
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 리프 중심 트리 분할
- 로그 변환
- sql
- 캐글 산탄데르 고객 만족 예측
- 데이터 핸들링
- 마케팅 보다는 취준 강연 같다(?)
- 스태킹 앙상블
- 그로스 마케팅
- ARIMA
- 인프런
- python
- 그룹 연산
- DENSE_RANK()
- XGBoost
- lightgbm
- 분석 패널
- 캐글 신용카드 사기 검출
- 데이터 증식
- tableau
- Growth hacking
- 부트 스트래핑
- ImageDateGenerator
- WITH ROLLUP
- 데이터 정합성
- splitlines
- pmdarima
- 그로스 해킹
- 3기가 마지막이라니..!
- WITH CUBE
- 컨브넷
- Today
- Total
LITTLE BY LITTLE
[15] 사이트 내의 사용자 행동 파악하기(2) - CTR, CVR 집계, 폴아웃(Fall-Out) 리포트 작성, 사용자 흐름 파악 본문
[15] 사이트 내의 사용자 행동 파악하기(2) - CTR, CVR 집계, 폴아웃(Fall-Out) 리포트 작성, 사용자 흐름 파악
위나 2024. 3. 2. 16:20
목차
3. 데이터 가공을 위한 SQL 3-1. 하나의 값 조작하기 (5강) 3-2. 여러 개의 값에 대한 조작 (6강) 3-3. 하나의 테이블에 대한 조작 (7강)3-4. 여러 개의 테이블 조작하기 (8강)4. 매출을 파악하기 위한 데이터 추출 4-1. 시계열 기반으로 데이터 집계하기 (9강)4-2. 다면적인 축을 사용해 데이터 집약하기 (10강)
5. 사용자를 파악하기 위한 데이터 추출 5-1. 사용자 전체의 특징과 경향 찾기 (11강) 5-2. 시계열에 따른 사용자 전체의 상태 변화 찾기 (12강)
5-3. 시계열에 따른 사용자의 개별적인 행동 분석하기 (13강)
6. 웹사이트에서 행동을 파악하는 데이터 추출하기 6-1. 사이트 전체의 특징/경향 찾기
6-2. 사이트 내의 사용자 행동 파악하기
6-3. 입력 양식 최적화하기
7. 데이터 활용의 정밀도를 높이는 분석 기술
7-1. 데이터를 조합해서 새로운 데이터 만들기
7-2. 이상값 검출하기
7-3. 데이터 중복 검출하기
7-4. 여러 개의 데이터셋 비교하기
8. 데이터를 무기로 삼기 위한 분석 기술
8-1. 검색 기능 평가하기
8-2. 데이터 마이닝
8-3. 추천
8-4. 점수 계산하기
9. 지식을 행동으로 옮기기
9-1. 데이터 활용의 현장
※ Mysql 기준
6장. 웹사이트에서의 행동을 파악하는 데이터 추출하기
15강. 사이트 내의 사용자 행동 파악하기
보충자료: 프로세스마이닝
- 프로세스 마이닝이란, event data로부터 프로세스를 도출하여 이를 시각화하고 인사이트를 얻는 과정
- “프로세스“의 문제점&개선점 도출
- 프로세스 내에서 시간을 오래 차지하는 병목(bottle neck)활동이 무엇인지
- 반복 작업은 없는지
- 원래 원하던 프로세스에서 벗어난 프로세스는 없는지
https://playinpap.github.io/process-mining/
사용자의 패턴을 세부적으로 도출해보자
“사용자들이 우리의 제품을 어떻게 사용하고 있을까? 문제는 없을까?” 이러한 질문과 고민에 가장 기본적으로…
playinpap.github.io
15-5. 검색 조건들의 사용자 행동 가시화하기
SIGN 함수, SUM(CASE~END, AVG(CASE~END), LAG함수, CTR, CVR
- 상품 또는 정보를 검색하는 사이트에는 필터(카테고리, 제조사, 가격대, 지역, 직종...)를 다양하게 제공한다.
- 검색 조건을 더 자세하게 지정하는 사용자는 동기가 명확하다는 의미이므로, 성과로 이어지는 비율이 높다.
- 따라서 검색 조건이 미흡하다면, 검색 조건 지정을 유도해 행동으로 이어지게 만들어 성과를 높일 수 있음
CTR(Click-Through Rate)
: 검색 조건들을 사용해 상세 페이지로 이동한 비율
CVR(Conversion Rate)
: 상세 페이지 조회 후에 성과로 이어지는 비율
→ 검색 타입별 CTR과 CVR을 산점도로 나타냈을 때, CTR이 올라갈 수록 CVR도 올라가는 모습을 보인다.
→ CTR과 CVR이 모두 높고, 검색 조건 쪽으로 사용자를 이동시키면 성과가 늘어날 수 있다.
위와 같은 사실을 집계하는 쿼리 작성해보기

- 검색 타입은 검색 결과 페이지의 URL 매개변수를 분석해서 분류
- CTR의 경우 검색 화면에서 상세 화면으로 1회 이동하건 3회 이동하건 상관없이 이동 수를 모두 1로 취급
- 상세 페이지로의 이동을 의미하는 클릭 플래그 계산
- 최종적으로 컨버전까지 도달했는지를 판별하는 컨버전 플래그를 윈도 함수로 집계
WITH
activity_log_with_session_click_conversion_flag AS(
SELECT
session,
stamp,
path,
search_type,
-- 상세 페이지 이전 접근에 플래그 추가
SIGN(SUM(CASE WHEN path='/detail' THEN 1 ELSE 0 END)
OVER(PARTITION BY session ORDER BY stamp DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW))
AS has_session_click,
-- 성과를 발생시키는 페이지의 이전 접근에 플래그 추가
SIGN(SUM(CASE WHEN path='/complete' THEN 1 ELSE 0 END)
OVER(PARTITION BY session ORDER BY stamp DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW))
AS has_session_conversion
FROM activity_log)
SELECT
session,
stamp,
path,
search_type,
has_session_click AS click,
has_session_conversion AS cnv
FROM
activity_log_with_session_click_conversion_flag
ORDER BY
session, stamp;
검색 타입별로 CTR, CVR 집계하기
SELECT
search_type,
COUNT(*) AS count,
SUM(has_session_click) AS detail,
AVG(has_session_click) AS ctr,
-- detail page click이 있었을 경우 그 세션의 전환 플래그를 합산
SUM(CASE WHEN has_session_click = 1 THEN has_session_conversion END) AS conversion,
AVG(CASE WHEN has_session_click = 1 THEN has_session_conversion END) AS cvr
FROM activity_log_with_session_click_conversion_flag
WHERE
-- 검색 로그만 필터링
path = '/search_list'
-- 검색 조건으로 집약
GROUP BY search_type
ORDER BY count DESC;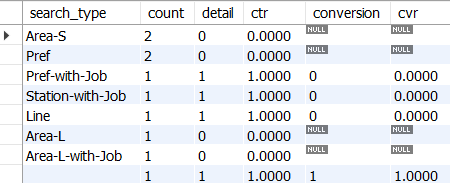
→ 이 쿼리는 /search_list 페이지에서 각 검색 유형별로 사용자들이 얼마나 자주 상세 페이지(/detail)를 클릭하고, 그 클릭이 실제 전환(/complete)으로 이어지는지를 평가하는 데 사용됨
→ 이 경우 1회 방문에서 여러 개의 검색 타입을 검색한 경우에도 각각 모두 카운트 된다.
성과 직전의 검색 결과만을 원할 때에는 LAG함수를 사용하여 상세 페이지로 접근하기 직전의 접근에 플래그 붙여서 CVR 구하기
-- 변경된 부분
-- 기존에는 '/detail'이 session에 포함되어있기만 해도 플래그가 추가되었음
CASE WHEN LAG(path) OVER(PARTITION BY session
ORDER BY stamp DESC) = '/detail' THEN 1 ELSE 0
END AS has_session_clickWITH
activity_log_with_session_click_conversion_flag AS(
SELECT
session,
stamp,
path,
search_type,
-- 상세 페이지 이전 접근에 플래그 추가
CASE WHEN LAG(path) OVER(PARTITION BY session
ORDER BY stamp DESC) = '/detail' THEN 1 ELSE 0
END AS has_session_click,
-- 성과를 발생시키는 페이지의 이전 접근에 플래그 추가
SIGN(SUM(CASE WHEN path='/complete' THEN 1 ELSE 0 END)
OVER(PARTITION BY session ORDER BY stamp DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW))
AS has_session_conversion
FROM activity_log)
SELECT
session,
stamp,
path,
search_type,
has_session_click AS click,
has_session_conversion AS cnv
FROM activity_log_with_session_click_conversion_flag
ORDER BY session, stamp;15-6. 폴아웃 리포트를 사용해 사용자 회유를 가시화하기
LAG 함수, FIRST_VALUEA 함수, 폴아웃
- 최상위페이지에서 확인/완료 화면까지 이어지는 '사용자 회유 흐름'중 어디에서 이탈이 많은지, 어디에서 이동이 이루어지는지 확인하고 개선할 수 있다면 전체적인 CVR을 향상시킬 수 있다.
- 이번 절에서는 중간 지점의 도달률도 함께 집계해보기
폴스루(Fall Through)
: 어떤 지점에서 어떤 지점으로 옮겨가는 것
폴아웃(Fall Out)
: 어떤 지점에서의 이탈
접속자가 다른 페이지를 경유했거나, 직후에 이동했는지와는 관계 없이, 다음 지점에 도달한 방문횟수 집계하기
1. 단계(step) 순서를 번호로 명시한 마스터 테이블(mst_fallout_step)을 작성
- / ▶ /search_list ▶ detail ▶ input ▶ complete
WITH
mst_fallout_step AS(
-- 폴아웃 단계와 마스터 테이블
SELECT 1 AS step, '/' AS path
UNION ALL SELECT 2 AS step, '/search_list' AS path
UNION ALL SELECT 3 AS step, '/detail' AS path
UNION ALL SELECT 4 AS step, '/input' AS path
UNION ALL SELECT 5 AS step, '/complete' AS path),
2. 로그 데이터와 결합, 세션별로 각 step의 처음/마지막 접근 시간 결정
,
activity_log_with_fallout_step AS(
SELECT
l.session,
m.step,
m.path,
-- 첫 접근과 마지막 접근 시간 구하기
MAX(l.stamp) AS max_stamp,
MIN(l.stamp) AS min_stamp
FROM mst_fallout_step AS m
JOIN activity_log AS l
ON m.path = l.path
GROUP BY l.session, m.step, m.path
3. 각 세션의 직전 단계에서의 첫 접근 시간과 세션의 시작 단계, 누적된 단계 수 계산하기
3-1. 각 세션의 현재 단계 바로 이전 단계의 최소 접근 시간 (lag_min_stamp)
-- 직전 단계에서의 첫 접근 시간 구하기
LAG(min_stamp)
OVER(PARTITION BY session ORDER BY step)
AS lag_min_stamp
3-2. 각 세션의 최소 단계 step을 구하여 세션의 '시작' 단계 확인 (min_step)
-- 세션에서의 단계 순서 최소값 구하기
MIN(step) OVER(PARTITION BY session) min_step
3-3. 각 세션에서 현재 단계에 도달하기까지의 누적된 단계(step)의 수 (cum_count) 계산
- step 순서대로 order by
-- 해당 단계에 도달할 때까지 걸린 단계 수 누계
COUNT(*) OVER(PARTITION BY session ORDER BY step
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS cum_count,
activity_log_with_mod_fallout_step AS(
SELECT
session,
step,
path,
max_stamp,
-- 직전 단계에서의 첫 접근 시간 구하기
LAG(min_stamp)
OVER(PARTITION BY session ORDER BY step)
AS lag_min_stamp,
-- 세션에서의 단계 순서 최소값 구하기
MIN(step) OVER(PARTITION BY session) min_step,
-- 해당 단계에 도달할 때까지 걸린 단계 수 누계
COUNT(*) OVER(PARTITION BY session ORDER BY step
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS cum_count
FROM activity_log_with_fallout_step)
SELECT * FROM activity_log_with_mod_fallout_step
ORDER BY session,step;
→ 사용자가 세션 동안 각 단계를 얼마나 빠르게 통과하는지 확인
→ 어떤 단계에서 사용자가 오래 머무르는지 등을 파악
WHERE 조건절
1. min_stamp = 1 일때 : session의 폴아웃의 step 1 인 '/'에서 시작해야 함
2. step = cum_count(현재까지 도달한 단계 수) : 사용자가 폴아웃 단계를 순차적으로 따를 때 (건너뛰는 단계 없이 1,2,3...)
3. lag_min_stamp IS NULL : 이전 단계의 최소 접근 시간이 없음
= 해당 단계가 세션의 첫 번째 단계임
(첫 단계이면 아래 4번인 or 조건을 만족하지 않아도 됨)
4. OR max_stamp >= lag_min_stamp : 현재 단계의 최대 접근 시간이 이전 단계의 최소 접근 시간보다 크거나 같음
= 사용자가 올바른 순서로 진행하고 있음을 확인, 순차적 이동이라면 현재 단계에 이전 단계보다 빨리 도달해서는 안됨
,
fallout_log AS(
SELECT
session,
step,
path
FROM activity_log_with_mod_fallout_step
WHERE
min_step = 1
AND step = cum_count
AND (lag_min_stamp IS NULL
OR max_stamp >= lag_min_stamp))
SELECT * FROM fallout_log
ORDER BY session, step;
DROP TABLE IF EXISTS activity_log;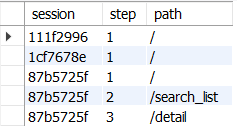
→ step의 첫 단계부터 시작하여 순차적으로 모든 단계를 완료한 세션만 출력
step 순서와 url로 집약하여 '접근 수'와 '페이지 이동률' 집계하기
1. step 1부터의 이동률 (first_trans_rate)
: step1부터 시작하여 각 후속 단계에 도달한 사용자의 비율
2. 직전 단계까지의 이동률 (step_trans_rate)
: 직전 단계 대비 각 단계로의 이동률, 즉 단계 간 전환율
SELECT
step,
path,
COUNT(*) AS count,
-- step=1인 url부터의 이동률
100.0 * COUNT(*) / FIRST_VALUE(COUNT(*))
OVER(ORDER BY step ASC ROWS BETWEEN
UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
AS first_trans_rate,
-- 직전 단계까지의 이동률
100.0 * COUNT(*) / LAG(COUNT(*)) OVER(ORDER BY step ASC)
AS step_trans_rate
FROM fallout_log
GROUP BY step, path
ORDER BY step;
→ 웹사이트가 사용자를 어떻게 유도하는지 대략적으로 파악할 수 있다.
15-7. 사이트 내부에서 사용자 흐름 파악하기
LAG 함수, LEAD 함수, SUM 윈도 함수, 사용자 흐름

- 사용자 흐름 그래프를 추출하기 위해서 무엇을 분석할지와 시작 지점으로 삼을 페이지를 결정하기
- 최상위 페이지에서 어떤 식으로 유도하는지, 상세 화면 전후에서 어떤 행동을 하는지 등의 상세 정보를 얻기 위한 쿼리 작성하기
시작 지점이 되는 페이지를 설정하면, 시작 지점에서 어떤 형태로 유도되는지 정리한 표를 집계하자
(시작 지점, 방문 횟수, 다음 페이지, 방문 횟수 ...)
/detail 페이지 이후의 사용자 흐름 집계하기
1. activity_log_with_lead_path
: 각 세션에서 현재 방문한 경로(path0)와, LEAD함수로 session의 stamp 순서에 따라 다음 행의 path 가져오기
(그 다음에 방문할 두 개의 경로인 path1,2)
WITH
activity_log_with_lead_path AS(
SELECT
session,
stamp,
path AS path0,
LEAD(path, 1) OVER(PARTITION BY session ORDER BY stamp ASC) AS path1,
LEAD(path, 2) OVER(PARTITION BY session ORDER BY stamp ASC) AS path2
FROM activity_log)
2. activity_log_with_lead_path
: path0=/detail로 필터링하여 상세 페이지에서 시작하는 흐름만을 분석하고, path0→1로 이동한 접근 수, path1→2로 이동한 접근 수 계산하기
,
raw_user_flow AS(
SELECT
path0,
-- 시작지점 경로로의 접근 수
SUM(COUNT(*)) OVER() AS count0,
-- 곧바로 접근한 경로로의 접근 수
COALESCE(path1, 'NULL') AS path1,
SUM(COUNT(*)) OVER(PARTITION BY path0, path1) AS count1,
COALESCE(path2, 'NULL') AS path2,
COUNT(*) AS count2
FROM
activity_log_with_lead_path
-- 상세 페이지를 시작 지점으로 두기
WHERE path0 = '/detail'
GROUP BY path0, path1, path2)
3. 최종 select문
: path 0,1,2별 접근수와 백분율 집계
SELECT
path0,
count0,
path1,
count1,
100.0 * count1 / count0 AS rate1,
path2,
count2,
100.0 * count2 / count1 AS rate2
FROM raw_user_flow
ORDER BY count1 DESC, count2 DESC;
위처럼 집계하는 경우 중복된 데이터가 많이 나오기 때문에, 같은 값을 가진 데이터는 출력되지 않게 데이터 가공하기
(너무 길어서 생략 ...)
→ 보통은 리포트 도구등의 사용자 흐름 기능으로 쉽게 해결할 수 있다.
일부 쿼리
1. LAG함수로 바로 위에 있는 레코드의 경로 이름 추출
2. LAG(path0)과 path0의 값이 다른 경우에만 출력 (=중복 제외)
3. LAG함수 값이 NULL이 되는 경우를 COALESCE 함수로 처리
,
raw_user_flow AS(
SELECT
CASE WHEN COALESCE(LAG(path0) OVER(
ORDER BY count1 DESC, count2 DESC),
'NOT FOUND') <> path0 THEN path0,
CASE WHEN COALESCE(LAG(path0) OVER(
ORDER BY count1 DESC, count2 DESC),
'NOT FOUND') <> path0 THEN count0,
CASE WHEN COALESCE(LAG(CONCAT(path0,path1))
OVER(ORDER BY count1 DESC, count2 DESC),
'NOT FOUND') <> CONCAT(path0,path1) THEN count1
END AS count1,
이전 페이지 집계하기
지금까지 /detail 페이지를 시작 지점으로, 이후 흐름을 살펴보았으니 이번에는 그 이전 흐름 두 단계까지 집계해보기
(쿼리는 동일하나, LEAD함수만 LAG함수로 변경하면 됨)
WITH
activity_log_with_lead_path AS(
SELECT
session,
stamp,
path AS path0,
COALESCE(LAG(path, 1) OVER(PARTITION BY session ORDER BY stamp ASC), 'NULL') AS path1,
COALESCE(LAG(path, 2) OVER(PARTITION BY session ORDER BY stamp ASC), 'NULL') AS path2
FROM activity_log),
raw_user_flow AS(
SELECT
path0,
-- 시작지점 경로로의 접근 수
SUM(COUNT(*)) OVER() AS count0,
-- 곧바로 접근한 경로로의 접근 수
path1,
SUM(COUNT(*)) OVER(PARTITION BY path0, path1) AS count1,
path2,
COUNT(*) AS count2
FROM
activity_log_with_lead_path
-- 상세 페이지를 시작 지점으로 두기
WHERE path0 = '/detail'
GROUP BY path0, path1, path2)
SELECT
path2,
count2,
100.0 * count2 / count1 AS rate2,
path1,
count1,
100.0 * count1 / count0 AS rate1,
path0,
count0
FROM
raw_user_flow
ORDER BY count1 DESC, count2 DESC;
15-8. 페이지 완독률 집계하기
SUM(CASE~END), 완독률
- 직귀율, 이탈률, 페이지로는 사용자가 페이지를 끝까지 조회했는지는 알 수 없다.
- 특정 콘텐츠의 완독률이 낮다면, 해당 종류의 콘텐츠가 사용자가 원하지 않는 것일 수도 있고,
- 전체적인 완독률이 낮다면, 페이지의 가독성이 낮을 가능성이 높다.
사용 데이터
: 20%, 40% .. 얼마나 조회했는지에 대한 정보가 기록된 테이블

완독률 집계하기
: 각 url에서 현재 action이 view 동작 중 얼마나 자주 발생하는지 백분율로 나타내기
SELECT
url,
action,
COUNT(*) AS count,
100.0 * COUNT(*) / SUM(CASE WHEN action='view'
THEN COUNT(*) ELSE 0 END)
OVER(PARTITION BY url)
AS action_per_view
FROM read_log
GROUP BY url, action
ORDER BY url, count DESC;
15-9. 사용자 행동 전체를 시각화하기
조감도를 사용해 사용자 행동 시각화하기
- 사용자가 최상위 페이지를 기반으로 접근할 것으로 생각하고 해당 페이지를 최적화했지만, 실제 사용자는 최상위 페이지가 아닌 검색 등의 상세 화면으로 들어오는 경우가 많으면 최적화에 아무 의미가 없음
- 입력 양식 최적화에 주력했지만, 입력 양식까지 가는 과정에서 힘든 부분이 있었던 것이라면 최적화에 큰 의미가 없음
따라서 조감도를 작성함으로써 최적화에 주력해야 하는 부분과 아닌 부분을 파악해야 함
서비스 형태에 맞게 조감도 작성하기
- 서비스의 이용 상황과 매출처럼 개별적인 서비스 상황을 파악할 떄에도 활용 가능
- 서비스와 조직의 상황을 파악하고, 멤버 전원이 서비스의 상황을 이해할 수 있도록 하고 길을 제시할 수 있어야 함
'SQL > 데이터 분석을 위한 SQL레시피' 카테고리의 다른 글
| [17,18] 데이터를 조합해서 새로운 데이터 만들기, 이상값 검출하기 - 크롤러 제외, 데이터 타당성 확인, 특정 IP주소 제외하기 (1) | 2024.03.23 |
|---|---|
| [16] 입력 양식 최적화하기 (3) | 2024.03.06 |
| [14] 사이트 내의 사용자 행동 파악하기(1) - landing/exit 페이지 파악하기, 이탈률/직귀율 계산하기, 성과로 이어지는 페이지 파악하기, 페이지 가치 산출하기 (1) | 2024.02.25 |
| 데이터 분석을 위한 SQL 레시피 15강보충 - 성과 측정을 위한 지표 정의 (0) | 2024.02.25 |
| [13] 웹사이트에서의 행동을 파악하는 데이터 추출 - 사이트 전체의 특징/경향 찾기 : 유입원/접근요일 별 방문자 수 파악 (0) | 2024.02.17 |



