
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 그로스 해킹
- sql
- 컨브넷
- python
- pmdarima
- 로그 변환
- 스태킹 앙상블
- ImageDateGenerator
- 데이터 정합성
- 캐글 산탄데르 고객 만족 예측
- ARIMA
- 데이터 증식
- 그로스 마케팅
- 3기가 마지막이라니..!
- splitlines
- Growth hacking
- 인프런
- lightgbm
- WITH CUBE
- DENSE_RANK()
- 데이터 핸들링
- 마케팅 보다는 취준 강연 같다(?)
- 리프 중심 트리 분할
- 분석 패널
- 그룹 연산
- 부트 스트래핑
- WITH ROLLUP
- 캐글 신용카드 사기 검출
- tableau
- XGBoost
- Today
- Total
LITTLE BY LITTLE
[7] 엑셀로 하는 데이터 분석 - EDA, 데이터 전처리, 함수&피벗테이블로 데이터 불러오기, 개수 파악 본문
[7] 엑셀로 하는 데이터 분석 - EDA, 데이터 전처리, 함수&피벗테이블로 데이터 불러오기, 개수 파악
위나 2023. 2. 27. 22:26
목차
7. 엑셀로 하는 데이터 분석
데이터 분석 기초 / EDA의 중요성 / 기초 통계량 계산 / 피벗테이블 활용 / BOXPLOT과 산점도 그리기
/ 데이터 전처리(날짜 데이터 처리, 카테고리 지정하기, 필요한 데이터 불러오기[VLOOKUP])
/ 데이터 가공(필요한 데이터 불러오기[VLOOKUP X MATCH], 피벗테이블 활용, COUNT 계열 함수로 개수 파악
, 데이터 분석 도구 추가, 상관 분석, 분산분석, 회귀분석, 시계열 분석[FORCAST.ETS])
7. 엑셀로 하는 데이터 분석
1. 엑셀로 하는 EDA
- 기초통계량 계산
- 피벗 테이블 사용하기 - 필터, 행, 열, 값에 각각 다른 값을 넣어보며 데이터 구조 확인
- Boxplot과 산점도 그리기
- Boxplot 삽입 후, 차트 요소 추가 - 양의 값/ 음의 값 - 오차량 '사용자 지정' - 양의 오류값을 최대값으로, 음의 오류값을 최솟값으로 지정
2. 엑셀로 하는 데이터 전처리
2-1. 날짜 데이터 처리
- 날짜 데이터의 원리 : 엑셀에서 날짜를 입력하는 기본 형태는 '-' 하이픈 사용, 하이픈을 사용해서 날짜 입력시, 서식이 자동으로 [일반]에서 [날짜]로 변경 됨
- 다시 [날짜]에서 [일반]으로 변경시, 숫자로 데이터가 변경되고, 그 숫자는 1900-01-01부터 경과한 일 수
- 따라서 날짜 데이터가 정수로 나온다면, 서식을 [날짜]로 바꿔주기
- 기간이 계산될 때에는(ex. days 함수), 종료일은 기간에서 자동으로 제외된다. 따라서 종료일을 기간에 포함시켜야 하는 겨우 기간을 구하는 수식에 +1해주기
- 날짜 데이터로 변환해야 하는 경우, (ex. 2020.10.01 => 2020-10-01) Ctrl+F 모두바꾸기 기능 활용하기
2. 엑셀로 하는 데이터 전처리
2-2. 특정 단어,문장 추출하기
- FIND 함수
- FIND ( 찾을 텍스트, 찾을 텍스트가 있는 텍스트, 몇 번째 문자열부터 찾기 시작할지 설정[default는 맨 왼쪽] )
- LEFT, RIGHT, MID 함수
- LEFT ( 텍스트, 불러올 문자열의 수)
- RIGHT ( 텍스트, 불러올 문자열의 수)
- MID ( 텍스트, 시작 위치, 불러올 문자열의 수 )
- 여기서 시작 위치를 FIND함수 결과값으로 지정하여 사용하는 경우가 많음
게임 리뷰 평점&댓글 분석하기
1. 파이썬으로 ratings, date, helpful, comment, developer_comment 긁어오기
2. 코멘트 중 '과금', '현질', '돈'이라는 단어가 한 번이라도 나온 여부 확인하기
- '과금', '현질', '돈' 열을 만들어서, =IFERROR ( FIND ( 코멘트 범위에 절대 참조, 0) ) 함수 사용, 해당 단어가 등장한 적이 있다면 몇 번째에 등장했는지, 없다면 0을 출력하도록 하기
- '과금불만합계' 열을 만들어서, 세 단어 중 한 번이라도 등장한 적이 있는지 여부 확인하기
- SUM 함수를 써서 0보다 큰 란은 한 번이라도 해당 단어가 들어간 적 있다는 것을 알 수 있도록 하기
3. 코멘트 중 과금불만합계가 있는 것을 제외한 코멘트만 다른 시트에 붙여넣기
- 여기서는 '질문', '그래픽', '설치', '다운', '깔아', '접속', '설치다운깔아접속', sub_category, category 열 만들기
- 질문 : =FIND ( "?", '범위에 절대참조' ), 나머지 "?" 자리에 각각 "그래픽", "설치", ...
- 위와 같이 SUM을 하여 한 번이라도 언급했는지 확인하기
2. 엑셀로 하는 데이터 전처리
2-3. 카테고리 지정하기 (대/중/소 분류) - IF 중첩 & VLOOKUP
- 위에서 한 전처리로 category와 sub_category로 분류하기
- IF 중첩
- '질문'란이 0보다 큰 경우, '문의'로 '그래픽'란이 0보다 크면 '그래픽', ... sub_category 먼저 분류하기
- '설치','다운','깔아','접속'을 '장애'라는 큰 카테고리로 묶기
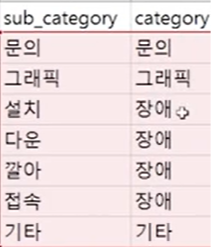
- VLOOKUP으로 sub_category를 더 큰 category로 묶기
- category란에 크게 묶고 싶은 세 가지 '문의', '그래픽', '장애'를 적어준 뒤에,
- VLOOKUP ( 문의, 위 사진 sub_category와 category를 범위로 지정, 2를 적어 기준 열인 sub_category에서 2번째인 category란의 값으로 불러오기, 0 )
3. 데이터 가공 - 필요한 데이터 불러오기
3-1. VLOOKUP & MATCH 활용
- 먼저 두 개 이상의 조건을 충족하는 데이터를 불러오고자 할 경우, &연산자를 활용해 다른 열에 모든 조건을 연결한 새로운 데이터를 [가장 왼쪽에] 입력해야 한다. (EX. 1월, 31일, 서울 데이터 => '1월31일서울' 을 한 열에 입력)
- 중복 값을 해소할 수 있는 기법
- VLOOKUP ( 입력한 연결된 값, 범위, 기준 열으로부터 몇 번째인지, 0 OR 1)
- 여기서 절대 참조를 거는 것이 중요, 서울 뿐만 아니라 1월 31일의 대구, 부산의 데이터도 찾고자하는 경우 VLOOKUP이 불러오는 데이터가 변화하는 방향이 아닌 행 OR 열에 $ 절대참조 걸기
- 몇 번째인지 입력하는 것도 직접 '숫자'를 입력하는 대신 빈 열에 숫자를 써서 '셀'을 입력하기
- +,-로 열 숫자 조정 가능 : 만약 1을 입력했을 때 1월의 데이터가, 12를 입력했을 때 12월의 데이터가 나오게 하고 싶은 경우, 기준 열부터 3번째가 1월이라면 빈 셀에 3대신 1을 입력하고, +2 해주기
- MATCH ( 찾고 싶은 값, 찾고 싶은 값이 포함된 단일 열/행 범위, match_type )
- VLOOKUP과 함께 사용, VLOOKUP 함수 속의 기준 열부터 몇 번째 인지 (col_index) 쓰는 란에 match함수 결괏 값 입력
- INDEX와 함께 사용, INDEX 함수 속의 INDEX ( 범위, 찾을 값의 행 번호, 찾을 값의 열 번호, 범위 선택 ) 에서 찾을 값의 행/열 번호 대신 match함수 결괏값 입력
3. 데이터 가공 - 필요한 데이터 불러오기
3-2.피벗테이블 활용
피벗테이블이 어려운 이유는 어떤 요약 통계표를 만들어야 하는지 명확하지 않기 때문이다. 어떤 피벗 테이블을 만들지 손으로 먼저 그려보기
- 값 필드 설정
- 값에 데이터를 넣고, 우클릭하면 '값 요약 기준'에서 (합계, 평균 .. 등) 계산 유형을 바꿀 수도 있고, '값 표시 형식'에서 계산법 (누계, 상위 행 합계 비율..등)을 바꿀 수도 있다.
- VLOOKUP 대신 피벗테이블로 데이터를 불러올 수 있다.
3. 데이터 가공 - 필요한 데이터 불러오기
3-3. COUNT 계열 함수로 개수 파악하기
COUNTIFS ( 개수를 세어야 할 값들이 있는 셀의 전체 범위 1, range 1에서 세어야 하는 조건 값 1, ~전체 범위 2, 조건 값 2 ...)
- EX. 전체 리뷰 중 평점이 5점인 개수 세기
- COUNTIF ( raw data 속 ratings 열 전체 선택 [절대 참조 걸어주기] , 새로운 시트 속 평점 5점 선택하고 아래로만 이동할 수 있도록 B앞에만 $걸어주기 )
- 리뷰 개수를 합계로 나누어 비율도 계산해주기
- EX. 리뷰 중 평점에 따른 '과금'댓글 개수 세기
- COUNTIFS ( 위에서 평점 5점인 개수 센 것과 동일한 전체 범위, 조건 값 입력 , '과금불만합계' 열 전체 선택, 조건으로 부등식 따옴표 안에 입력 ">0" )
- 앞서 댓글 속 과금불만합계(개수)를 계산했었음
- COUNTIFS ( 위에서 평점 5점인 개수 센 것과 동일한 전체 범위, 조건 값 입력 , '과금불만합계' 열 전체 선택, 조건으로 부등식 따옴표 안에 입력 ">0" )
- 같은 방식으로 EX. 리뷰 중 월별 평점 데이터 개수를 세는 경우, 첫 번째 범위와 조건값으로 평점 5점인 개수 센 것과 동일하게 입력하고, raw data에서 월 열 전체 선택 후 새 시트에서 우측 12,1월..로 이동할 수 있게 11월 선택 )



