는 데이터 프로세싱을 위한 여과기와 같다.
- 이 예에서는 조밀하게 연결된 (or fully connected) 신경망 층인 Dense 층 2개가 연속되어 있다.
- 2번째 (즉 마지막) 층은 10개의 확률점수가 들어있는 배열(모두 더하면1이다)을 반환하는 softmax 창이다.
- 각 점수는 현재 숫자 이미지가 10개의 숫자 클래스 중 하나에 속할 확률
- 신경망 훈련 준비를 마치기 위해서 컴파일 단계에 포함될 3가지가 더 필요
- 손실 함수 (loss function) : 훈련 데이터에서 신경망의 성능을 측정하는 방법
- 옵티마이저 (optimizer) : 입력된 데이터와 손실 함수를 기반으로 네타워크를 업데이트하는 메커니즘
- 훈련과 테스트 과정을 모니터링할 지표(metrics) : 여기서는 accuracy를 고려
컴파일 단계 코드
network.compile(optimizer = 'rmsprop', loss='categorical_crossentropy',metrics=['accuracy'])- 훈련 시작 전 데이터를 네트워크에 맞는 크기로 바꾸고, 모든 값을 0과1사이로 스케일 조정을 하자.
- ex. 앞서 훈련이미지는 [0,255] 사이의 값인 uint8 타입의 (60000,28,28)크기를 가진 배열로 저장되어 있는데,이 데이터를 0과 1사이의 값을 가지는 float32 타입의 (60000, 28*28) 크기인 배열로 바꾼다.
이미지 데이터 준비하기 코드
train_images = train_images.reshape((60000,28*28))
train_images = train_images.astype('float32').255
test_images = test_images.reshape((10000,28*28))
tests_images = test_images.astype('float32')/255- 또 레이블을 범주형으로 인코딩해야한다.
레이블 준비하기 코드
from keras.utils import to_categorical
train_labels = to_categorical(train_lables)
test_labels = to_categorical(test_labels)- 이제 신경망을 훈련시킬 준비가 되었다. 케라스에서는 fit 메소드로 학습시킴
network.fit(train_images,train_labels,epochs=5,batch_SIZE=128)
- 테스트 셋의 정확도는 97.8%로 나왔다. 훈련 세트 정확도보다 조금 낮은데, 훈련 정확도와 테스트 정확도가 다른 이유는 '과대적합' 때문이다.
2-2. 신경망을 위한 데이터 표현
- 위의 예제에서는 텐서(tensor)라 부르는 다차원 넘파이 배열에 데이터를 저장하는 것부터 시작했다.
- 텐서는 데이터를 위한 컨테이너이다.
- 거의 항상 수치형 데이터를 다루므로, 숫자를 위한 컨테이너이다.
- '행렬'은 2D텐서이다. 즉, 텐서는 임의의 차원 개수를 가지는 행렬의 일반화된 모습
- 텐서에서는 차원(dimension)을 종종 축(axis)라고 부릅니다.
2.2.1 스칼라 (= 스칼라 텐서 = 0차원 텐서 = 0D 텐서)
- 하나의 숫자만 담고있는 텐서
- 넘파이에서는 float32나 float64 타입의 숫자가 스칼라 텐서 또는 배열 스칼라
- ndim 속성 사용시 넘파이 배열의 축 개수 확인 가능, 스칼라 텐서의 축 개수는 0이다. (ndim ==0)
- 텐서의 축 개수를 랭크(rank)라고도 부른다.
import numpy as np
x= np.array(12)
x
# array(12)
x.ndim
# 02.2.2 벡터(1D 텐서)
- 숫자의 배열을 벡터(1D텐서)라고 부른다. 1D텐서는 딱 하나의 축을 가진다.
x= np.array([12,3,6,14,7])
x
# array([12,3,6,14,7])
x.dim
# 1- 이 벡터는 5개의 원소를 갖고있으므로, 5차원 벡터라고 부른다 .(5D벡터인거지 5D텐서가 아님에 주의, 5D텐서는 축이 5개이다.)
- 차원수(dimensionality)는 특정 축을 따라 놓인 원소의 개수이거나, 텐서의 축 개수를 의미해서 혼동하기쉽다.
- '텐서의 축 개수가 5이다.' = '랭크가 5인 텐서이다.'
2.2.3 행렬(2D텐서)
- 벡터의 배열 = 행렬 또는 2D 텐서
- 행렬에는 2개의 축이 있다. (행row와 열column)
- 행렬은 숫자가 채워진 사각 격자
x = np.array([5,78,2,34,0],[6,79,3,35,1],[7,80,4,36,2]])
x.ndim
# 2- 첫번째 축에 놓여있는 원소를 행이라 부르고, 두번째 축에 놓여있는 원소가 열이다.
- 위의 예에서는 1번째 행이 [5,78,2,34,0]이고, 1번째 열이 [5,6,7] 이다.
2.2.4 3D텐서와 고차원 텐서
- 행렬들을 하나의 새로운 배열로 합치면 숫자가 채워진 직육면체 형태로 해석할 수 있는 3D텐서가 만들어진다.
X = np.array([[5,78,2,34,0],[6,79,3,35,1],[7,80,4,36,2]],[[5,78,2,34,0],
[6,79,3,35,1],[7,80,4,36,2]],[[5,78,2,34,0],[6,79,3,35,1],[7,80,4,36,2]]])
x.ndim
# 3- 3D텐서들을 하나의 배열로 합치면 4D 텐서를 만드는 식으로 이어진다.
- 딥러닝에서는 보통 0D에서 4D까지의 텐서를 다루고, 동영상 데이터를 다룰시 5D텐서까지 가기도함
2-3. 핵심 속성
텐서의 3가지 속성
- 축의 개수(랭크) : ex. 3D텐서에서는 3개의 축, 행렬에는 2개의 축이 있고, ndim으로 확인 가능
- 크기(shape) : 텐서의 각 축을 따라 얼마나 많은 차원이 있는지를 나타낸 파이썬의 튜플
- 바로 위의 예제에서 3D텐서의 크기는 (3,3,5)이다.
- 데이터 타입 : dtype, 텐서의 타입은 float32, uint8, float64등이 될 수 있다. 드물게 char타입도 사용한다.
- 텐서는 사전에 할당되어 연속된 메모리에 저장되어야 하므로, 넘파이 배열 (그리고 대부분 다른 라이브러리는) 가변길이의 문자열을 지원하지 않음
from keras.datasets import mnist
(train_images,train_labels), (test_images, test_labels)
# ndim으로 축의 개수 확인
print(train_images.ndim)
# 3
# shape으로 배열의 크기 확인
# (6000,28,28)
# dtype으로 데이터 타입 확인
print(train_images.dtype)
# unit8- 이 배열은 8비트 정수형 3D텐서이다. 28 X 28 크기의 정수 행렬 6만개가 있는 배열
- 하나의 흑백이미지이고, 행렬의 각 원소는 0에서 255 사이의 값을 가짐
넘파이로 텐서 조작하기
- 이전 예제에서 train_images[i] 와 같은 형식으로 첫번째 축을 따라 특정 숫자를 선택하였다.
# 슬라이싱
# 11번째에서 101번째까지(101번째는 포함X) 숫자를 선택하여 (90,28,28)크기의 배열을 만들자.
my_slice = train_imagse[10:100]
print(my_slice.shape)
# (90,28,28)# 각 배열의 축을 따라 슬라이싱의 시작 인덱스와 마지막 인덱스를 지정하자.(좀더 자세한 표기법)
my_slice train_images[10:100, : , : ]
my_slice.shape
# (90,28,28)
my_slice = train_images[10:100, 0:28, 0:28]
my_slice.shape
# (90,28,28)- 일반적으로 각 배열의 축을 따라 어떤 인덱스 사이도 선택할 수 있다.
14x14 픽셀을 선택하고자 한다면
my_slice = train_images[ : , 14: , 14: ]# 음수 인덱스
my_slice = train_iimages[ : , 7:-7, 7:-7]배치 데이터
- 일반적으로 딥러닝에서 사용하는 모든 데이터 텐서의 1번째 축은 샘플축이다. (샘플 차원이라고도 부름)
- 즉, MNIST 예제에서는 숫자 이미지가 샘플이다.
- 딥러닝 모델은 한번에 전체 데이터셋을 처리하지 않고, 그 대신에 데이터를 작은 배치(batch)로 나눈다.
#MNIST 숫자 데이터에서 크기가 128인 배치 하나는 다음과 같다.
batch = train_images[:128]
# 그 다음 배치
batch = train_images[128:256]
# n번째 배치
batch = train_images[128*n:128*(n+1)]- 이런 배치 데이터를 다룰 때에는 첫번째 축(=0번 축)을 배치 축 또는 배치차원이라 부른다.
텐서의 실제 사례
- 앞으로 사용할 데이터는 다음 중 하나에 속한다.
- 벡터 데이터 (samples, features) 크기의 2D텐서
- 시계열 데이터 또는 시퀀스 데이터 (samples, timesteps, features) 크기의 3D 텐서
- 이미지 (samples, height, width, channels) 또는 (samples, channels, height, width) 크기의 4D텐서
- 동영상 (samples, frames, height, weight, channels) 또는 (samples, frames, height, weight, channels) 크기의 5D텐서
벡터 데이터
- 데이터셋에서는 하나의 데이터 포인트가 인코딩될 수 있으므로, 배치 데이터는 2D텐서로 인코딩 된다. (벡터배열)
- 첫번째 축은 샘플 축, 두번째 축은 특성 축
- ex. 사람의 나이, 우편 번호, 소득으로 구성된 인구 통계 데이터에서 각 사람은 3개의 값을 가진 벡터로 구성되고, 10만명이 포함된 전체 데이터셋은 (10000,3) 크기의 텐서에 저장될 수 있다.
- ex. 공통단어 2만개로 만든 사전에서 각 단어가 등장한 횟수로 표현된 텍스트 문서 데이터셋, 각 문서는 2만개의 원소(사전에 있는 단어마다 하나의 원소에 대응)를 가진 벡터로 인코딩될 수 있다.500개의 문서로 이루어진 전체 데이터셋은 (500,20000)크기의 텐서로 저장된다.
시계열 데이터 또는 시퀀스 데이터
- 데이터에서 시간이(또는 연속된 순서가) 중요할 때에는 시간 축을 포함하여 3D텐서로 저장된다.
- 각 샘플은 벡터(2D 텐서)의 시퀀스로 인코딩되므로 배치 데이터는 3D텐서로 인코딩 된다.
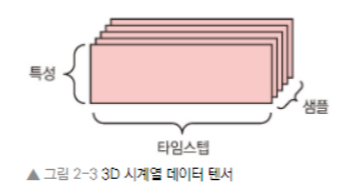
- 관례적으로 시간 축은 항상 두 번째 축(인덱스가 1인 축)이다.
- ex. 주식 가격 데이터셋 : 1분마다 현재 주식 가격, 지난 1분 동안에 최고 가격과 최소 가격 저장, 1분마다 데이터는 3D 벡터로 인코딩되고, 하루 동안의 거래는 (390,3) 크기의 2D텐서로 인코딩된다.(하루의 거래시간은 390분). 250일치의 데이터는 (250,390,3) 크기의 3D텐서로 저장될 수 있다. 여기에서 1일치 데이터가 1개의 샘플이 됨.
- ex. 트윗 데이터셋 : 각 트윗은 128개의 알파벳으로 구성된 280개의 문자 시퀀스, 각 문자가 128개의 크기인 이진 벡터로 인코딩될 수 있다.(해당 문자의 인덱스만 1이고, 나머지는 모두0인 벡터) 그러면 각 트윗은 (280,128) 크기의 2D텐서로 인코딩될 수 있다. 100만개의 트윗으로 구성된 데이터셋은 (1000000,280,128) 크기의 텐서에 저장된다.
이미지 데이터
- 이미지는 높이, 너비, 컬러 채널의 3차원으로 이루어짐.
- 앞서 본 MNIST 숫자처럼 흑백 이미지는 하나의 컬러 채널만을 가지고있어 2D텐서로 저장될 수 있지만, 관례상 이미지 텐서는 항상 3D로 저장된다.
- 256 X 256 크기의 흑백 이미지에 대한 128개의 배치는 (128,256,256,1) 크기의 텐서에 저장될 수 있다.
- 컬러 이미지에 대한 128개의 배치라면 (128,256,256,3) 크기의 텐서에 저장될 수 있다.
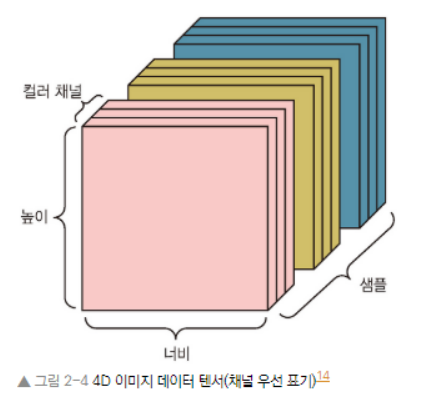
- 이미지 텐서의 크기를 지정하는 방식은 2가지이다. (컬러 채널의 깊이(color_depth)의 위치에 따라서)
- 텐서 플로에서 사용하는 채널 마지막(channel-last) 방식
- 텐서플로 머신러닝 프레임워크는 (sample, height, width, color_depth) 처럼 컬러 채널의 깊이를 끝에 놓는다.
- 씨아노에서 사용하는 채널 우선(channel-first) 방식
- 씨아노는 (sample, color_depth, height, width)처럼 컬러 채널의 깊이를 배치 축 바로 뒤에 놓는다.
- 씨아노 예를 사용하면 위의 이미지 예는 (128,1,256,256)과 (128,3,256,256)이 된다.
- 텐서 플로에서 사용하는 채널 마지막(channel-last) 방식
비디오 데이터
- 비디오 데이터는 현실에서 5D텐서가 필용한 몇 안되는 데이터 중 하나이다.
- 하나의 비디오는 프레임의 연속이며, 각각의 프레임은 하나의 컬러 이미지
- 프레임이 (height, width, color_depth)의 3D텐서로 저장될 수 있기 때문에 프레임의 연속은 (frames, height, width, color_depth)의 4D텐서로 저장될 수 있다.
- ex. 60초짜리 144x256 유튜브 비디오 클립을 초당 4프레임을 샘플링하면, 240프레임이 된다. 이런 비디오 클립을 4개 가진 배치는 (4,240,144,256,3) 크기의 텐서에 저장됨. 이 텐서의 dtype을 float32로 했다면, 각 값이 32비트로 저장될 것이므로, 텐서의 저장크기는 405MB가 된다.
- 실생활에서 접하는 비디오는 float32로 저장되지 않기 때문에 훨씬 용량이 적고, 압축률도 높다.
2-3. 신경망의 톱니바퀴 - 텐서 연산
- 컴퓨터 프로그램을 이진수의 입력을 처리하는 연산 (and, or, nor ..)으로 표현하는 것처럼, 심층 신경망이 학습한 모든 변환을 수치 데이터 텐서에 적용하는 몇 종류의 텐서 연산으로 나타낼 수 있다. ex. 텐서 덧셈이나 텐서 곱셈
케라스의 층을 다음과 같이 생성하자.
keras.layers.Dense(512,activation='relu')- 이 층은 2D 텐서를 입력으로 받고, 입력 텐서의 새로운 표현인 또 다른 2D 텐서를 반환하는 함수처럼 해석할 수 있음
위 함수를 구체적으로 보면
output = relu(dot(W,input)+b)- W는 2D텐서고, b는 벡터이다. 둘 모두 층의 속성
- 좀 더 자세히 보면 여기에는 텐서 연산이 3가지가 있다.
- 1) 점곱(dot), 2) 결과와 벡터b와의 덧셈, 3) 렐루연산 *relu(x)=max(x,0))
2-3-1. 원소별 연산(element-wise operation)
- relu 함수와 덧셈은 원소별 연산이다.
- 이 연산은 텐서에 있는 각 원소에 독립적으로 적용된다.
- 이 말은 고도의 병렬 구현(*병렬 구현은 벡터화된 구현을 의미)이 가능한 연산이라는 의미이다.
- 파이썬으로 단순 원소별 연산을 구현한다면, 다음의 relu 연산 구현처럼 for 반복문 사용
def naive_relu(x):
assert len(x.shape) == 2 # x는 2D 넘파이 배열
x = x.copy()
for i in range(x.shape[0]):
for j in range(x.shape[1]):
x[i,j] = max(x[i,j],0)
return x
## 덧셈도 동일
def naive_add(x,y):
assert len(x.shape) == 2
assert x.shape == y.shape
x = x.copy()
for i in range(x.shape[0]):
for j in range(x.shape[1]):
x[i,j] += y[i,j]
return x- 넘파이 배열 ndarray를 다룰 떄에는 최적화된 넘파이 내장 함수로 이런 연산들을 처리할 수 있다.
import numpy as np
z = x + y #원소 덧셈
z = np.maximum(z,0.) #원소별 렐루 함수2-3-2. 브로드캐스팅
- 단순 덧셈 구현인 naive_add는 동일 크기의 2D텐서만 지원한다. 하지만 이전에 보았던 Dense층에서는 2D텐서와 벡터를 더했다. 크기가 다른 두 텐서가 더해질 때에는 모호하지 않고 실행 가능하다면, 작은 텐서가 큰 텐서의 크기에 맞추어 "브로드캐스팅"된다.
- 큰 덴서의 ndim에 맞도록 작은 텐서에 브로드캐스팅 축이라고 부르는 축이 추가됨
- 작은 텐서가 새 축을 따라서 큰 텐서의 크기에 맞도록 반복된다.
- 예시
- x의 크기는 (32,10) , y의 크기는 (10,)이다.
- y에 비어있는 첫번째 축을 추가하여, 크기를 (1,10)으로 만든다.
- y를 이 축에 32번 반복하면 텐서 Y의 크기는 (32,10)이 된다.
- 여기에서 Y[i, : ] == y for i in range(0,32) 이다. 이제 X와 Y의 크기가 같으므로 더할 수 있다.
- 구현 입장에서는 새로운 텐서가 만들어지면 비효율적이라 어떤 2D텐서도 만들어지지 않는다.
- 반복된 연산은 완전히 가상적, 과정이 메모리 수준이 아니라 알고리즘 수준에서 일어남
- 하지만 새로운 축을 따라 벡터가 32번 반복된다고 생각하는 것이 이해하기 쉽다.
def naive_add_matrix_and_vector(x,y):
assert len(x.shape) == 2 # x는 2D 넘파이 배열
assert len(y.shape) == 1 # y는 넘파이 벡터
assert x.shape[1] == y.shape[0]
x = x.copy() # 입력 텐서자체를 바꾸지 않도록 복사한다.
for i in range(x.shape[0]):
for j in range(x.shapep[1]):
x[i,j] += y[j]
return x- (a,b,...n,n+1,....m) 크기의 텐서와 (n,n+1,...m) 크기의 텐서 사이에 브로드캐스팅으로 원소별 연산을 적용할 수 있다.
- 브로드캐스팅은 a부터 n-1까지의 축에 자동으로 일어난다.
다음은 크기가 다른 두 텐서에 브로드캐스팅으로 원소별 maximum 연산을 적용하는 예이다.
import numpy as np
x = np.random.random((64,3,32,10)) # x는 (64,3,32,10) 크기의 랜덤 텐서
y = np.random.random((32,10)) # y는 (32,10)크기의 랜덤 텐서
z = np.maximum(x,y) # 출력 z크기는 x와 동일하게 (64,3,32,10)2.3.3 텐서 점곱
- 원소별 곱셈과 다르다. 가장 널리 사용되는 텐서 연산으로, 원소별 연산과 반대로 입력 텐서들의 원소들을 결합시킴
- 넘파이, 케라스, 씨아노, 텐서플로에서는 원소별곱셈으로 * 연산자를 사용하고, 그 중 넘파이와 케라스는 점곱 연산에 보편적 dot 연산자 사용
벡터 x와 y의 점곱
def naive_vector_dot(x,y):
assert len(x.shape) == 1
assert len(y.shape) == 1
assert x.shape[0] == y.shape[0]
z = 0.
for i in range(x.shape[0]):
x += x[i] * y[i]
return z- 두 벡터의 점곱은 스칼라가 되므로, 원소 개수가 같은 벡터끼리 점곱이 가능하다.
- 행렬x와 벡터 y사이에서도 점곱이 가능하다. y와 x의 행 사이에서 점곱이 일어나므로 벡터가 반환된다.
import numpy as np
def naive_matrix_vector_dot(x,y):
assert len(x.shape) == 2 # x는 넘파이 행렬
assert len(y.shape) == 1 # y는 넘파이 벡터
assert x.shape[1] == y.shape[0] # x의 두번째 차원이 y의 첫번째 차원과 같아야함
z = np.zeros(x.shape[0]) # 이 연산은 x의 행과 같은 크기의 0이 채워진 벡터를 만든다.
for i in range(x.shape[0]):
for j in range(x.shape[1]):
z[i] += x[i,j] * y[j]
return z행렬과 벡터의 점곱, 벡터와 벡터의 점곱 사이의 관계를 보여주기위해 위의 함수를 다시 사용해보자.
def naive_matrix_vector_dot(x,y):
z = np.zeros(x.shape[0])
for i in range(x.shape[0]):
z[i] = naive_vector_dot(x[i, : ], y)
return z- dot(x,y)와 dot(y,x)는 같지 않다. (↔두 텐서 중 하나라도 ndim이 1보다 크면, dot 연산에 교환법칙이 성립x)
- 점곱은 임의의 축 개수를 가진 텐서에 일반화된다. 가장 일반적인 용도는 두 행렬간의 점곱이다.
- x.shape[1] == y.shape[0] 일 때 두 행렬 x와 y의 점곱(dot(x,y))이 성립된다. (ndim이 1보다 작으니 괜찮)
- x의 행과 y의 열 사이 벡터 점곱으로 인해 (x.shape[0], y.shape[1]) 크기의 행렬이 된다.
x.shape[1] == y.shape[0] 일때 두 행렬의 점곱 구현 예시
def naive_matrix_dot(x,y):
assert len(x.shape) == 2
assert len(y.shape) == 2
assert len(x.shape) == 2 # x와 y는 넘파이 행렬
assert len(y.shape) == 2
assert x.shape[1] == y.shape[0] # x와 두번째 차원이 y의 첫번째 차원과 같아야한다.
z = np.zeros((x.shape[0], y.shape[1])) # 이 연산은 0이 채워진 특정 크기의 벡터를 만듦
for i in range(x.shape[0]): # x의 행을 반복
for j in range(y.shape[1]): # y의 열을 반복
row_x = x[i, : ]
column_y = y[ : , j]
z[i,j] = naive_vector_dot(row_x,column_y)
return z
- x,y,z는 직사각형 모양으로 그려져 있다. (각 직사각형을 원소들이 채워진 박스라고 생각)
- x의 행 벡터와 y의 열 벡터가 같은 크기여야하므로, 자동으로 x의 너비는 y의 높이와 동일해야한다.
- 더 일반적으로는 앞서 설명한 2D의 경우처럼 크기를 맞추는 동일한 규칙을 따르면 다음과 같은 고차원 텐서 간의 접곰을 할 수 있다.

2-3-4. 텐서 크기 변환 (reshape, transpose)
- 신경망에 주입할 숫자 데이터를 전처리할 때 사용한다.
train_images = train_images.reshape((60000,28*28))- 텐서의 크기를 변환한다는 것은 특정 크기에 맞게 열과 행을 재배열한다는 뜻이다. 원소개수는 재배열해도 당연히 동일하다.
크기변환 예제 코드
x = np.array([[0.,1.],[2.,3.],[4.,5.]])
print(x.shape)
# (3,2)
x
# ([ 0.], [ 1.], [ 2.], [ 3.], [ 4.], [ 5.]])
x = x.reshape((2,3)))
x
# array([[0., 1., 2.],[ 3., 4., 5.]])자주사용하는 특별한 크기 변환 - 전치
x = np.zeros((300,20))
x = np.transpose(x)
print(x.shape)
(20,300)2.3.5 텐서 연산의 기하학적 해석
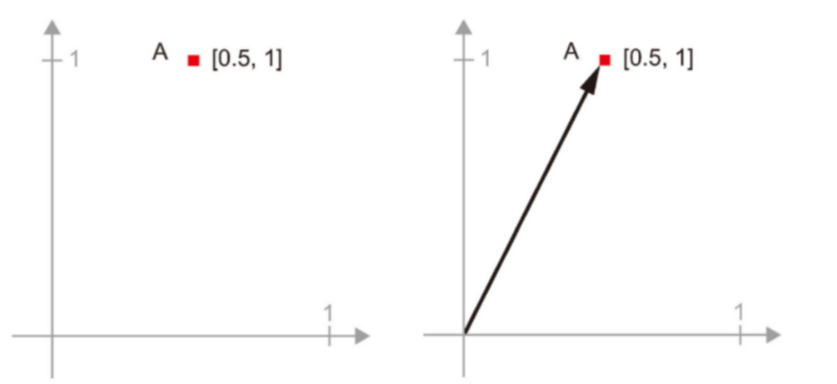
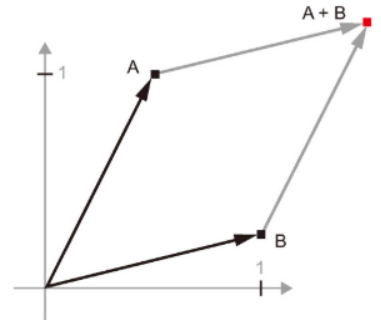
- 벡터 A=[0.5,1]은 2D공간에 있다. 새로운 포인트 B=[1,0.25]를 이전 벡터에 더할 시 최종위치는 아래 그림처럼 두 벡터를 나타내는 백터가 된다.
- 일반적으로 아핀 변환(affine transformation), 회전, 스케일링과 같은 기본적인 기하학적 연산은 텐서연산으로 표현 가능
- 예를 들어, theta 각도로 2D벡터를 회전하는 것은 2X2 행렬 R=[u,v]를 점곱하여 구현할 수 있다. 여기에서 u,v는 동일 평면상의 벡터이며, u=[cos(theta), sin(theta)]고 v=[-sin(theta), cos(theta)]이다.
2.3.6 딥러닝의 기하학적 해석
- 신경망은 전체적으로 텐서 연산의 연결로 구성된 것이고, 모든 텐서 연산은 입력 데이터의 기하학적 변환이다. 따라서 단순한 단계들이 길게 이어져 구현된 신경망을 고차원 공간에서 매우 복잡한 기하학적 변환을 하는 것으로 해석할 수 있다.
- 각각 하나의 빨간색, 파란색 색종이가 있다고 가정해보자. 두 장을 겹친 다음 뭉쳐서 작은 공으로 만들자. 이 중 '공'이 입력데이터, '색종이'는 분류 문제의 클래스이다. 신경망(또는 다른 머신러닝 알고리즘)이 해야할 일은 종이 공을 펼쳐서 두 클래스가 다시 깔끔하게 분리되는 변환을 찾는 것이다. 딥러닝을 사용하여 3D공간에서 간단한 변환들을 연결해서 이를 구현한다.
- 종이 공을 펼치는 것이 머신러닝이 하는 일이다. 복잡하고 심하게 꼬여있는 데이터의 manifold에 대한 깔끔한 표현을 찾는 일이다. 기초적 연산을 길게 연결하여 기하학적 변환을 조금씩 분해하는 방식이 사람이 종이 공을 펼치기위한 전략과 흡사하다. 심층 네트워크의 각 층은 데이터를 조금씩 풀어주는 변환을 적용하므로, 이런 층을 깊게 쌓으면 아주 복잡한 분해과정을 처리할 수 있다.
2.4 신경망의 엔진 : 그래디언트 기반 최적화
- 이전에 본 예제에서 각 층은 입력데이터를 다음과 같이 반환하였다.
- output = relu( dot ( W, input ) + b )
- 이 식에서 텐서 W와b는 층의 속성 or 가중치 or 훈련되는 파라미터 라고 부르며, W는 커널, b는 편향이라 부른다.
- 그리고 이런 가중치에는 훈련 데이터를 신경망에 노출시켜서 학습된 정보가 담겨있다.
- 무작위 초기화 (random initialization): 초기에는 가중치 행렬이 작은 난수로 채워져있다.
- W와b가 난수일 때, relu(dot(W,input)+b)가 유용한 어떤 표현을 만들 것이라 기대할 수 없다. 처음에는 의미없는 표현이 만들어질 것이다. 하지만 피드백 신호에 기초하여 가중치가 점진적으로 조정되고, 점진적인 조정 또는 훈련이 머신러닝 학습법의 핵심이다.
- 훈련의 반복 루프
- 훈련 샘플 x와 이에 상응하는 타킷 y의 배치 추출
- x를 사용하여 네트워크 실행 (=forward pass 정방향 패스 단계), 예측 y_pred를 구한다.
- y_pred와 y의 차이를 측정하여 이 배치에 대한 네트워크의 손실을 계산한다.
- 배치에 대한 손실이 조금 감소되도록 네트워크의 모든 가중치 업데이트
- 1단계는 단순 입출력 코드 / 2-3단계는 몇 단계의 텐서 연산을 적용하기만 하면됨 / 4단계가 복잡한 부분이다. 네트워크의 가중치를 업데이트하는 단계로, 개별적인 가중치값이 있을 때 값이 증가해야할지 감소해야할지, 얼만큼 업데이트해야할지 아는 방법은,
- 네트워크 가중치 행렬의 원소를 모두 고정, 관심있는 하나만 다른 값 적용 ex. 가중치 초깃값이 0.3이라고 가정, 배치 데이터를 정방향 데이터에 통과시킨 후 네트워크의 손실이 0.5가 나왔다면, 이 가중치 값을 0.35로 변경하고, 다시 정방향 패스를 실행했더니 손실이 0.6으로 증가, 반대로 0.25로 줄이면 손실이 0.4로 감소하였다. 이 경우, 가중치를 -0.05만큼 업데이트한 것이 손실을 줄이는데 기여한 것
- 위의 접근방식은 모든 가중치 행렬의 원소마다 두번의 정방향 패스를 계산해야해서 엄청나게 비효율적
- 신경망에 사용되는 모든 연산이 미분 가능하다는 장점을 사용하여 네트워크 가중치에 대한 손실의 그래디언트를 계산하는 것이 더 좋은 방법이다. 그래디언트의 반대방향으로 가중치를 이동할시 손실이 감소됨
- 즉, 훈련 데이터에서 네트워크의 손실(y_pred와 타깃 y의 오차)이 매우 작아질 것이다. 이 네트워크는 입력에 정확한 타깃을 매핑하는 것을 학습한다.
2.4.1 변화율이란?
- 연속적 함수에서는 x를 조금 바꾸면, y가 조금만 변경될 것이다. f ( x + epsilon_x ) = y + epsilon_y
- 또한, epsilon_x가 충분히 작다면, 어떤 포인트 p에서 기울기 a의 선형 함수로 f를 근사할 수 있다. epsilon_y는 a * epsilon_x가 된다.
- 이 선형적인 근사는 x가 p에 충분히 가까울 때 유효하다.
- 이 기울기를 p에서 f의 변화율이라 함
- 모든 미분 가능한(=변화율을 유도할 수 있는) 함수 f(x)에 대해서 x의 값을 f의 국부적인 선형 근사인 그 지점의 기울기로 매핑하는 변화율 함수가 존재, f(x)를 최소화하려면 epsilon_x만큼 x를 업데이트하고 싶을 때, f의 변화율만 알고있으면 된다.
2.4.2 텐서 연산의 변화율 : 그래디언트
- 그래디언트 = 텐서 연산의 변화율
- 다차원 입력, 즉 텐서를 입력으로 받는 함수에 변화율 개념을 확장시킨 것
- 입력 벡터 x / 행렬 W / 타깃 y / 손실 함수 loss가 있을 때,
- W를 사용하여 타깃의 예측 y_pred를 계산하고 손실(타깃 예측 y_pred와 타깃 y사이의 오차)을 계산할 수 있다.
- 입력 데이터 x,y가 고정되어있다면, 이 함수는 W를 손실 값에 매핑하는 함수 loss_value = f(W)
- 포인트 W0에서 f의 변화율은 W와 같은 크기의 텐서인 gradient(f)(W0) 이다.
- 이 텐서의 각 원소 gradient(f)(W0)[i,j]를 변경할시, loss_value가 바뀌는 방향과 크기를 나타낸다.
- 즉, 텐서 gradient (f)(w0)가 W0에서 함수 f(W) = loss_value의 그래디언트이다.
- f(x)의 변화율이 f의 기울기였듯이, gradient(f)(w0)는 w0에서 f(w)의 기울기를 나타내는 텐서이다.
- 따라서, 변화율 반대방향으로 x를 움직이면 f(x)의 값을 감소시킬 수 있듯이, 함수 f(w)입장에서는 그래디언트 반대방향으로 W를 움직이면 f(w)의 값을 줄일 수 있다. → W1 = W0 - step * gradient(f)(w0) [step은 스케일 조정값]
- 위 식의 의미는 기울기가 작아지는 곡면의 낮은 위치로 이동된다는 의미이다.
- gradient(f)(w0)는 w0에 아주 가까이 있을 때 기울기를 근사한 것이므로, w0에서 크게 벗어나지 않기 위해서 스케일링 비율 step이 필요한 것
2.4.3 확률적 경사 하강법
- 미분 가능 함수가 주어지면,, 이 함수의 최솟값은 변화율이 0인 지점이다. 따라서 변화율이 0이 되는 지점을 모두 찾고, 그 중 어떤 포인트의 함수값이 가장작은지 확인
- 신경망에 적용시 가장 작은 손실 함수의 값을 만드는 가중치의 조합을 해석적으로 찾는 것을 의미
- 식 gradient(f)(w) = 0 만 풀면 해결 가능
- 위 식은 N개의 변수로 이루어진 다항식이며, N은 네트워크 가중치 개수이다.
- N=2 , N=3인 식을 푸는건 가능할지몰라도, 수천 수만개로 많기 때문에 해석적으로 해결 x
- 그래서 대신에 앞서 설명한 알고리즘 4단계를 사용하는 것 (파라미터의 점진적인 수정)
- 미니 확률적 경사 하강법 (mini - batch stochastic gradient descent)
- 확률적 의미는 각 배치 데이터가 무작위로 선택된다는 의미 (확률적=무작위)
- 훈련 샘플 배치x와 상응하는 타깃 y 추출
- x로 네트워크 실행, 예측 y_pred 구하기
- y_pred와 y사이의 오차 측정, 네트워크의 손실 계산
- 네트워크 파라미터에 대한 손실함수의 그래디언트 계산 (역방향 패스)
- 그래디언트의 반대 방향으로 파라미터를 조금씩 이동시킴 (손실이 조금씩 감소할 것!)
- 네트워크 파라미터와 훈련샘플이 하나일 때 아래의 과정이 나타난다.
- 확률적 의미는 각 배치 데이터가 무작위로 선택된다는 의미 (확률적=무작위)
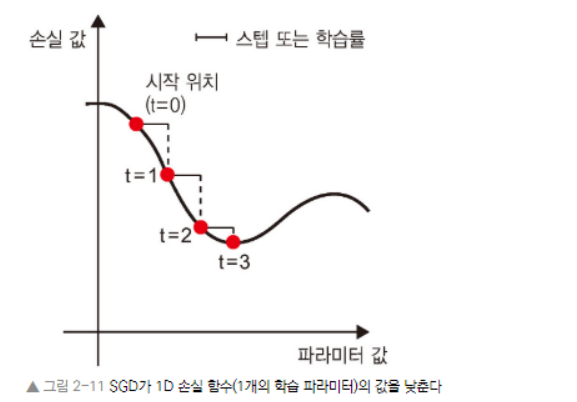
* SGD : 확률적 경사하강법 (Stochastic Gradient Descent)
- 그림에서 알 수 있듯이, step값을 적절히 고르는 것이 중요하다.
- step이 작으면 너무 많은 반복이 필요하고, 지역 최솟값(local minimum)에 갇힐 수 있다.
- step이 너무 크면 손실 함수 곡선에서 완전히 임의의 위치로 이동시킬 수 있다.
- 위의 그림은 1D 파라미터 공간에서 경사 하강법을 설명하고 있지만, 실제로는 매우 고차원 공간에서 경사 하강법을 사용하게되며, 신경망에 있는 각각 가중치 값은 이 공간에서 하나의 독립된 차원이고 수만개가 될 수 있다.
- 아래의 그림은 SGD를 시각화 해본 것
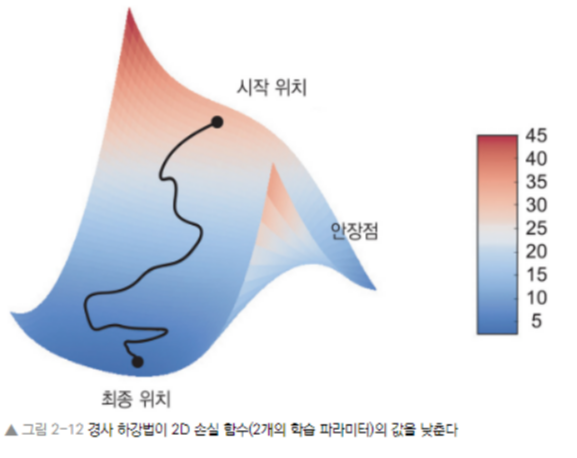
- 업데이트할 다음 가중치 계산시 사용되는 다른 방식 (SGD 변증 - 모멘텀을 사용한 SGD, Adagrad, RMSProp
- 이런 변증들은 최적화 방법 or 옵티마이저라 부름
- *모멘텀 : SGD에 있는 2개의 문제점인 수렴 속도와 지역 최솟값을 해결한다.
- 아래의 그림은 네트워크 파라미터 하나에 대한 손실 값의 곡선을 보여줌

- 위 그림을 보면, 어떤 파라미터 값에서는 지역 최솟값에 도달하고, 그 지점에서는 왼쪽으로 이동해도, 오른쪽으로 이동해도 손실이 증가하게 된다. 대상 파라미터가 작은 학습률을 가진 SGD로 최적화되었다면 최적화 과정이 전역 최솟값으로 향하지 못하고, 지역 최솟값에 갇히게 될 것
- 여기서 최적화 과정을 손실 곡선 위로 작은 공을 굴리는 것으로 생각해보자.
- 모멘텀이 충분하면, 공이 골짜기에 갇히지 않고 "전역 최솟값"에 도달할 것이다.
- 모멘텀은 현재 기울기 값(현재 가속도) 뿐만 아니라, (과거의 가속도로 인한) 현재 속도를 함께 고려하여 각 단계에서 공을 움직인다. ↓같은 원리로,
- 실전에 적용시 현재 그래디언트 값 뿐만 아니라, 이전에 업데이트한 파라미터에 기초하여 파라미터 w를 업데이트 한다.
단순 구현 예시
past_velocity = 0.
momentum = 0.1 # 모멘텀 상수
while loss > 0.01:
w, loss, gradient = get_current_parameters()
velocity = momentum, * past_velocity - learning_rate * gradient
w = w + momentum * velocity - learning rate * gradient
past_velocity = velocity
update_parameter(w)2.4.4 변화율 연결 : 역전파 알고리즘
- 연쇄법칙 (chain rule) : 다음 항등식 f(g(x))' = f'(g(x)) * g'(x) 를 사용하여 유도될 수 있다.
- 연쇄법칙을 신경망의 그래디언트 계산에 적용하고 이를 '역전파 알고리즘(=후진 모드 자동 미분)'이라고 부른다.
- 역전파는 최종 손실 값에서부터 시작한다. 손실값에 따라서 각 파라미터가 기여한 정도를 계산한다. 그 과정에서 연쇄법칙을 적용하여 최상위 층에서 하위 층까지 거꾸로 진행
- 변화율이 알려진 연산들로 연결되어 있을시, 연쇄법칙을 적용하여 네트워크 파라미터와 그래디언트 값을 매핑하는 그래디언트 함수를 계산할 수 있다.
- 이런 함수 사용시 역방향 패스는 그래디언트 함수를 호출하는 것으로 단순화될 수 있다.
- 기호 미분 덕분에 역전파 알고리즘을 구현할 필요도 없고, 정확한 역전파 공식을 유도할 필요도 없다.
2.5 첫번째 예제 다시 살펴보기
입력 데이터
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000,28*28))
train_images = train_images.astype('float32')/255
test_images = test_images.reahpe((10000,28*28))
test_images = test_images.astype('float32')/255사용할 신경망
network = model.Sequential()
network.add(layers.Dense(512,activation = 'relu', input_shape = (28*28,)))
network.add(layers.Dense(10, activation = "softmax'))네트워크 컴파일 단계
network.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])- cateogrical_crossentropy : 손실함수, 가중치 텐서를 학습하기 위한 피드백 신호로 사용되며, 훈련하는 동안 최소화됨
- 미니 배치 확률적 경사 하강법을 통해 손실이 감소됨
- 경사 하강법을 적용하는 구체적인 방식은 첫번째 매개변수로 전달된 rmsprop 옵티마이저에 의해 결정됨
마지막으로 훈련 반복
network.fit(train_images, train_labels, epochs=5, batch_size=128)- fit 메소드 호출시, 네트워크가 128개 샘플씩 미니 배치로 훈련 데이터를 5번 반복한다. ( 각 반복을 에포크epoch라 함)
- 각 반복마다 네트워크가 배치에서 손실에 대한 가중치의 그래디언트를 계산하고, 그에 맞추어 가중치 업데이트
- 다섯번의 에포크 동안 2,345번의 그래디언트 업데이트를 수행할 것 (에포크마다 469번)
- 아마 네트워크 손실이 충분히 낮아져 높은 정확도로 손글씨 숫자를 구분할 수 있을 것이다.
2.6 요약
- 학습 : 훈련 데이터 샘플과 그에 상응하는 타깃이 주어졌을 때, 손실함수를 최소화하는 모델 파라미터의 조합을 찾는 것
- 데이터 샘플과 타깃의 배치를 랜덤하게 뽑고 이 배치에서 손실에 대한 파라미터의 그래디언트를 계산함으로써 학습이 진행되며, 네트워크 파라미터는 그래디언트 반대 방향으로 조금씩(학습률에 의해 정의된 크기만큼) 움직인다.
- 전체 학습 과정은 신경망이 미분 가능한 텐서 연산으로 연결되어 있기에 가능하다. 현재 파라미터와 배치 파라미터를 그래디언트 값에 매핑해주는 그래디언트 함수 구성을 위해 미분의 연쇄 법칙 사용
- 네트워크에 데이터를 주입하기 전 정의되어야하는 '손실'과 '옵티마이저'에 대해 보게 될 것
- 손실은 훈련하는 동안 최소화해야 할 양이므로, 해결하려는 문제의 성공을 측정하는데 사용한다.
- 옵티마이저는 손실에 대한 그래디언트가 파라미터를 업데이트 하는 정확한 방식을 정의한다. ex. RMSProp 옵티마이저, 모멘텀을 사용한 SGD
'데이터 분석 > 케라스 창시자에게 배우는 딥러닝' 카테고리의 다른 글
| [5] 케라스 창시자에게 배우는 딥러닝 - 5. 컴퓨터 비전을 위한 딥러닝( 합성곱 신경망 소개, MaxPooling, 고양이vs강아지 분류 예제, 데이터 증식) (0) | 2022.08.16 |
|---|---|
| [4] 케라스 창시자에게 배우는 딥러닝 - 4. (머신러닝) 분류, 특성 공학, 특성 학습, 과/소적합, 해결법(가중치 규제,드롭아웃 추가..) (1) | 2022.08.11 |
| [3,실습] 케라스 창시자에게 배우는 딥러닝 - 신경망 시작하기 (분류/회귀 문제 풀어보기 (1) | 2022.08.09 |
| [3] 케라스 창시자에게 배우는 딥러닝 - 신경망 시작하기(분류/예측 예제 풀어보기) (0) | 2022.08.08 |
| [1] 케라스 창시자에게 배우는 딥러닝 - 딥러닝의 기초 (이론) (0) | 2022.07.28 |



