
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 그로스 해킹
- WITH ROLLUP
- tableau
- 그로스 마케팅
- 그룹 연산
- 캐글 신용카드 사기 검출
- splitlines
- 데이터 정합성
- 컨브넷
- 로그 변환
- Growth hacking
- 데이터 핸들링
- 데이터 증식
- 3기가 마지막이라니..!
- python
- ImageDateGenerator
- 부트 스트래핑
- WITH CUBE
- XGBoost
- 분석 패널
- sql
- 캐글 산탄데르 고객 만족 예측
- DENSE_RANK()
- pmdarima
- 마케팅 보다는 취준 강연 같다(?)
- lightgbm
- 스태킹 앙상블
- 인프런
- 리프 중심 트리 분할
- ARIMA
- Today
- Total
LITTLE BY LITTLE
[19,20] 데이터 중복 검출하기, 여러 개의 데이터셋 비교하기 - 추가/제거/갱신된 데이터 추출, 지표간의 유사도 측정 본문
[19,20] 데이터 중복 검출하기, 여러 개의 데이터셋 비교하기 - 추가/제거/갱신된 데이터 추출, 지표간의 유사도 측정
위나 2024. 3. 23. 23:10
목차
3. 데이터 가공을 위한 SQL 3-1. 하나의 값 조작하기 (5강) 3-2. 여러 개의 값에 대한 조작 (6강) 3-3. 하나의 테이블에 대한 조작 (7강)3-4. 여러 개의 테이블 조작하기 (8강)4. 매출을 파악하기 위한 데이터 추출 4-1. 시계열 기반으로 데이터 집계하기 (9강)4-2. 다면적인 축을 사용해 데이터 집약하기 (10강)
5. 사용자를 파악하기 위한 데이터 추출 5-1. 사용자 전체의 특징과 경향 찾기 (11강) 5-2. 시계열에 따른 사용자 전체의 상태 변화 찾기 (12강)
5-3. 시계열에 따른 사용자의 개별적인 행동 분석하기 (13강)
6. 웹사이트에서 행동을 파악하는 데이터 추출하기 6-1. 사이트 전체의 특징/경향 찾기 6-2. 사이트 내의 사용자 행동 파악하기
6-3. 입력 양식 최적화하기
7. 데이터 활용의 정밀도를 높이는 분석 기술
7-1. 데이터를 조합해서 새로운 데이터 만들기
7-2. 이상값 검출하기
7-3. 데이터 중복 검출하기
7-4. 여러 개의 데이터셋 비교하기
8. 데이터를 무기로 삼기 위한 분석 기술
8-1. 검색 기능 평가하기
8-2. 데이터 마이닝
8-3. 추천
8-4. 점수 계산하기
9. 지식을 행동으로 옮기기
9-1. 데이터 활용의 현장
※ Mysql 기준
7장. 데이터 활용의 정밀도를 높이는 분석 기술
19강. 데이터 중복 검출하기
19-1. 마스터 데이터의 중복
데이터가 중복되는 이유
- 여러 번 로드 됐을 때
- 마스터 데이터 값 갱신 시 문제가 발생 해 오래된 레코드와 새로운 레코드가 서로 다른 레코드로 분리된 경우
- 운용상의 실수로 같은 ID를 다른 데이터에 재사용한 경우
중복 데이터가 존재하는 테이블 사용

테이블 내부에 키 중복이 발생하는지 테이블 전체의 '레코드 수'와 '유니크한 키의 수'를 세서 비교하기
SELECT
COUNT(*) AS total_num,
COUNT(DISTINCT id) AS key_num
FROM mst_categories;
→ 테이블 전체의 레코드 수와 유니크한 키의 수가 일치하지 않아 중복이 존재함을 알 수 있음
키가 중복되는 레코드 확인하기
: 중복되는 id를 확인하기 위해서, id를 기반으로 GROUP BY 집약하고, HAVING 구문을 사용해 레코드 수가 1보다 큰 그룹을 찾아내면 된다.
*MYSQL에서는 GROUP_CONCAT 함수 사용
GROUP_CONCAT(): 그룹 내 열 값을 결합하여 하나의 문자열로 반환
SELECT id,
COUNT(*) AS record_num,
GROUP_CONCAT(name ORDER BY name SEPARATOR ',') AS name_list,
GROUP_CONCAT(stamp ORDER BY stamp SEPARATOR ',') AS stamp_list
FROM mst_categories
GROUP BY id
HAVING COUNT(*) > 1;
원래 레코드 형식을 그대로 출력하고 싶은 경우,
값을 배열로 만드는 집약 함수 대신, 윈도 함수를 사용해서 중복된 레코드 압축하기
WITH mst_categories_with_key_num AS(
SELECT *,
COUNT(*) OVER(PARTITION BY id) AS key_num
FROM mst_categories)
SELECT * FROM mst_categories_with_key_num
WHERE key_num > 1;
→ 여러번의 데이터 로드가 원인이라면, 데이터 로드 흐름을 수정하거나, 매번 데이터를 지우고 새로 저장하는 방법 사용하기
→ 마스터 데이터가 갱신되어 새로운 데이터와 오래된 데이터가 중복이 되는 경우에는 새로운 데이터만 남기거나, 타임스탬프를 포함해서 유니크 키를 구성하는 방법도 생각해볼 수 있음
19-2. 로그 중복 검출하기
GROUP BY, MIN, ROW_NUMBER, LAG
연속으로 2회 클릭되거나, 새로고침으로 인해 로그가 2회 동시에 발생하는 경우와 같은 로그 데이터의 중복 검출하기
중복이 있는 액션로그 테이블
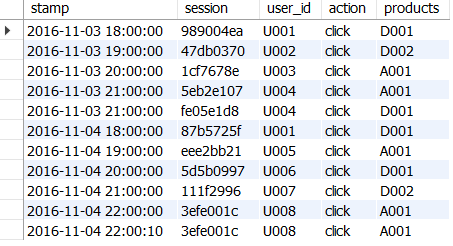
중복 데이터 확인하기
사용자와 상품의 조합을 만들고 이에 대한 중복 확인하기
SELECT
user_id,
products,
GROUP_CONCAT(session ORDER BY session SEPARATOR ',') AS session_list,
GROUP_CONCAT(stamp ORDER BY stamp SEPARATOR ',') AS stamp_list
FROM dup_action_log
GROUP BY user_id, products
HAVING COUNT(*)>1;
'<사용자 ID> = U001'과 '<상품ID> = D001'의 로그는 세션 ID가 다른 상태로 타임스탬프가 하루 차이가 남
→ 사용자와 상품 조합이 같더라도, 별개의 액션으로 취급하기
'<사용자 ID> = U008'과 '<상품ID> = A001'의 경우 동일 세션이고, 타임스탬프도 10초밖에 차이나지 않음
→ 중복으로 보고 배제하기
중복 데이터 배제하기
타임 스탬프만을 활용할 경우
- 같은 세션ID, 같은 상품일 때, 타임 스탬프가 가장 오래된 데이터만을 남기기
- GROUP BY로 집약하고, ,MIN(stamp)로 가장 오래된 타임스탬프만 추출하기
SELECT
session,
user_id,
action,
products,
MIN(stamp) AS stamp
FROM dup_action_log
GROUP BY session, user_id, action, products;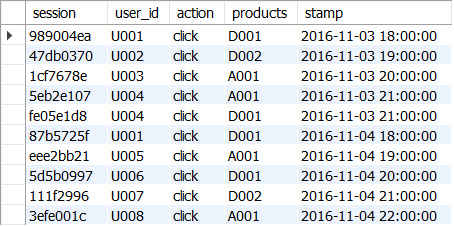
→ <사용자 ID> = U008과 <상품 ID> = A001의 경우, 타임스탬프가 오래된 로그만 남기고 있음
중복된 데이터 배제하기
ROW_NUMBER 사용하기
WITH
dup_action_log_with_order_num AS(
SELECT *,
ROW_NUMBER() OVER(
PARTITION BY session, user_id, action, products
ORDER BY stamp) AS order_num
FROM dup_action_log)
SELECT
session,
user_id,
action,
products,
stamp
FROM dup_action_log_with_order_num
WHERE order_num = 1; -- 순번이 1인 데이터(중복된 것 중 가장 앞의 것)만 남기기
여기에서는 user_id와 products 조합이 같더라도, session이 다르면 다른 로그로 취급함
→ session ID를 사용할 수 없는 경우라면, time stamp 간격을 확인하고 일정 시간 이내의 로그를 중복으로 취급하기
이전 액션으로부터의 경과 시간 계산하기
MYSQL에서는 TIMESTAMPDIFF 함수 사용
WITH dup_action_log_with_lag_seconds AS (
SELECT
user_id,
action,
products,
stamp,
TIMESTAMPDIFF(SECOND, LAG(stamp) OVER (
PARTITION BY user_id, action, products
ORDER BY stamp
), stamp) AS lag_seconds
FROM dup_action_log
)
SELECT * FROM dup_action_log_with_lag_seconds;
→ 중복되지 않은 레코드의 경우 lag_seconds가 null이 된다.
→ 사용자 ID와 상품 ID가 중복되는 레코드의 경우, time stamp를 기반으로 이전 액션에서의 경과 시간을 계산
경과 시간(lag_seconds)이 일정시간(30분) 보다 적을 경우, 중복으로 취급해 배제하기
-- dup_action_log_with_lag_seconds까지 동일
SELECT
user_id,
action,
products,
stamp
FROM dup_action_log_with_lag_seconds
WHERE (lag_seconds IS NULL OR lag_seconds >= 30*60)
ORDER BY stamp;
→ 'U001-D001'과 'U008-A001' 중복 제거됨
20강. 여러 개의 데이터셋 비교하기
데이터의 차이를 추출하는 경우
- 같은 성질의 데이터, 또는 같은 SQL로 만들어진 다른 기간의 집계 결과를 비교해서 추가/변경이 없는지, 삭제/결손이 없는지 확인하는 상황
- EX. 지역 합병 정책 등으로 우편 번호가 대량으로 변경될 때 기존 지역이 어떤 형태로 추가, 삭제, 변경되는지 알 수 있다면 사용자와 점포 등의 주소 데이터를 적절하게 변경할 수 있을 것
데이터의 순위를 비교하는 경우
- 웹사이트 내 인기 기사 순위 또는 적절한 검색 조건을 출력하는 모듈에서는 순위 집계 기간과 조건을 적절하게 변경해야 서비스를 더 활성화할 수 있다.
- 그리고 변경한 후에는 과거 로직과 비교해서 어떤 차이가 있었는지 등을 확인해야 함
- 로직 결과로 출력된 순위의 유사도를 수치화해서, 새로운 로직과 과거 로직의 변화를 정량적으로 설명할 수 있어야 함
20-1. 데이터의 차이 추출하기
OUTER JOIN, IS DISTINCT FROM 연산자
16.12.1의 상품 마스터 테이블과 17.1.1의 상품 마스터 테이블 사용


추가된 마스터 데이터 추출하기
: 두 개의 마스터 테이블에서 한쪽에만 존재하는 레코드를 추출하기 위해 OUTER JOIN 사용
- 새로운 테이블을 기준으로 오래된 테이블을 LEFT OUTER JOIN
- 오래된 테이블의 컬럼이 NULL인 레코드 추출하기
SELECT
new_mst.*
FROM mst_products_20170101 AS new_mst
LEFT OUTER JOIN
mst_products_20161201 AS old_mst
ON new_mst.product_id = old_mst.product_id
WHERE old_mst.product_id IS NULL;
→ 12월 4일에 추가된 D002 레코드가 추출됨
제거된 마스터 데이터 추출하기
: 반대로 OLD를 기준으로 JOIN하여 NEW가 NULL인 데이터 추출
SELECT
old_mst.*
FROM mst_products_20170101 AS new_mst
RIGHT OUTER JOIN
mst_products_20161201 AS old_mst
ON new_mst.product_id = old_mst.product_id
WHERE new_mst.product_id IS NULL;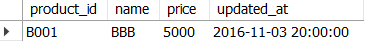
→ new_mst에는 없는 B001 레코드가 추출됨
갱신된 마스터 데이터 추출하기
: OLD와 NEW에 모두 존재하되, time stamp 값이 다른 레코드 추출
SELECT
new_mst.product_id,
old_mst.name AS old_name,
old_mst.price AS old_price,
new_mst.name AS new_name,
new_mst.price AS new_price,
new_mst.updated_at
FROM mst_products_20170101 AS new_mst
JOIN mst_products_20161201 AS old_mst
ON new_mst.product_id = old_mst.product_id
WHERE new_mst.updated_at <> old_mst.updated_at;
→ 가격이 4,000원에서 5,000원으로 갱신된 C001레코드가 추출됨
변경된 마스터 데이터 모두 추출하기
FULL OUTER JOIN
- 차이가 발생한 레코드 - 단순히 new.stamp <> old.stamp 조건만으로 충분치 않음, outer join의 경우 한쪽에만 레코드가 있을 때, 다른쪽이 null이 되므로, 한쪽에만 null이 있는지 확인해야 함
- 한쪽에만 null이 있는 레코드를 확인할 때에는 IS DISTINCT FROM 연산자 사용
- 연산자 없는 미들웨어의 경우 COALESCE함수로 NULL을 배제하고 <> 연산자로 비교하기
- OLD가 NULL이면 추가
- NEW가 NULL이면 삭제
- 이외의 경우(time stamp가 다른 경우) 갱신으로 판정
* MySQL은 FULL OUTER JOIN을 직접 지원하지 않음
→ 대신 RIGHT JOIN을 조합하여 FULL OUTER JOIN과 동일한 결과를 얻을 수 있음
- 두 번 LEFT JOIN해서 old_mst와 new_mst 상품 기준 정보를 각각 가져오고, UNION ALL로 쿼리 결과 합치기
* MySQL에서는 infinity 값을 사용할 수 없다.
→ 대신 '9999-12-31' 사용하기
SELECT
COALESCE(new_mst.product_id, old_mst.product_id) AS product_id,
COALESCE(new_mst.name, old_mst.name) AS name,
COALESCE(new_mst.updated_at, old_mst.updated_at) AS updated_at,
CASE
WHEN old_mst.product_id IS NULL THEN 'added'
WHEN new_mst.updated_at <> old_mst.updated_at THEN 'updated'
END AS status
FROM mst_products_20170101 AS new_mst
LEFT JOIN mst_products_20161201 AS old_mst
ON new_mst.product_id = old_mst.product_id
WHERE (new_mst.updated_at IS NOT NULL AND old_mst.product_id IS NULL)
OR (new_mst.updated_at IS NOT NULL AND old_mst.updated_at IS NOT NULL AND new_mst.updated_at <> old_mst.updated_at)
UNION ALL
SELECT
COALESCE(new_mst.product_id, old_mst.product_id),
COALESCE(new_mst.name, old_mst.name),
COALESCE(new_mst.updated_at, old_mst.updated_at),
CASE
WHEN new_mst.product_id IS NULL THEN 'deleted'
END AS status
FROM mst_products_20161201 AS old_mst
LEFT JOIN mst_products_20170101 AS new_mst
ON old_mst.product_id = new_mst.product_id
WHERE new_mst.product_id IS NULL
AND COALESCE(new_mst.updated_at, '9999-12-31')
<> COALESCE(old_mst.updated_at, '9999-12-31');
20-2. 두 순위의 유사도 계산하기
RANK, SUM, COUNT, Spearman's Rank Correlation Coefficient
14강에서 소개된 3개의 지표 '방문 횟수', '방문자 수', '페이지 뷰'로 페이지 순위를 작성하는 경우가 많다.
→ 순위들의 유사도를 계산해서 어떤 순위가 효율적인지 순위를 정량적으로 평가하기

지표들의 순위 작성하기
방문횟수, 방문자 수, 페이지 뷰 기반 순위 작성하기
WITH
path_stat AS(
SELECT
path,
COUNT(DISTINCT long_session) AS access_user,
COUNT(DISTINCT short_session) AS access_count,
COUNT(*) AS page_view
FROM access_log
GROUP BY path),
-- 방문횟수, 방문자 수, 페이지 뷰별로 순위 붙이기
path_ranking AS(
SELECT 'access_user' AS type, path, RANK() OVER(
ORDER BY access_user DESC) AS `rank`
FROM path_stat
UNION ALL
SELECT 'access_count' AS type, path, RANK() OVER(
ORDER BY access_count DESC) AS `rank`
FROM path_stat
UNION ALL
SELECT 'page_view' AS type, path, RANK() OVER(
ORDER BY page_view DESC) AS `rank`
FROM path_stat)
SELECT * FROM path_ranking
ORDER BY type,`rank`;

→ 각 지표별로 '/top', '/detail', '/search' 라는 3개 페이지 순위를 출력
경로별 순위들의 차이 계산하기
-- path_ranking까지 동일
,
pair_ranking AS(
SELECT
r1.path,
r1.type AS type1,
r1.rank AS rank1,
r2.type AS type2,
r2.rank AS rank2,
POWER(CAST(r1.rank AS SIGNED) - CAST(r2.rank AS SIGNED), 2) AS diff
FROM path_ranking AS r1
JOIN path_ranking AS r2
ON r1.path = r2.path)
SELECT * FROM pair_ranking
ORDER BY type1, type2, rank1;
※ UNSIGNED TYPE
: 모든 integer 타입은 속성으로 unsigned를 갖고 있는데, 이 타입은 1)음수를 포함하지 않거나, 혹은 2)값의 범위를 양수쪽으로 더 넓게 갖고 싶을 때 사용한다. 따라서 음수 값이 발생 되는 경우 CAST AS SIGNED 해주어야 함

스피어만 상관계수 계산하기
: 두 개의 순위가 완전히 일치할 경우 '1.0'을, 일치하지 않을 경우 '-1.0'이 되는 성질을 가짐
스피어만 상관계수로 순위의 유사도를 계산하는 쿼리
-- pair_ranking까지 동일
SELECT
type1,
type2,
1- (6.0 * SUM(diff) / (POWER(COUNT(*), 3) - COUNT(*))) AS spearman
FROM pair_ranking
GROUP BY type1, type2
ORDER BY type1, spearman DESC;
→ 지표 사이의 유사성을 구해서, 이를 기반으로 이상적인 순위를 자동 생성할 수 있음
→ 예를 들어 성적을 기반으로 과목의 유사성을 측정할 때, '수학 성적이 높은 학생은 영어 성적이 높을까?'와 같은 것을 확인할 수 있는 것처럼, '방문자 수가 높은 path는 페이지뷰도 높을까?' 등을 확인할 수 있다.
'SQL > 데이터 분석을 위한 SQL레시피' 카테고리의 다른 글
| [23] 추천 시스템 - 협업 필터링(Item to Item, User to Item 예제, 벡터 내적을 사용한 유사도, L2 정규화) (0) | 2024.04.07 |
|---|---|
| [21,22] 검색 기능 평가하기, 데이터마이닝 - NoMatch, 재검색, 재현율, 검색 이탈 비율, 정확률, MAP, 어소시에이션 분석 (0) | 2024.03.31 |
| [17,18] 데이터를 조합해서 새로운 데이터 만들기, 이상값 검출하기 - 크롤러 제외, 데이터 타당성 확인, 특정 IP주소 제외하기 (1) | 2024.03.23 |
| [16] 입력 양식 최적화하기 (3) | 2024.03.06 |
| [15] 사이트 내의 사용자 행동 파악하기(2) - CTR, CVR 집계, 폴아웃(Fall-Out) 리포트 작성, 사용자 흐름 파악 (0) | 2024.03.02 |



