
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 3기가 마지막이라니..!
- ImageDateGenerator
- Growth hacking
- 분석 패널
- lightgbm
- WITH CUBE
- 그로스 마케팅
- 컨브넷
- WITH ROLLUP
- 그로스 해킹
- sql
- 부트 스트래핑
- 그룹 연산
- tableau
- ARIMA
- 캐글 신용카드 사기 검출
- 인프런
- 스태킹 앙상블
- 데이터 증식
- 리프 중심 트리 분할
- python
- XGBoost
- 로그 변환
- DENSE_RANK()
- 캐글 산탄데르 고객 만족 예측
- 데이터 정합성
- pmdarima
- splitlines
- 마케팅 보다는 취준 강연 같다(?)
- 데이터 핸들링
- Today
- Total
LITTLE BY LITTLE
[17,18] 데이터를 조합해서 새로운 데이터 만들기, 이상값 검출하기 - 크롤러 제외, 데이터 타당성 확인, 특정 IP주소 제외하기 본문
[17,18] 데이터를 조합해서 새로운 데이터 만들기, 이상값 검출하기 - 크롤러 제외, 데이터 타당성 확인, 특정 IP주소 제외하기
위나 2024. 3. 23. 16:53
목차
3. 데이터 가공을 위한 SQL 3-1. 하나의 값 조작하기 (5강) 3-2. 여러 개의 값에 대한 조작 (6강) 3-3. 하나의 테이블에 대한 조작 (7강)3-4. 여러 개의 테이블 조작하기 (8강)4. 매출을 파악하기 위한 데이터 추출 4-1. 시계열 기반으로 데이터 집계하기 (9강)4-2. 다면적인 축을 사용해 데이터 집약하기 (10강)
5. 사용자를 파악하기 위한 데이터 추출 5-1. 사용자 전체의 특징과 경향 찾기 (11강) 5-2. 시계열에 따른 사용자 전체의 상태 변화 찾기 (12강)
5-3. 시계열에 따른 사용자의 개별적인 행동 분석하기 (13강)
6. 웹사이트에서 행동을 파악하는 데이터 추출하기 6-1. 사이트 전체의 특징/경향 찾기 6-2. 사이트 내의 사용자 행동 파악하기
6-3. 입력 양식 최적화하기
7. 데이터 활용의 정밀도를 높이는 분석 기술
7-1. 데이터를 조합해서 새로운 데이터 만들기
7-2. 이상값 검출하기
7-3. 데이터 중복 검출하기
7-4. 여러 개의 데이터셋 비교하기
8. 데이터를 무기로 삼기 위한 분석 기술
8-1. 검색 기능 평가하기
8-2. 데이터 마이닝
8-3. 추천
8-4. 점수 계산하기
9. 지식을 행동으로 옮기기
9-1. 데이터 활용의 현장
※ Mysql 기준
7장. 데이터 활용의 정밀도를 높이는 분석 기술
17강. 데이터를 조합해서 새로운 데이터 만들기
17-1. IP주소를 기반으로 국가와 지역 보완하기
innet 자료형, 국가와 지역 판정
csv 파일 형식을 그대로 데이터베이스에 테이블로 만들고 읽어 들이는 쿼리
DROP TABLE IF EXISTS mst_city_ip;
CREATE TABLE mst_city_ip (
network VARCHAR(45) PRIMARY KEY, -- inet 대신 VARCHAR 사용
geoname_id INT,
registered_country_geoname_id INT,
represented_country_geoname_id INT,
is_anonymous_proxy BOOLEAN,
is_satellite_provider BOOLEAN,
postal_code VARCHAR(255),
latitude DECIMAL(10, 8), -- numeric 타입을 DECIMAL로 변경
longitude DECIMAL(11, 8), -- numeric 타입을 DECIMAL로 변경
accuracy_radius INT
);
DROP TABLE IF EXISTS mst_locations;
CREATE TABLE mst_locations (
geoname_id INT PRIMARY KEY,
locale_code VARCHAR(255),
continent_code VARCHAR(10),
continent_name VARCHAR(255),
country_iso_code VARCHAR(10),
country_name VARCHAR(255),
subdivision_1_iso_code VARCHAR(10),
subdivision_1_name VARCHAR(255),
subdivision_2_iso_code VARCHAR(10),
subdivision_2_name VARCHAR(255),
city_name VARCHAR(255),
metro_code INT,
time_zone VARCHAR(255)
);
LOAD DATA LOCAL INFILE 'C:/Users/lh2275/GeoLite2-City-Blocks-IPv4.csv'
INTO TABLE mst_city_ip
FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n'
IGNORE 1 LINES; -- CSV 헤더 무시
LOAD DATA LOCAL INFILE 'C:/Users/lh2275/GeoLite2-City-Locations-en.csv'
INTO TABLE mst_locations
FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n'
IGNORE 1 LINES; -- CSV 헤더 무시
안됨..MySQL 서버에서 local_infile 옵션을 활성화시키고 다시 해보기
17-2. 주말과 공휴일 판단하기

공휴일을 판정하기 위해서 별도의 공휴일 정보 테이블(mst_calendar) 만들기
DROP TABLE IF EXISTS mst_calendar;
CREATE TABLE mst_calendar(
year INTEGER,
month INTEGER,
day INTEGER,
dow VARCHAR(10),
dow_num INTEGER,
holiday_name VARCHAR(255)
);
테이블을 생성한 다음에 직접 공휴일을 추가 (아래는 예시)
INSERT INTO mst_calendar (year, month, day, dow, dow_num, holiday_name)
VALUES (2022, 1, 1, 'Saturday', 6, 'New Year\'s Day');
SELECT
a.action,
a.stamp,
c.dow,
c.holiday_name,
c.dow_num IN (0,6) -- 토요일, 일요일 판정
OR c.holiday_name IS NOT NULL -- 공휴일 판정
AS is_day_off
FROM access_log AS a
JOIN
mst_calendar AS c;17-3. 하루 집계 범위 변경하기
- 날짜별로 데이터를 집계할 경우, 그냥 집계하면 자정(0시) 기준으로 데이터가 처리된다.
- 사용자의 활동이 가장 적은 오전 4시를 기준으로, 오전 4시부터 다음 날 3시 59분 59초까지를 하루로 집계할 수 있게 데이터를 가공하는 방법 알아보기
하루 집계 범위 변경하기
- 하루 집계 범위를 오전 4시에서 시작하게 변경하기 위해서 타임 스탬프의 시간 4시간 당기기
- 원래 날짜(raw_date)와 당긴 날짜(mod_date) 구하기
- stamp 컬럼에서 4시간을 빼서 mod_stamp라는 새 컬럼을 생성
- 이를 위해 DATE_ADD 함수와 INTERVAL 키워드를 사용
- DATE_FORMAT 함수를 사용하여 stamp와 mod_stamp 컬럼의 날짜 부분만 추출하여 각각 raw_date와 mod_date로 포맷팅
WITH action_log_with_mod_stamp AS (
SELECT *,
DATE_ADD(stamp, INTERVAL -4 HOUR) AS mod_stamp
FROM action_log
)
SELECT
session,
user_id,
action,
stamp,
DATE_FORMAT(stamp, '%Y-%m-%d') AS raw_date,
DATE_FORMAT(mod_stamp, '%Y-%m-%d') AS mod_date
FROM action_log_with_mod_stamp;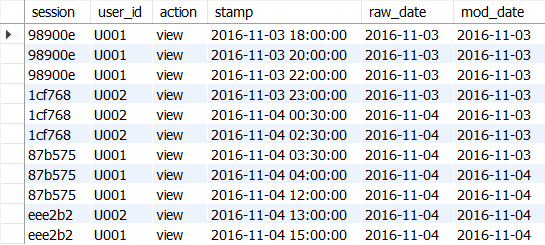
18강. 이상값 검출하기
노이즈를 포함한 액션 로그 샘플 데이터

18-1. 데이터 분산 계산하기
PERCENT_RANK 함수, 상위 n%, 하위 n%
로그 데이터에서 이상값을 검출하는 가장 기본적인 방법은 분산을 계산하고, 많이 벗어난 값을 찾는 것
- 웹사이트 접근 로그에서 어떤 세션의 페이지 조회 수가 극단적으로 많다면, 타 업체 혹은 크롤러일 가능성
- 반대로 극단적으로 접근이 적다면 존재하지 않는 URL에 잘못 접근했을 가능성
세션별로 페이지 열람 수 랭킹 비율 구하기
- 세션별로 조회수를 계산한 뒤 조회수가 많은 상위 n% 데이터 확인하기
- 세션별로 페이지 조회수 집계
- PERCENT_RANK 함수를 사용해 페이지 조회수 랭킹을 비율로 구하기
**PERCENT_RANK 의 값은 (rank-1)/(<전체 수>-1)로 계산된 비율
WITH session_count AS (
SELECT
session,
COUNT(*) AS count
FROM action_log_with_noise
GROUP BY session
)
SELECT
session,
count,
RANK() OVER (ORDER BY count DESC) AS `rank`,
ROUND(PERCENT_RANK() OVER (ORDER BY count DESC),2) AS `percent_rank`
FROM session_count;
세션별로 페이지 열람 수가 많은 상위 15%의 세션 필터링하기(percent_rank가 0.15 이하)
WITH session_count AS (
SELECT
session,
COUNT(*) AS count
FROM action_log_with_noise
GROUP BY session
), ranked_sessions AS (
SELECT
session,
count,
RANK() OVER (ORDER BY count DESC) AS `rank`,
ROUND(PERCENT_RANK() OVER (ORDER BY count DESC),2) AS `percent_rank`
FROM session_count
)
SELECT *
FROM ranked_sessions
WHERE `percent_rank` <= 0.15;
18-2. 크롤러 제외하기
LIKE 연산자
크롤러 접근을 제외하는 방법
- 규칙을 기반으로 제외하기
- 마스터 데이터를 사용해 제외하기
1. 규칙을 기반으로 제외하기
- 특정 문자열 포함 - bot, crawler, spider etc...
- 이름 포함 - Googlebot, Baiduspider, Yeti, Yahoo, Tumblr etc...
규칙을 기반으로 크롤러를 제외하는 쿼리
SELECT * FROM action_log_with_noise
WHERE NOT
( user_agent LIKE '%bot%'
OR user_agent LIKE '%crawler%'
OR user_agent LIKE '%spider%'
OR user_agent LIKE 'archiver%'
);
마스터 데이터를 기반으로 크롤러를 제외하는 쿼리
- user_agent - 웹 봇/크롤러 문자열 에서 일반적으로 발견되는 다양한 패턴을 포함하는 가상 테이블을 생성
- filtered_action_log - 가상 테이블의 패턴과 일치 하면 제외 시키기
WITH mst_bot_user_agent AS(
SELECT '%bot%' AS rule
UNION ALL SELECT '%crawler%' AS rule
UNION ALL SELECT '%spider%' AS rule
UNION ALL SELECT '%archiver%' AS rule),
filtered_action_log AS(
SELECT
l.stamp,
l.session,
l.action,
l.products,
l.url,
l.ip,
l.user_agent
FROM action_log_with_noise AS l
WHERE NOT EXISTS(
SELECT * FROM mst_bot_user_agent AS m
WHERE l.user_agent LIKE m.rule))
SELECT * FROM filtered_action_log;
크롤러 감시하기
: 마스터 데이터를 사용해서 제외한 로그에서, 접근이 많은 에이전트를 순위대로 추출한 뒤, 마스터 데이터에서 누락된 에이전트가 없는지 확인
접근이 많은 사용자 에이전트를 확인하는 쿼리
-- filtered_action_log까지 동일
SELECT
user_agent,
COUNT(*) AS count,
ROUND(100.0 * SUM(COUNT(*)) OVER(
ORDER BY COUNT(*) DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
/ SUM(COUNT(*)) OVER(),2) AS cumulative_ratio
FROM filtered_action_log
GROUP BY user_agent
ORDER BY count DESC;
→ 마스터 데이터에 없는 user_agent 중에서 크롤러로 의심되는 에이전트가 있는지 확인하는 쿼리를 주기적으로 실행
18-3. 데이터 타당성 확인하기
결손값을 포함한 액션로그 테이블

- 현재 액션 로그 테이블은 액션의 종류에 따라 필수 컬럼이 다름
- view 액션에서는 category, products가 필요하지 않음
- amount에는 purchase 액션만 필요
로그데이터가 이와 같은 요건을 만족하는 쿼리 작성하기
- 액션들을 GROUP BY로 집약해서, action/사용자 ID등의 각 컬럼이 만족해야 하는 요건을 CASE식으로 판정
- 요건 만족시 CASE식의 값은 1이, 않을 시 0이 됨
- 이러한 CASE식의 값을 AVG 함수로 집약해서 로그 데이터 전체의 조건 만족 비율 계산
SELECT
action,
-- session은 반드시 null이 아니어야 함
AVG(CASE WHEN session IS NOT NULL THEN 1.0 ELSE 0.0 END) AS session,
-- user_id도 반드시 null이 아니어야 함
AVG(CASE WHEN user_id IS NOT NULL THEN 1.0 ELSE 0.0 END) AS user_id,
-- category는 action=view인 경우 null이어야 하고, 이외의 경우 null이 아니어야 함
AVG(CASE action
WHEN 'view' THEN
CASE WHEN category IS NULL THEN 1.0 ELSE 0.0 END
ELSE
CASE WHEN category IS NOT NULL THEN 1.0 ELSE 0.0 END
END) AS category,
-- product도 category와 마찬가지로 action=view인 경우에만 null
AVG(CASE action
WHEN 'view' THEN
CASE WHEN products IS NULL THEN 1.0 ELSE 0.0 END
ELSE
CASE WHEN products IS NOT NULL THEN 1.0 ELSE 0.0 END
END) AS products,
-- amount는 action=purchase인 경우 null이 아니어야 함
AVG(CASE action
WHEN 'purchase' THEN
CASE WHEN amount IS NOT NULL THEN 1.0 ELSE 0.0 END
ELSE
CASE WHEN amount IS NULL THEN 1.0 ELSE 0.0 END
END) AS amount,
-- stamp는 반드시 null이 아니어야 함
AVG(CASE WHEN stamp IS NOT NULL THEN 1.0 ELSE 0.0 END) AS stamp
FROM invalid_action_log
GROUP BY action;
→ 데이터가 요건을 만족하는 경우 컬럼 값이 1이 되고, 만족하지 않는 경우 1보다 작음
→ 예를 들어 stamp가 null이 아닌 경우만 유효로 간주되므로, 만약 `stamp`가 1보다 작다면, 일부 `action` 레코드가 stamp 없이 기록되고 있음을 나타내고, 이는 stamp가 누락된 레코드가 있다는 의미이기에 해결해야할 필요가 있음
18-4. 특정 IP주소에서의 접근 제외하기
웹 서비스의 접근 로그가 사내에서의 접근을 포함하는 경우, 정규 서비스 사용자 이외의 접근은 분석할 때 제외해야 함
IP 주소를 기반으로 테스트 사용자 접근과 사내 접근을 판별하기
IP 주소를 포함한 액션 로그 테이블

[postgresql 내용 생략]
특정 IP주소 제외하기 - IP주소를 다루는 자료형 innet이 없는 경우
필요한 두 가지 과정은
- 네트워크 범위를 처음 IP주소와 끝 IP주소로 표현
- IP 주소를 대소 비교 가능한 형식으로 변환
- IP 주소를 정수 자료형으로 표현하거나,
- IP 주소를 0으로 메워 문자열로 표현
1. 네트워크 범위를 나타내는 처음과 끝 IP주소를 부여하는 쿼리
WITH mst_reserved_ip_with_range AS(
-- 마스터 테이블에 네트워크 범위에 해당하는 IP주소의 최소/최댓값 추가하기
SELECT '127.0.0.0/8' AS network,
'127.0.0.0' AS network_start_ip,
'127.255.255.255' AS network_last_ip,
'locoalhost' AS description
UNION ALL
SELECT '10.0.0.0/8' AS network,
'10.0.0.0' AS network_start_ip,
'10.255.255.255' AS network_last_ip,
'Private network' AS description
UNION ALL
SELECT '172.16.0.0/12' AS network,
'172.16.0.0' AS network_start_ip,
'172.31.255.255' AS network__last_ip,
'Private network' AS description
UNION ALL
SELECT '192.0.0.0/24' AS network,
'192.0.0.0' AS network_start_ip,
'192.0.0.255' AS network_last_ip,
'Private network' AS description
UNION ALL
SELECT '192.168.0.0/16' AS network,
'192.168.0.0' AS network_start_ip,
'192.168.255.255' AS network_last_ip,
'Private network' AS description)
SELECT * FROM mst_reserved_ip_with_range;
2. IP주소를 대소 비교 가능한 형식으로 변환 - 마스터 테이블의 IP 주소를 0으로 메워 문자열로 표현
+ 마스터 테이블에 포함된 네트워크에 해당하는 IP 주소를 가진 로그를 제외하기
[action_log_with_ip_varchar]
문자열로 변환하고 0으로 채우기
-- mst_reserved_ip_with_range 동일
,
action_log_with_ip_varchar AS (
SELECT *,
CONCAT(
LPAD(SUBSTRING_INDEX(ip, '.', 1), 3, '0'),
LPAD(SUBSTRING_INDEX(SUBSTRING_INDEX(ip, '.', 2), '.', -1), 3, '0'),
LPAD(SUBSTRING_INDEX(SUBSTRING_INDEX(ip, '.', -2), '.', 1), 3, '0'),
LPAD(SUBSTRING_INDEX(ip, '.', -1), 3, '0')
) AS ip_varchar
FROM action_log_with_ip
)
SELECT * FROM action_log_with_ip_varchar;
[mst_reserved_ip_with_varchar_range]
마스터 테이블의 IP주소를 문자열로 변환하고 0으로 채우기
,
mst_reserved_ip_with_varchar_range AS(
-- 마스터 테이블의 IP 주소를 0으로 메운 문자열로 표현하기
SELECT *,
CONCAT(
LPAD(SUBSTRING_INDEX(network_start_ip, '.', 1), 3, '0'),
LPAD(SUBSTRING_INDEX(SUBSTRING_INDEX(network_start_ip, '.', 2), '.', -1), 3, '0'),
LPAD(SUBSTRING_INDEX(SUBSTRING_INDEX(network_start_ip, '.', -2), '.', 1), 3, '0'),
LPAD(SUBSTRING_INDEX(network_start_ip, '.', -1), 3, '0')
) AS network_start_ip_varchar,
CONCAT(
LPAD(SUBSTRING_INDEX(network_last_ip, '.', 1), 3, '0'),
LPAD(SUBSTRING_INDEX(SUBSTRING_INDEX(network_last_ip, '.', 2), '.', -1), 3, '0'),
LPAD(SUBSTRING_INDEX(SUBSTRING_INDEX(network_last_ip, '.', -2), '.', 1), 3, '0'),
LPAD(SUBSTRING_INDEX(network_last_ip, '.', -1), 3, '0')
) AS network_last_ip_varchar
FROM mst_reserved_ip_with_range)
select * from mst_reserved_ip_with_varchar_range;
SELECT문
varchar로 변환한 IP주소가 마스터 테이블의 first_ip와 last_ip 범위 안에 있는지 판정하기
SELECT
l.user_id,
l.ip,
l.ip_varchar,
l.stamp
FROM action_log_with_ip_varchar AS l
CROSS JOIN
mst_reserved_ip_with_varchar_range AS m
GROUP BY
l.user_id, l.ip, l.ip_varchar, l.stamp
HAVING SUM(CASE WHEN l.ip_varchar
BETWEEN m.network_start_ip_varchar AND m.networK_last_ip_varchar
THEN 1 ELSE 0 END) = 0;



