
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- DENSE_RANK()
- 데이터 정합성
- 컨브넷
- sql
- 캐글 신용카드 사기 검출
- python
- ImageDateGenerator
- XGBoost
- 분석 패널
- 마케팅 보다는 취준 강연 같다(?)
- tableau
- 인프런
- splitlines
- 그룹 연산
- 데이터 증식
- WITH ROLLUP
- pmdarima
- Growth hacking
- 데이터 핸들링
- 그로스 해킹
- lightgbm
- WITH CUBE
- 로그 변환
- 그로스 마케팅
- 스태킹 앙상블
- 3기가 마지막이라니..!
- ARIMA
- 리프 중심 트리 분할
- 부트 스트래핑
- 캐글 산탄데르 고객 만족 예측
- Today
- Total
LITTLE BY LITTLE
[23] 추천 시스템 - 협업 필터링(Item to Item, User to Item 예제, 벡터 내적을 사용한 유사도, L2 정규화) 본문
[23] 추천 시스템 - 협업 필터링(Item to Item, User to Item 예제, 벡터 내적을 사용한 유사도, L2 정규화)
위나 2024. 4. 7. 11:01
목차
3. 데이터 가공을 위한 SQL 3-1. 하나의 값 조작하기 (5강) 3-2. 여러 개의 값에 대한 조작 (6강) 3-3. 하나의 테이블에 대한 조작 (7강)3-4. 여러 개의 테이블 조작하기 (8강)4. 매출을 파악하기 위한 데이터 추출 4-1. 시계열 기반으로 데이터 집계하기 (9강)4-2. 다면적인 축을 사용해 데이터 집약하기 (10강)5. 사용자를 파악하기 위한 데이터 추출 5-1. 사용자 전체의 특징과 경향 찾기 (11강) 5-2. 시계열에 따른 사용자 전체의 상태 변화 찾기 (12강) 5-3. 시계열에 따른 사용자의 개별적인 행동 분석하기 (13강)6. 웹사이트에서 행동을 파악하는 데이터 추출하기 6-1. 사이트 전체의 특징/경향 찾기 6-2. 사이트 내의 사용자 행동 파악하기 6-3. 입력 양식 최적화하기7. 데이터 활용의 정밀도를 높이는 분석 기술 7-1. 데이터를 조합해서 새로운 데이터 만들기 7-2. 이상값 검출하기 7-3. 데이터 중복 검출하기 7-4. 여러 개의 데이터셋 비교하기8. 데이터를 무기로 삼기 위한 분석 기술 8-1. 검색 기능 평가하기 8-2. 데이터 마이닝
8-3. 추천
8-4. 점수 계산하기
9. 지식을 행동으로 옮기기
9-1. 데이터 활용의 현장
※ Mysql 기준
8장. 데이터를 무기로 삼기 위한 분석 기술
23강. 추천
23-1. 추천 시스템의 넓은 의미
추천 시스템의 종류
- Item to Item: 아이템과 관련된 개별적인 아이템 제안 (ex. 이 상품을 본 사람들은 다음 상품도 조회)
- User to Item: 사용자 개인에 최적화된 아이템 제안 (ex. 특정 개인을 위한 추천 아이템)
- 특정 개인을 위한 추천 아이템이더라도, 사용자가 최근 구매한 아이템을 기반으로 다음 구매할 아이템을 추천하는 것이라면 Item to Item 추천
- 사용자 행동을 기반으로 흥미 기호를 추천하기 때문에 데이터가 적으면 흥미 기호를 제대로 판단할 수 없어 주의가 필요함
모듈의 종류
- 리마인드: 사용자 과거 행동을 기반으로 아이템을 다시 제안 (ex. 최근에 본 상품, 한 번 더 구매하기)
- 어려운 계산 로직을 사용하지 않더라도, '과거에 출력한 저보를 열람 이력으로 출력해주는 모듈'도 리마인드 목적의 추천 모듈이다.
- 순위: 열람 수, 구매 수 등을 기반으로 인기 있는 아이템을 제안 (ex. 인기 순위, 급상승 순위)
- 매출 또는 열람 수에서 상위를 차지하는 몇 개를 출력해주는 것도 순위를 사용한 추천이다.
- 계절을 중시하는 순위라면, 증가율을 정렬 점수로 사용하여 급상승 순위와 같은 모듈을 만들 수 있다. (10강3절)
- 콘텐츠 베이스: 아이템의 추가 정보를 기반으로 다른 아이템 추천 (ex. 해당 배우가 출연한 다른 제품)
- 추천: 서비스를 사용하는 사용자 전체의 행동 이력을 기반으로, 다음에 볼만한 아이템 또는 관련 아이템을 추측해 제안 (ex. 이 상품을 보았던 사람들은 이러한 상품도 함께 보았습니다)
- 개별 추천: 사용자 개인의 행동 이력을 기반으로 흥미 기호를 추측하고 흥미 있어 할 만한 아이템을 제안해주는 것
추천의 효과
- 다운셀: 가격이 높아 구매를 고민하는 사용자에게 더 저렴한 아이템을 제안해서 구매 수를 올리는 것 (ex. 이전 모델이 가격 할인을 시작했습니다.)
- ex. 작은 사이즈의 커피는 가격이 더 저렴합니다.
- 크로스셀: 관련 상품을 함께 구매하게 해서 구매 단가를 올리는 것 (ex. 함께 구매되는 상품이 있습니다.)
- 업셀: 상위 모델 또는 고성능의 아이템을 제안해서 구매 단가를 올리는 것 (ex. 이 상품의 최신 모델이 있습니다.)
- ex. 프렌치프라이 M→L 사이즈 변경 제안
이외에도 추천으로 얻을 수 있는 효과는 매우 많다. 사용자가 방문할 때의 이동률과 열람 수를 올리려면, 새로운 상품/인기 상품 이외에도 열람 수가 적은 상품을 추천해 새로운 발견(의외성)을 주어야 한다.
→ 추천 시스템 구축 시 그 목적을 명확하게 하는 것이 중요
데이터에 따라 얻을 수 있는 정밀도와 효과 차이
데이터의 명시적 획득과 암묵적 획득
- 암묵적 데이터 획득: 사용자의 행동을 기반으로 기호를 추측한다. (ex. 구매 로그, 열람 로그)
- 데이터 양이 많으나, 정확도가 떨어짐
- 상품 구매가 반드시 사용자의 기호와 이어지는지는 불분명하기 때문
- 사용자가 사생활 침해라고 여기는 경우도 있어 주의해야 함
- 명시적 데이터 획득: 사용자에게 직접 기호를 물어본다. (ex. 별점 주기)
- 데이터 양이 적지만, 정확도가 높음
열람 로그와 구매 로그의 차이
- 열람 로그: 특정 아이템과 유사한 아이템을 추천해서 사용자의 선택지를 늘릴 수 있음 (ex. 여행용 가방을 구매한다고 할 때, 크기, 형태, 색이 다른 것을 추천)
- 사용자의 행동을 기록한 열람 로그를 기반으로 유사 상품을 추천
- 구매 로그: 함께 구매 가능한 상품을 추천해서 구매 단가를 끌어올릴 수 있음 (ex. 여행용 가방을 구매한다고 할 때, 함께 구매하면 좋은 여권 케이스 등을 함께 추천)
- 함께 구매하는 상품, 이어서 구매하는 상품처럼 열람 로그와는 또 다른 결과를 얻을 수 있다.
23-2. 특정 아이템에 흥미가 있는 사람이 함께 찾아보는 아이템 검색
SUM(CASE~), ROW_NUMBER, 벡터 내적, L2 정규화(Norm Normalize), 코사인 유사도
접근 로그를 사용해 아이템의 상관도 계산하기
테이블 action_log

사용자의 아이템에 관한 흥미 수치화하기
: 열람 수(action=view)와 구매 수(action=purchase)를 조합한 점수 계산하기
- 열람하고 구매한 횟수를 count하고,
- 열람 수는 3, 구매 수는 7의 가중치를 주어 평균 점수 계산하기
WITH ratings AS(
SELECT
user_id,
product,
SUM(CASE WHEN action='view' THEN 1 ELSE 0 END) AS view_count,
SUM(CASE WHEN action='purchase' THEN 1 ELSE 0 END) AS purchase_count,
0.3 * SUM(CASE WHEN action='view' THEN 1 ELSE 0 END)+
0.7 * SUM(CASE WHEN action='purchase' THEN 1 ELSE 0 END) AS score
FROM action_log
GROUP BY user_id, product)
SELECT * FROM ratings
ORDER BY user_id, score DESC;

사용자의 아이템에 관한 점수를 조합하여 아이템 사이의 유사도 계산하기
: 아이템 사이의 유사도를 계산하고 순위 생성하기
- 제품 쌍에 대해서 동일한 사용자가 열람/구매한 횟수를 기반으로 점수 계산
- ratings 테이블을 user_id 기준으로 자기 결합하고, 공통 사용자가 존재하는 아이템 페어 생성
- 각 제품과 다른 제품과의 관련 점수를 높은 조합부터 정렬하여 순위 매기기
- where 조건절으로 같은 아이템으로 만들어지는 페어는 배제
- 벡터(어떤 아이템에 대해 부여된 사용자의 점수를 나열한 숫자의 집합)의 내적을 구하듯이 사용자의 점수를 곱해 유사도를 집계함
-- ratings까지 동일
SELECT
r1.product AS target,
r2.product AS related,
-- 모든 아이템을 열람하거나 구매한 사용자 수
COUNT(r1.user_id) AS users,
SUM(r1.score * r2.score) AS score,
ROW_NUMBER() OVER(
PARTITION BY r1.product
ORDER BY SUM(r1.score * r2.score) DESC)
AS `rank`
FROM ratings AS r1
JOIN ratings AS r2
-- 공통 사용자가 존재하는 상품의 페어 생성
ON r1.user_id = r2.user_id
WHERE r1.product <> r2.product
GROUP BY r1.product, r2.product
ORDER BY target, `rank`;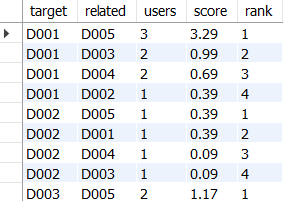
점수 정규화하기
: 단순 벡터 내적을 사용한 유사도는 추천에 있어서 몇 가지 문제점이 있다.
- 접근 수가 많은 아이템의 유사도가 높게 나오는 경향
- 높다는 판단 기준이 없다. (3.7의 유사도가 높은 것인지?)
L2 정규화
: '벡터 정규화'를 통해서 벡터를 모두 같은 길이로 만들어 문제 해결 가능
- 벡터의 길이 = 벡터의 각 수치를 제곱하고 더한 뒤 제급곤을 취한 것
- 유클리드 거리 정의와 동일, norm(벡터의 크기)을 1로 만드는 것을 L2 정규화(= 2 norm 정규화)라 부른다.
사용자의 아이템에 대한 점수 집함을 아이템 벡터로 만들고 L2 정규화 실시
-- ratings까지 동일
,product_base_normalized_ratings AS(
SELECT
user_id,
product,
score,
SQRT(SUM(score*score) OVER(PARTITION BY product)) AS norm,
score / SQRT(SUM(score*score) OVER(PARTITION BY product)) AS norm_score
FROM ratings)
SELECT * FROM product_base_normalized_ratings;
→ 정규화했을 때 벡터의 크기는 반드시 1이 된다. (따라서 벡터의 값이 1개 밖에 없는 D002의 norm_score는 1.0으로 정규화되어 있음)
정규화된 점수로 아이템의 유사도 계산하기
: 앞서 유사도/순위를 계산했던 쿼리 그대로 사용 (정규화된 점수로)
-- product_base_normalized_ratings까지 동일
SELECT
r1.product AS target,
r2.product AS related,
COUNT(r1.user_id) AS users,
SUM(r1.score*r2.score) AS score,
SUM(r1.norm_score*r2.norm_score) AS norm_score,
ROW_NUMBER() OVER
(PARTITION BY r1.product
ORDER BY SUM(r1.norm_score*r2.norm_score) DESC) AS `rank`
FROM product_base_normalized_ratings AS r1
JOIN product_base_normalized_ratings AS r2
ON r1.user_id = r2.user_id
GROUP BY r1.product, r2.product
ORDER BY target, `rank`;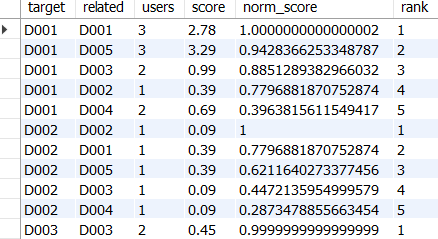
→ 자기자신과의 유사도는 1.0 (벡터를 정규화하면 자기 자신과의 내적 값은 반드시 1이되며, 내적의 최댓값도 1이다)
→ 모든 벡터의 값이 양수라면 내적의 최솟값은 0이다.
→ 따라서 내적의 값이 0이라면 전혀 유사성이 없는 아이템, 1이면 완전히 일치한다는 의미
→ 벡터를 L2 정규화해서 내적한 값은 2개의 벡터를 n차원에 맵핑했을 때 이루는 각도에 코사인을 취한 값과 같아 '코사인 유사도'라고도 부름
24-4. 개인을 위한 추천 상품
SUM(CASE~), ROW_NUMBER, 벡터 내적, L2 정규화, 코사인 유사도
- 앞서 Item to Item 추천에 이어 User to Item 추천을 만드는 방법 소개
- Item to Item은 아이템과 아이템의 유사도를 계산하기만 하면 되지만, User to Item은 일단 사용자와 사용자의 유사도를 계산하고, 유사 사용자가 흥미를 가진 아이템을 구해야 함
- L2 정규화를 사용하되, 사용자의 벡터 내적을 계산할 수 있도록 사용자별 벡터 norm 계산
사용자끼리의 유사도 계산하기
- related_users : user_base_normalized_ratings 점수 내적 계산 → 점수/순위로 사용자들 중 유사한 사용자 찾아내기
-- ratings까지 동일
-- 아래 normalized_ratings는 partition by 부분만 바뀜, 대신 related_users 추가
,
user_base_normalized_ratings AS(
SELECT
user_id,
product,
score,
-- 사용자별로 norm을 계산하기 위해 partition by user_id
SQRT(SUM(score*score) OVER(PARTITION BY user_id)) AS norm,
score / SQRT(SUM(score*score) OVER(PARTITION BY user_id)) AS norm_score
FROM ratings),
related_users AS(
-- 경향이 비슷한 사용자 찾기
SELECT
r1.user_id,
r2.user_id AS related_user,
COUNT(r1.product) AS products,
SUM(r1.norm_score*r2.norm_score) AS score,
ROW_NUMBER() OVER(
PARTITION BY r1.user_id
ORDER BY SUM(r1.norm_score*r2.norm_score) DESC) AS `rank`
FROM user_base_normalized_ratings AS r1
JOIN user_base_normalized_ratings AS r2
ON r1.product = r2.product
WHERE r1.user_id<>r2.user_id
GROUP BY r1.user_id, r2.user_id)
SELECT * FROM related_users
GROUP BY user_id, `rank`;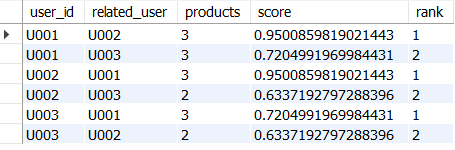
→ 사용자별로 유사한 사용자 점수/순위 계산
유사한 사용자에 대한 제품 점수 계산
- related_user_base_products : related_users에서 각 사용자의 유사한 패턴을 가진 최상위 사용자를 구하고, (rank가 1 이하)
- 해당 사용자와 연관된 제품 점수(사용자별 norm)를 곱하여 합산
-- related_users까지 동일
,
related_user_base_products AS(
SELECT
u.user_id,
r.product,
SUM(u.score*r.score) AS score,
ROW_NUMBER() OVER
(PARTITION BY u.user_id
ORDER BY SUM(u.score*r.score) DESC) AS `rank`
FROM related_users AS u
JOIN ratings AS r
ON u.user_id = r.user_id
WHERE u.`rank`<= 1
GROUP BY u.user_id, r.product)
SELECT * FROM related_user_base_products
ORDER BY user_id;
→ 유사 사용자가 흥미 있어하는 아이템 목록과 순위 도출
→ U001 사용자에게는 D001의 제품이 가장 관련성이 높은 제품이라는 의미 (사용자별 개인화된 추천 가능)
이미 구매한 아이템 필터링하기
: COALESCE(r.purchase_count, 0) = 0 으로 필터링
SELECT
p.user_id,
-- related_user_base_products까지 동일
p.product,
p.score,
ROW_NUMBER() OVER(
PARTITION BY p.user_id
ORDER BY p.score DESC) AS `rank`
FROM related_user_base_products AS p
LEFT JOIN
ratings AS r
ON p.user_id = r.user_id
AND p.product = r.product
WHERE COALESCE(r.purchase_count, 0) = 0
ORDER BY p.user_id;
23-4. 추천 시스템을 개선할 때의 포인트
값과 리스트 조작에서 개선할 포인트
- 가중치: 열람 로그에는 1, 구매 로그에는 3의 가중치를 준다면 더 효율적으로 추천할 수 있음
- 필터: 비정상적인 데이터나 부족한 데이터를 제외하거나, 성별에 따라 추천 점수 가중치를 다르게 줄 때
- 정렬
- 새로운 아이템을 추천하고 싶은 경우, 신규성(Novelty) 점수를 정의
- 매출을 높이고 싶다면 가격/기대 구매 수등을 고려해서 점수를정의
- 이렇게 목적에 따라 지표를 정의하고, 이를 기반으로 정렬해서 추천을 제공하면 다양한 개선을 이끌어낼 수 있다.
- ex. 음식점 리뷰 사이트 추천 - 별점과 거리를 기준으로 <거리> ÷ <별점>으로 구한 점수를 기반으로 사용자에게 추천 매장을 제공해줄 수 있음
구축 방법에 따른 개선 포인트
- 데이터 수집 - 구매 데이터 이외에 리뷰,열람,상품,데모 등 다양한 데이터 사용
- 데이터 가공 - 비정상적인 데이터를 제외하고, 평가 기간을 한정하거나 가중치를 다르게 주어 유행(시간의 변화) 또는 계절에 따라 변하는 사람들의 기호 반영하기
- 데이터 계산 - 넓은 의미에서 추천 시스템은 순위를 구하는 로직. 적절한 로직을 선택하고, 로직을 변경하지 않더라도 데모정보 등에 따라 점수 계산 방법을 다르게 하는 방법도 있음
- 데이터 정렬 - 음식점을 당일 예약하려는 사용자는 현재 위치에서 가까운 음식점을 찾을 확률이 높다. 따라서 추천 결과 음식점을 거리에 따라 정렬해서 보여준다면 사용자의 행동욕구를 높일 수 있음
23-5. 출력할 때 포인트
출력 페이지, 위치, 시점 검토하기
: 페이지에 따라서 어떤 추천을 보여줄지도 중요한 요소
- 추천 모듈이 상품정보보다 위에 출력되는 서비스는 사용자에게 더 많은 선택지를 보여주고 싶어 함
- 반대로 추천 모듈이 아래에 위치하는 경우에는 상품 정보를 우선시해서 사용자의 중간 이탈을 막고자 함
- → 페이지의 목적에 따라 다른 추천 제공
- ex. 장바구니 화면 이동 시 상품 추천 - 상품 구매 중 이탈을 막고, 상품 구매를 완료하면 그 때 새로운 선택지를 주는 것
추천의 이유
- 이 상품을 구매한 사람은 이러한 상품도 구매했습니다, 구매한 OO상품을 기반으로 추천합니다 등 추천 이유를 명확하게 전달하면 효과적 (인지 편향과 편승 효과)
크로스셀을 염두한 추천하기
- 자주 구매하는 상품은 두 제품을 함께 장바구니에 담을 수 있게 하는 버튼을 만들어 크로스셀
서비스와 함께 제공하기
- 구매 금액이 5만원 이상일 때 무료 배송을 제공하는 서비스가 있다면, '다음과 같은 상품을 함께 구매하면 배송 무료'라고 출력하는 것만으로도 다양한 효과를 얻을 수 있음
23-6. 추천과 관련한 지표
추천 시스템의 대표적인 평가 지표 목록
- 웹사이트의 CVR, CTR, 추천을 통한 매출을 집계하는 것도 추천 시스템을 확인할 수 있는 방법이나, 로직과 직접적인 관련이 있는 지표가 아니므로, 추천 시스템에서 어떤 부분을 개선해야 좋을지 명확한 판단을 내리기 어렵다.
- 추천 시스템을 구축할 때의 평가 방법,지표 예시


ex. Coverage
: 추천 기능이 제공되는 사용자/아이템 수를 전체 사용자/아이템 수로 나누기
'SQL > 데이터 분석을 위한 SQL레시피' 카테고리의 다른 글
| [21,22] 검색 기능 평가하기, 데이터마이닝 - NoMatch, 재검색, 재현율, 검색 이탈 비율, 정확률, MAP, 어소시에이션 분석 (0) | 2024.03.31 |
|---|---|
| [19,20] 데이터 중복 검출하기, 여러 개의 데이터셋 비교하기 - 추가/제거/갱신된 데이터 추출, 지표간의 유사도 측정 (1) | 2024.03.23 |
| [17,18] 데이터를 조합해서 새로운 데이터 만들기, 이상값 검출하기 - 크롤러 제외, 데이터 타당성 확인, 특정 IP주소 제외하기 (1) | 2024.03.23 |
| [16] 입력 양식 최적화하기 (3) | 2024.03.06 |
| [15] 사이트 내의 사용자 행동 파악하기(2) - CTR, CVR 집계, 폴아웃(Fall-Out) 리포트 작성, 사용자 흐름 파악 (0) | 2024.03.02 |



