
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- WITH CUBE
- 그로스 마케팅
- 데이터 핸들링
- 부트 스트래핑
- pmdarima
- 캐글 신용카드 사기 검출
- ARIMA
- WITH ROLLUP
- DENSE_RANK()
- 데이터 정합성
- python
- 마케팅 보다는 취준 강연 같다(?)
- 인프런
- 스태킹 앙상블
- tableau
- ImageDateGenerator
- sql
- 로그 변환
- 리프 중심 트리 분할
- Growth hacking
- 캐글 산탄데르 고객 만족 예측
- 데이터 증식
- splitlines
- 컨브넷
- lightgbm
- 그룹 연산
- 3기가 마지막이라니..!
- 그로스 해킹
- XGBoost
- 분석 패널
- Today
- Total
LITTLE BY LITTLE
[5] 케라스 창시자에게 배우는 딥러닝 - 5. 컴퓨터 비전을 위한 딥러닝( 사전 훈련된 컨브넷 사용하기 : 특성추출(데이터 증식사용有 ,無)과 미세조정, 컨브넷 학습 시각화) 본문
[5] 케라스 창시자에게 배우는 딥러닝 - 5. 컴퓨터 비전을 위한 딥러닝( 사전 훈련된 컨브넷 사용하기 : 특성추출(데이터 증식사용有 ,無)과 미세조정, 컨브넷 학습 시각화)
위나 2022. 9. 5. 22:23제 5부.컴퓨터 비전을 위한 딥러닝
합성곱 신경망 소개소규모 데이터셋에서 밑바닥부터 컨브넷 훈련하기- 사전 훈련된 컨브넷 사용하기
- 컨브넷 학습 시각화
- 요약
제 6부. 텍스트와 시퀀스를 위한 딥러닝
- 텍스트 데이터 다루기
- 순환 신경망 이해하기
- 순환 신경망의 고급 사용법
- 컨브넷을 사용한 시퀀스 처리
- 요약
제 7부. 딥러닝을 위한 고급 도구
- Sequential 모델을 넘어서 : 케라스의 함수형 API
- 케라스 콜백과 텐서보드를 사용한 딥러닝 모델 검사와 모니터링
- 모델의 성능을 최대화로 끌어올리기
- 요약
제 8부. 생성 모델을 위한 딥러닝
- LSTM으로 텍스트 생성하기
- 딥드림
- 뉴럴 스타일 트랜스퍼
- 변이형 오토인코더를 사용한 이미지 생성
- 적대적 생성 신경망 소개
- 요약
제 9부. 결론
- 핵심 개념 리뷰
- 딥러닝의 한계
- 딥러닝의 미래
- 빠른 변화에 뒤처지지 않기
- 맺음말
5-3. 사전 훈련된 컨브넷 사용하기
- 작은 이미지 데이터셋에 딥러닝을 적용하는 일반적인 방법 = 사전 훈련된 네트워크 사용
- 새로운 문제가 완전히 다른 것이더라도, 많은 컴퓨터 비전 문제에 유용
- ex.대부분 동물,생활용품으로 이루어진 Image Net 데이터셋에 네트워크를 훈련한다. 그 후 이 네트워크를 이미지에서 가구 아이템을 식별하는 것과 같은 다른 용도로 사용 가능
- 1400만 개의 레이블된 이미지와 1000개의 클래스로 이루어진 ImageNet 데이터셋에서 훈련된 대규모 컨브넷을 사용해보자.
- VGG16 구조 사용 - 이외에 Inception, ResNet, Inception-ResNet, Xception 등이 있다.
- 사전 훈련된 네트워크를 사용하는 두 가지 방법이 있다.
- 특성 추출 feature extraction
- 미세 조정 fine tuning
5-3-1. 특성 추출
- 특성 추출이란, " 사전에 학습된 네트워크의 표현을 사용하여 새로운 샘플에서 흥미로운 특성을 뽑아내는 것 "
- 이런 특성을 사용하여 새로운 분류기를 처음부터 훈련함
- 컨브넷은 이미지 분류를 위해 두 부분으로 구성된다.
- 먼저 연속된 합성곱과 풀링 층으로 시작해서
- 완전 연결 분류기로 끝남
- 첫 번째 부분 = 합성곱 기반층(convolutional base)
- 컨브넷의 경우 특성 추출은 1. 사전에 훈련된 네트워크의 합성곱 기반 층을 선택, 2.새로운 데이터를 통과시키고, 3. 그 출력으로 새로운 분류기 훈련 (위 그림 참고)
- 합성곱 층만 재사용하는 이유? (완전 연결 분류기는 재사용을 권장하지 않는 이유 )
- => 합성곱 층에 의해 학습된 표현이 더 일반적이어서 재사용이 가능하기 때문
- 컨브넷의 특성 맵은 사진에 대한 일반적인 콘셉트의 존재 여부를 기록한 맵
- 분류기에서 학습한 표현은 모델이 훈련된 클래스 집합에 특화되어 있음
- 분류기는 전체 사진에 어떤 클래스가 존재할 확률에 관한 정보만 담고 있음
- 완전 연결층에서 찾은 표현은 더 이상 입력 이미지에 있는 객체의 위치 정보를 가지고 있지 않음
- 완전 연결층은 공간 개념을 제거하지만, 합성곱의 특성 맵은 객체의 위치를 고려함
- => 객체의 위치가 중요한 문제라면 완전 연결 층에서 만든 특성은 크게 쓸모가 없다.
- => 합성곱 층에 의해 학습된 표현이 더 일반적이어서 재사용이 가능하기 때문
- 특정 합성곱 층에서 추출한 표현의 일반성과 재사용성 수준은 모델에 있는 층의 깊이에 달려있다.
- 모델의 하위층은 색깔, 질감, edge 등 지역적이고 일반적인 특성 맵 추출
- 모델의 상위층은 강아지의 눈, 고양이의 귀처럼 좀 더 추상적인 개념 추출
- => 새로운 데이터셋이 원본 모델이 훈련한 데이터셋과 많이 다르다면 전체 합성곱 기반 층을 사용하는 것보다는 모델의 하위 층 몇 개만 특성 추출에 사용하는 것이 좋다.
- 합성곱 층만 재사용하는 이유? (완전 연결 분류기는 재사용을 권장하지 않는 이유 )
- Image Net의 클래스 집합에는 여러 종류의 강아지와 고양이 포함
- => 이런 경우, 원본 모델의 완전 연결층에 있는 정보를 재사용하는 것이 도움이 되나, 새로운 문제의 클래스가 원본 문제의 클래스 집합과 겹치지 않는다고 생각하고 완전 연결층을 사용하지 않을 예정
- Image Net 데이터셋에 훈련된 VGG16 네트워크의 합성곱 기반 층을 사용하여 강아지와 고양이 이미지에서 유용한 특성을 추출해보자. 그 다음, 이 특성으로 강아지 VS 고양이 분류기 훈련
- VGG16 모델은 keras.applications 모듈에서 임포트 ( 이외에 Xception, Inception V3, ResNet50, VGG16, VGG19, MobileNet 임포트 가능)
# VGG16 합성곱 기반 층 만들기
from tensorflow.keras.applications import VGG16
conv_base = VGG16(weights='imagenet', include_top=False, input_shape=(150,150,3))# VGG 합성곱 기반 층의 자세한 구조
conv_base.summary()[Out]
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 150, 150, 3)] 0
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________* VGG 함수에 3개의 매개변수 전달 가능
- weights : 모델을 초기화할 가중치 체크포인트 지정
- include_top : 네트워크의 차상위 완전 연결 분류기 포함여부 지정
- 기본 값은 ImageNet의 클래스 1,000개에 대응되는 완전 연결분류기 포함
- 여기서는 별도의 완전 연결층을 추가하고자 하므로, 포함시키지 않음
- input_shape(선택) : 네트워크에 주입할 이미지 텐서의 크기, 입력 안할시 네트워크는 어떤 크기의 입력도 처리 가능
- 최종 특성 맵의 크기는 (4,4,512) , 이 특성 위에 완전 연결 층을 놓을 것
- 이 지점에서 두 가지 방식 사용 가능
- 새로운 데이터셋에서 합성곱 기반층 실행 => 출력을 넘파이 배열로 디스크에 저장 => 독립된 완전 연결 분류기에 입력으로 사용
- 모든 입력 이미지에 대해 합성곱 기반 층을 한번만 실행하면 됨 => 빠르고 비용적게 듦
- 데이터 증식 사용 불가능
- 준비한 모델 conv_base 위에 Dense층을 쌓아 확장 => 입력 데이터에서 end-to-end로 전체 모델 실행
- 모델에 노출된 모든 입력이미지가 매번 합성곱 기반 층 통과 => 데이터 증식 사용 가능
- 비용이 많이 듦
- 새로운 데이터셋에서 합성곱 기반층 실행 => 출력을 넘파이 배열로 디스크에 저장 => 독립된 완전 연결 분류기에 입력으로 사용
특성 위에 완전 연결층을 놓는 1번째 방법 - 데이터 증식을 사용하지 않는 빠른 특성 추출
- ImageDataGenerator을 사용하여 이미지와 레이블을 넘파이 배열로 추출
- conv_base 모델의 predict 메소드를 호출하여 이미지에서 특성 추출
** 이미지 압축 해제 및 분리 과정에서 자꾸 에러 나서 다시 해보기..
# 사전 훈련된 합성곱 기반 층을 사용한 특성 추출 방법1. 이미지 증식 없이 빠른 특성 추출
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
base_dir = ''
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1./255)
batch_size=20
def extract_features(directory, sample_count):
features = np.zeros(shape=(sample_count, 4,4,512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(
directory,
target_size=(150,150),
batch_size=batch_size,
class_mode='binary')
i=0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i*batch_size : (i+1)*batch_size] = features_batch
labels[i*batch_size : (i+1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count:
break
return features, labels
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)=> 추출된 특성의 크기는 (samples, 4, 4, 512)
=> 완전 연결 분류기에 주입하기 위해서 먼저 (samples, 892) 크기로 펼치기
train_features = np.reshape(train_features, (2000, 4*4, 512))
validation_features = np.reshape(validation_features, (1000, 4*4*512))
test_features = np.reshape(test_features, (1000, 4*4*512))완전 분류기를 정의하고 (규제를 위해 드롭아웃 사용) 저장된 데이터와 레이블을 사용하여 훈련
from keras import models
from keras import layers
from keras import optimizers
model = model.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=4*4*512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer = optimizers.RMSprop(lr=2e-5),loss = 'binary_crossentropy', metrics=['acc'])
history = model.fit(train_features, train_labels, epochs=30,batch_size=20,valiation_data=(validation_features, validation_labels))2개의 Dense층만 처리하면 되기 때문에 속도가 매우 빠르다.
훈련 손실과 정확도 곡선을 살펴보자.
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label = 'Training acc')
plt.plot(epochs, val_acc, 'b', label = 'validation acc')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label = 'Training loss')
plt.plot(epochs, val_loss, 'b', label= 'Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()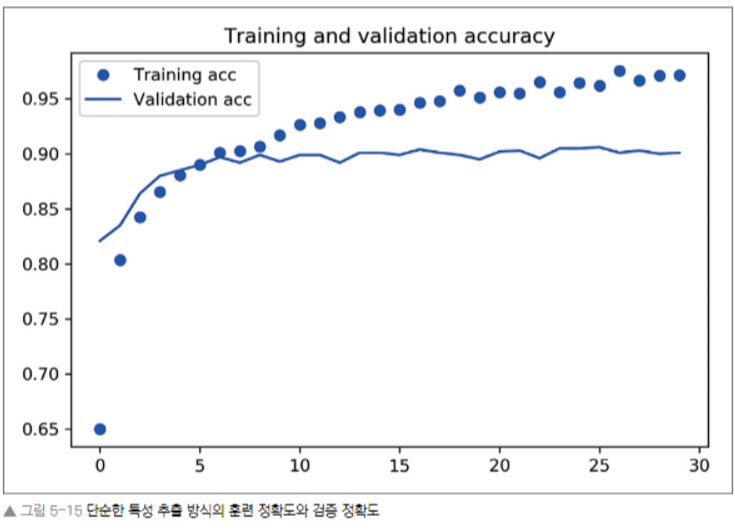
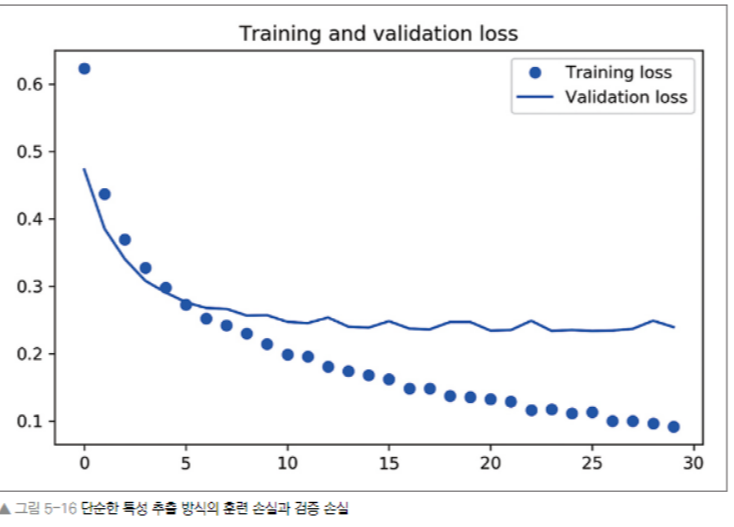
90%의 검증 정확도 도달. 하지만, 드롭아웃을 사용했음에도 거의 바로 과적합되고 있다. 데이터 증식을 사용안했기 때문
특성 위에 완전 연결층을 놓는 2번째 방법 - 데이터 증식을 사용하는 특성 추출
연산 비용이커서 GPU를 사용할 수 있을 때 가능
conv_base 모델을 확장하고, 입력 데이터를 사용하여 end-to-end로 실행하자.
모델은 층과 동일하게 작동하므로 층을 추가하듯이 Sequential 모델에 (conv_base 같은) 다른 모델을 추가할 수 있다.
# 합성곱 기반의 층 위에 완전 연결 분류기 추가하기
from keras import models
from keras import layers
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()[Out]
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 4, 4, 512) 14714688
flatten (Flatten) (None, 8192) 0
dense (Dense) (None, 256) 2097408
dense_1 (Dense) (None, 1) 257
=================================================================
Total params: 16,812,353
Trainable params: 16,812,353
Non-trainable params: 0
_________________________________________________________________=> VGG16의 합성곱 기반 층은 14,714,688개의 매우 많은 파라미터를 가지고 있으며. 합성곱 기반 층 위에 추가한 분류기는 200만개의 파라미터를 가진다.
- 모델을 컴파일하고 훈련하기 전, 합성곱 기반 층을 동결하는 것이 중요하다.
(층을 동결하는 것은 훈련하는 동안 가중치가 업데이트 되지 않도록 막는다는 뜻)
=> 만약 동결하지 않을시, 합성곱 기반 층에 의해 사전에 학습된 표현이 훈련하는 동안 수정되고, 맨 위의 Dense 층은 랜덤하게 초기화되었기 때문에 매우 큰 가중치 업데이트 값이 네트워크에 전파될 것, 그렇게되면 사전에 학습된 표현을 크게 훼손하게 된다.
=> Keras에서는 trainable 속성을 False로 설정하여 네트워크 동결 가능
# 데이터 증식을 사용한 특성 추출
# 동결된 합성곱 기반 층과 함께 모델을 end-to-end로 훈련하기
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
train_datagen = ImageDataGenerator(
rescale = 1./255,
rotation_range = 20,
width_shift_range = 0.1,
height_shift_range = 0.1,
shear_range = 0.1,
zoom_range = 0.1,
horizontal_flip = True,
fill_mode = 'nearest')
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150,150), # 모든 이미지의 크기를 150x150으로 변경
batch_size=20,
class_mode='binary') # binary_crossentropy 손실을 사용하므로 이진 레이블 필요
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150,150),
batch_size=20,
class_mode='binary')
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['acc'])
history = model.fit_generator(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
vallidation_steps=50,
verbose=2)결과 그래프를 다시 그려보자.


검증 정확도는 약 90으로 비슷하나, 데이터 증식을 사용하여 과대적합은 줄었다.
5-3-2. 미세 조정
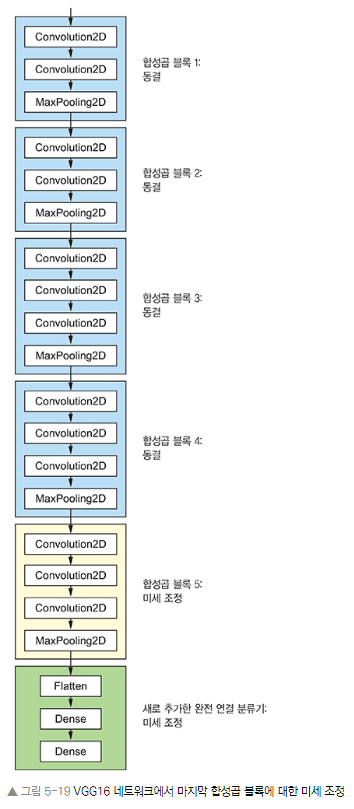
- 모델 재사용 기법 특성 추출을 보완하는 또 다른 기법은 미세 조정이다. 특성 추출에 사용했던 동결 모델의 상위 층 몇 개를 동결에서 해제하고 모델에 새로 추가한 층(여기서는 완전 연결 분류기)과 함께 훈련하는 것
- 앞서 랜덤하게 초기화된 상단 분류기 훈련을 위해서는 VGG16의 합성곱 기반 층을 동결해야 한다고 말했듯이,
- 맨 위에 있는 분류기가 훈련된 후에, 합성곱 기반의 상위 층 미세조정이 가능하다.
- 네트워크 미세 조정 단계는
- 사전 훈련된 기반 네트워크 위에 새로운 네트워크 추가
- 기반 네트워크 동결
- 새로 추가한 네트워크 훈련 (여기 까지는 특성 추출시 이미 완료됨)
- 기반 네트워크에서 일부 층을 동결 해제
- 동결을 해제한 층과 새로 추가한 층을 함께 훈련
합성곱 기반 층의 구조 재확인
conv_base.summary()[Out]
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 150, 150, 3)] 0
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________=> 마지막 3개의 합성곱 층을 미세조정하자.
=> 즉, black4_pool까지는 모든 층 동결
=> block5_conv1, block_5_conv2, block5_conv3은 학습 대상이 됨
=> 전체 혹은 더 많은 층을 미세조정하고자 한다면, 다음 사항 고려
- 합성곱 기반 층에 있는 하위 층들은 좀 더 일반적이고 재사용 가능한 특성들을 인코딩하는 반면, 상위 층은 좀 더 특화된 특성을 인코딩한다. 새로운 문제에 재활용하도록 수정이 필요한 것은 구체적인 특성이므로 이들을 미세조정하는 것이 유리하다. 하위 층으로 갈수록 미세조정에 대한 효과가 감소한다.
- 훈련해야 할 파라미터가 많을수록 과대적합의 위험이 커진다. 합성곱 기반 층은 1,500만 개의 파라미터를 가지고 있다. 작은 데이터셋으로 전부 훈련하려고 하면 매우 위험함
- 그래서 여기서는 합성곱 기반 층에서 최상위 2-3개 층만 미세조정하는 것
네트워크 미세조정 단계 4. 기반 네트워크에서 일부 층을 동결 해제
# 미세 조정
# 하기 전에 특정 층까지 모든 층 동결하기
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False네트워크 미세조정 단계 5. 동결을 해제한 층과 새로 추가한 층을 함께 훈련
# 모델 미세 조정하기
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=le-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data = validation_generator,
validation_steps=50)이전과 동일한 코드로 training and validation 정확도 그리기
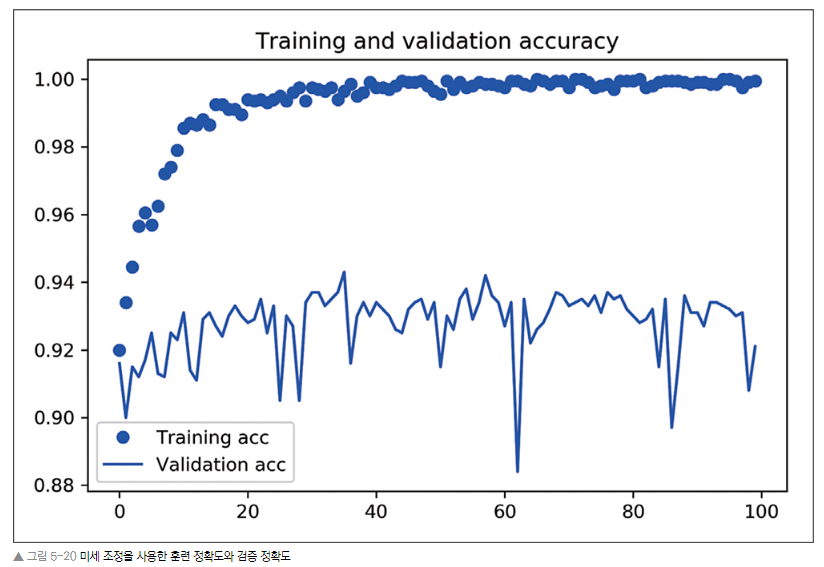
그래프가 불규칙해 지수 이동 평균으로 정확도와 손실값을 부드럽게 표현하기
# 부드러운 그래프 그리기 - 지수 이동 평균을 구하는 간단한 함수
def smooth_curve(points, factor=0.8):
smoothed_points= [ ]
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous*factor+point*(1-factor))
else:
smoothed_points.append(point)
return smoothed_points
plt.plot(epochs, smooth_curve(acc), 'bo', label='Smoothed training acc')
plt.plot(epochs, smooth_curve(val_acc), 'b', label='Smoothed validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, smooth_curve(loss), 'bo', label='Smoothed training loss')
plt.plot(epochs, smooth_curve(val_loss), 'b', label='Smoothed validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.figure()
plt.show()[Out]
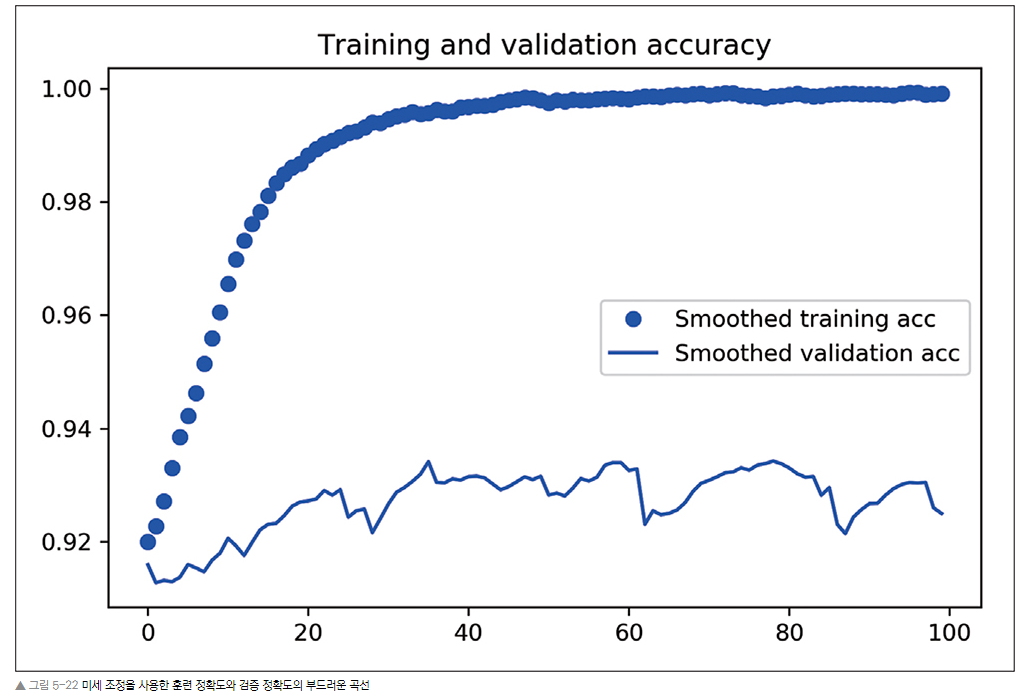

앞서 특성 추출 (데이터 증식 이용) 까지 한 그래프와 비교(▼)

=> 정확도가 약 1% 향상되었다.
=> 손실 곡선은 약화되었다.(늘어남)
=> 그럼에도 불구하고, 정확도가 향상될 수 있는 이유는
- 그래프는 '개별적인'손실 값의 평균을 구한 것이기 때문이다.
- 정확도에 영향을 미치는 것은 손실 값의 분포이지, 평균이 아니다.
- 정확도는 모델이 예측한 클래스 확률이 어떤 임계 값을 넘었는지에 대한 결과
- 따라서 모델이 더 향상되더라도(정확도), 평균 손실에 반영되지 않을 수 있음
마지막으로 테스트 데이터에서 모델을 평가해보자.
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150,150),
batch_size = 28,
class_mode = 'binary')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)
print('test acc:', test_acc)=> 92% 정도의 테스트 정확도가 나온다.
5-3-3. 정리
1. 컨브넷은 컴퓨터 비전 작업에 가장 뛰어난 머신러닝 모델
2. 작은 데이터셋에서는 과대적합이 문제, 데이터 증식이 강력한 해결 방법
3. 특성 추출 방식으로 새로운 데이터셋에 기존 컨브넷을 쉽게 재사용할 수 있다. 작은 이미지 데이터셋으로 작업할 때 효과적인 기법
4. 특성 추출을 보완하기 위해 미세조정 사용 가능, 미세 조정은 기존 모델에서 사전에 학습한 표현의 일부를 새로운 문제에 적용시킴
5.4 컨브넷 학습 시각화
5.4.1 중간층의 활성화 시작하기
- 어떤 입력이 주어졌을 때, 네트워크에 있는 여러 합성곱과 풀링 층이 출력하는 특성 맵을 그려보자. (층의 출력 = 활성화 함수의 출력이라서 '활성화'라고 부른다.)
from keras.models import load_model
model = load_model ('cast_and_dogs_small_2.h5') # 5.2에서 저장했던 모델
model.summary()네트워크 훈련시 사용했던 이미지에 포함되지 않은 고양이 사진 하나를 입력 이미지로 선택한다.
# 개별 이미지 전처리하기
img_path = './datasets/cats_and_dogs_small/test/cats/cats.1700.jpg'
from keras.preprocessing import image
import numpy as np
img = image.load_img(img_path, target_size=(150,150))
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor,axis=0)
img_tensor/=255.
print(img_tensor.shape)import matplotlib.pyplot as plt
plt.imshow(img_tensor[0])
plt.show()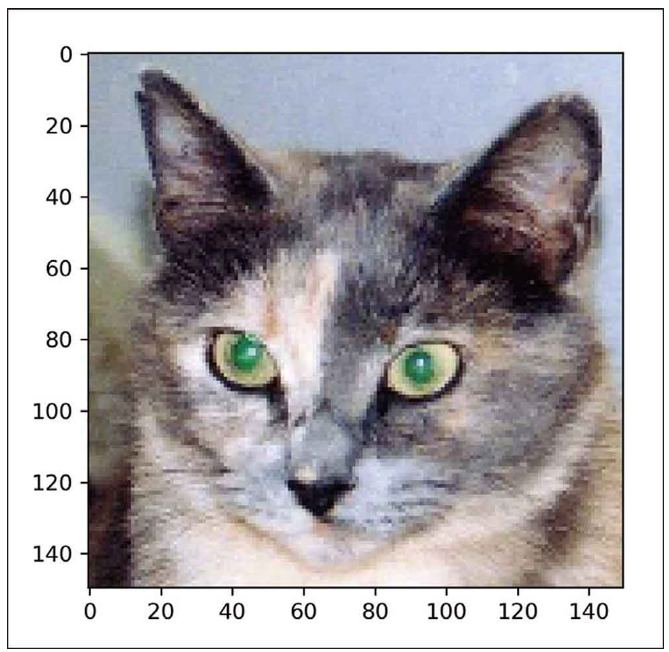
확인하고 싶은 특성 맵을 추출하기 위해 이미지 배치를 입력으로 받아모든 합성곱과 풀링 층의 활성화를 출력하는 케라스 모델을 만들어보자.
- 케라스의 Model 클래스 사용
- 모델 객체를 만들 때 2개의 매개변수가 필요 - 입력 텐서와 출력 텐서
- 반환되는 객체는 Sequential과 같은 케라스 모델이지만 특정 입력과 특정 출력을 매핑
- Model 클래스를 사용하면 Sequential과는 달리 여러개의 출력을 가진 모델을 만들 수 있음
# 입력 텐서와 출력 텐서의 리스트로 Model 객체 만들기
from keras import models
layer_outputs = [layer.output for layer in model.layers[:8]] # 상위 8개 층 출력
# 입력에 대해 8개 층의 출력을 반환하는 모델 생성
activation_model = models.Model(inputs = model.input, outputs=layer_outputs)입력 이미지 주입시, 위 모델은 원본 모델의 활성화 값을 반환한다. ( 이 책에서 처음 다루는 다중 출력 모델로, 하나의 입력과 층의 활성화마다 하나씩 총 8개의 출력을 가진다. )
# 예측 모드로 모델 실행
activations = activation_model.predict(img_tensor) # 층의 활성화마다 하나씩 8개의 넘파이 배열로 이루어진 리스트 반환
# ex. 고양이 이미지에 대한 1번째 합성곱 층의 활성화 값
first_year_activation = activation[0]
print(first_year_activation.shape)[Out]
(1, 148, 148, 32)=> 32개 채널을 가진 148 x 148 크기의 특성 맵
원본 모델의 첫 번째 층 활성화 중에서 20번째 채널을 그려보자.
# 20번째 채널 시각화
import matplotlib.pyplot as plt
plt.matshow(first_year_activation[0, :, :, 19], camp='viridis')
=> 이 채널은 대각선 edge를 감지하도록 인코딩된 것으로 보인다.
plt.matshow(first_layer_activation[0, :, :, 15], cmap='viridis')
=> 이 채널은 '밝은 녹색 점'을 감지하는 것같아 고양이 눈을 인코딩하기 좋아보인다.
이제 네트워크의 모든 활성화를 시작해보자. 8개 활성화 맵에서 추출한 모든 채널을 그리기 위해 하나의 큰 이미지 텐서에 결과를 나란히 쌓을 것
# 중간 층의 모든 활성화에 있는 채널 시각화하기
layer_names = [ ]
for layer in model.layers[:8]: #층의 이름을 그래프 제목으로 사용
layer_names.append(layer.name)
images_per_row = 16
# 특성맵 그리기
for layer_name, layer_activation in zip(layer_names, activations):
n_features = layer_activation.shape[-1] # 특성 맵에 있는 특성의 수
size = layer_activation.shape[1] # 특성 맵의 크기는 (1, size, size, n_features)
n_cols = n_features // images_per_row # 활성화 채널을 위한 그리드 크기
display_grid = np.zeros((size*n_cols, images_per_row*size))
for col in range(n_cols): # 각 활성화를 하나의 그리드에 채움
for row in range(images_per_row):
channel_image = layer_activation[0, : , : , col*images_per_row+row]
channel_image -= chnnel_image.mean() # 그래프로 나타나기 좋게 특성 처리
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image, 0, 255).astype('uint8')
display_grid[col*size : (col+1)*size, #그리드 출력
row*size : (row+1)*size] = channel_image
scale = 1./size
plt.figure(figsize=(scale*display_grid.shape[1],
scale*display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid, aspect='auto', cmap='viridis')
plt.show()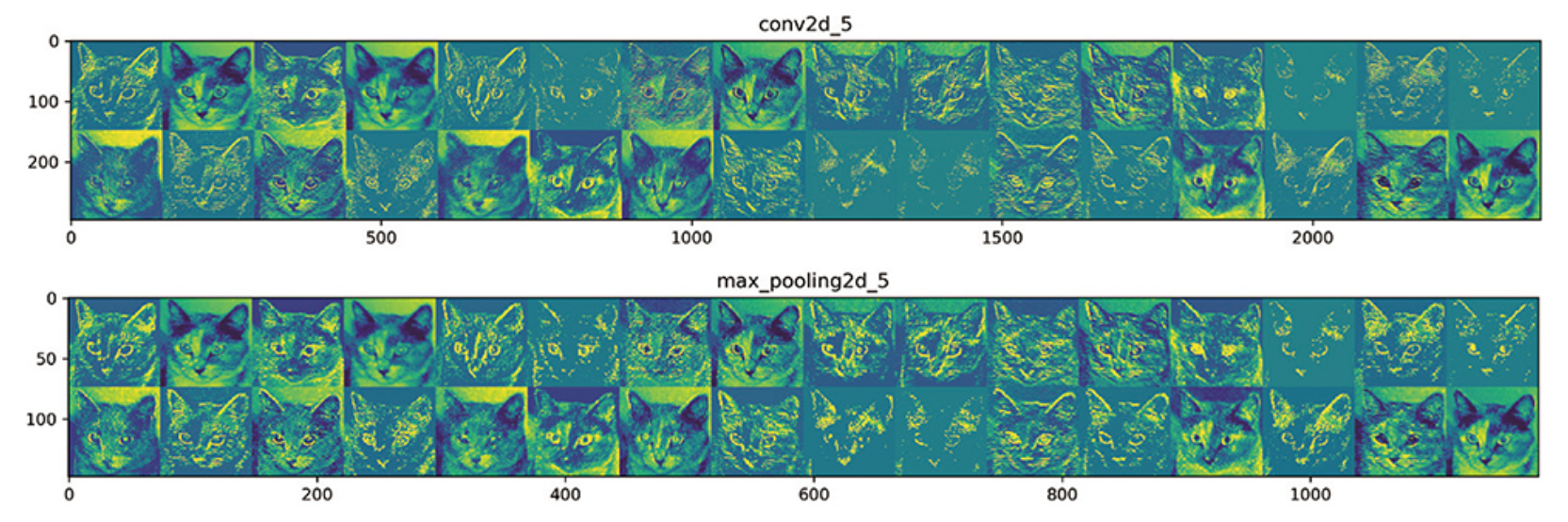
=> 첫 번째 층은 여러 종류의 edge 감지기를 모아 놓은 것 같다. 이 단계의 활성화에서는 초기 사진에 있는 거의 모든 정보가 유지된다.

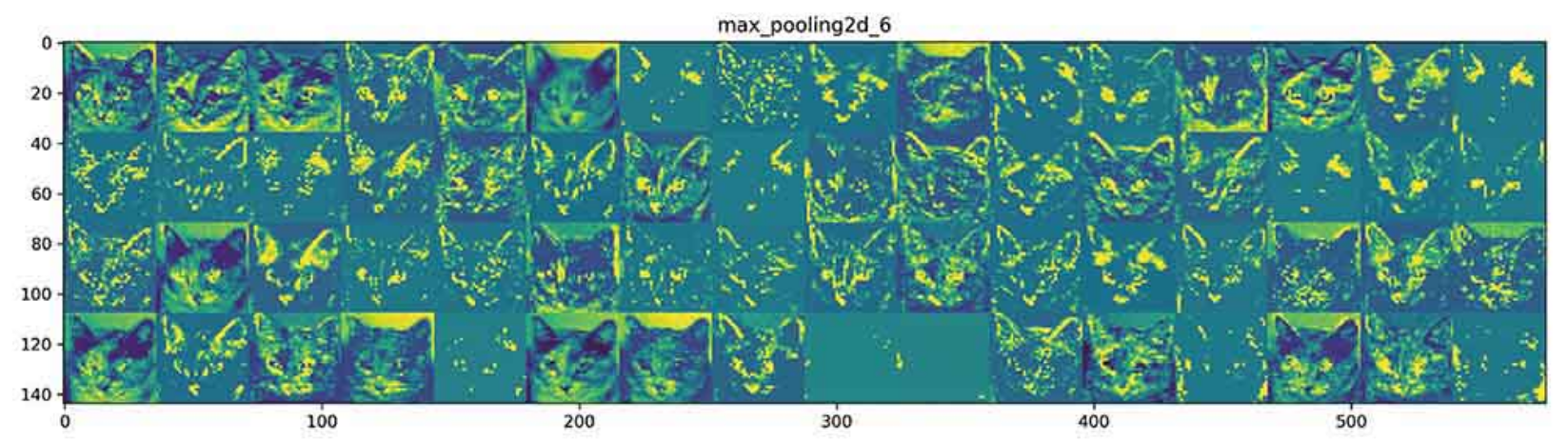
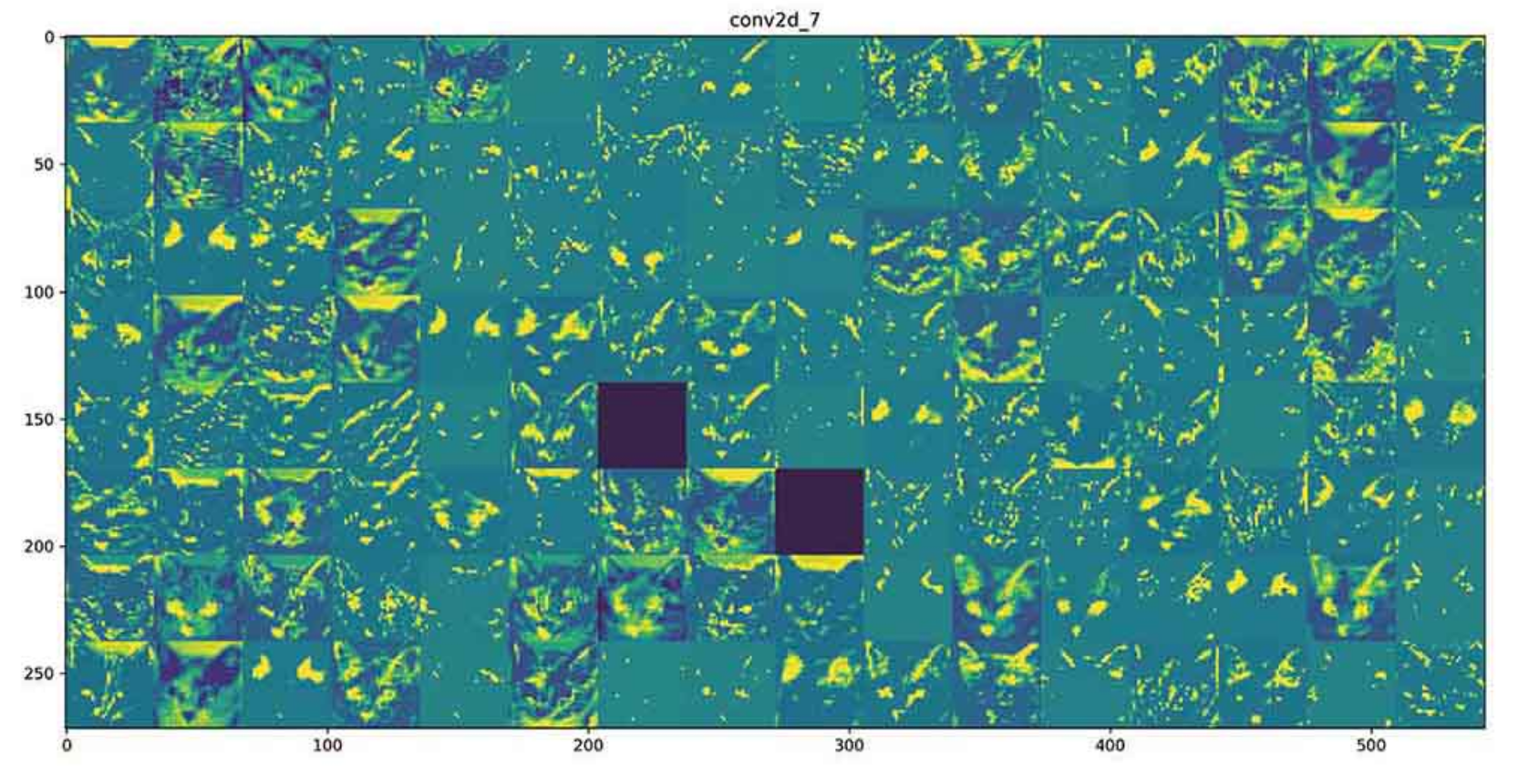
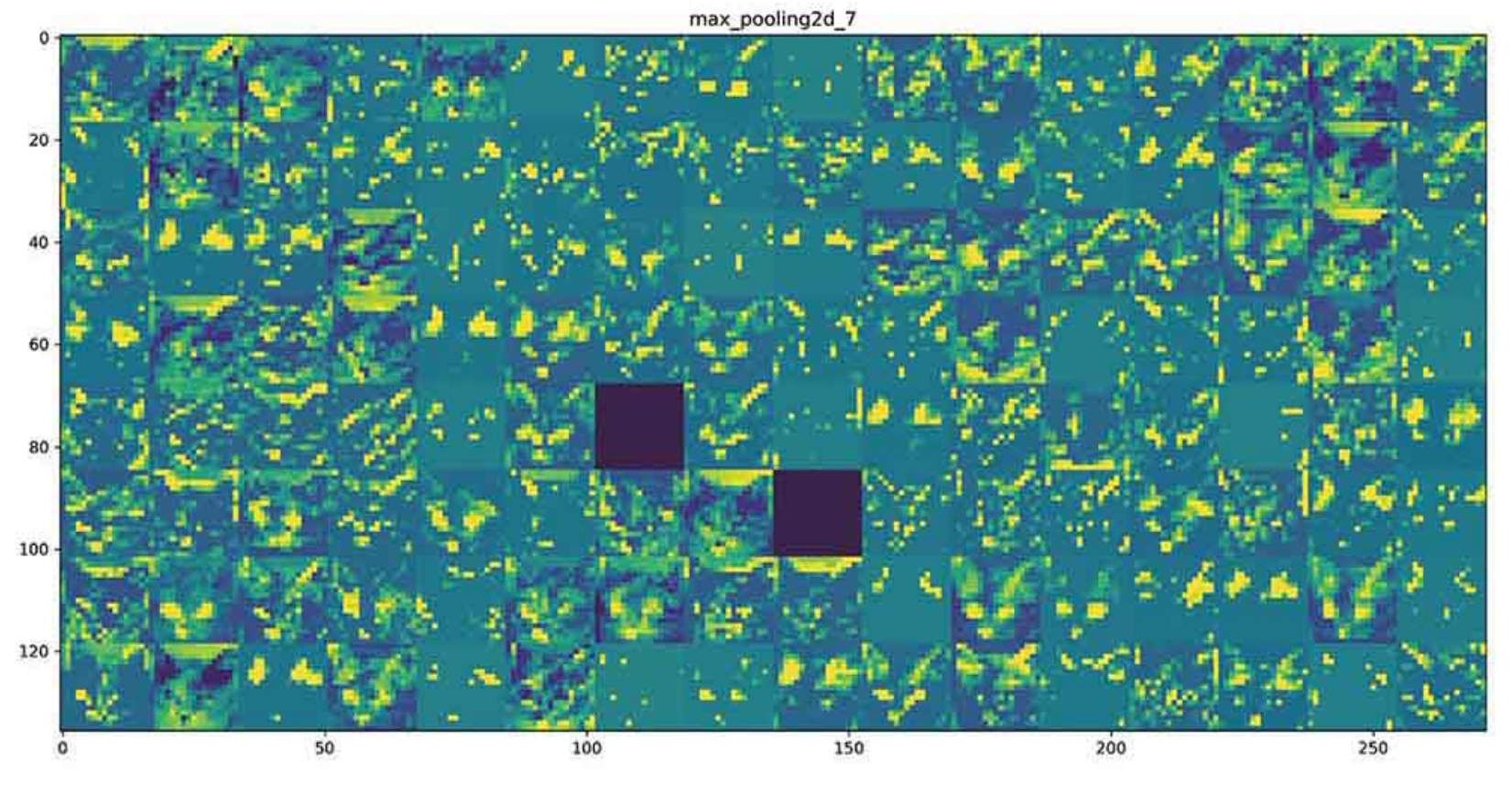

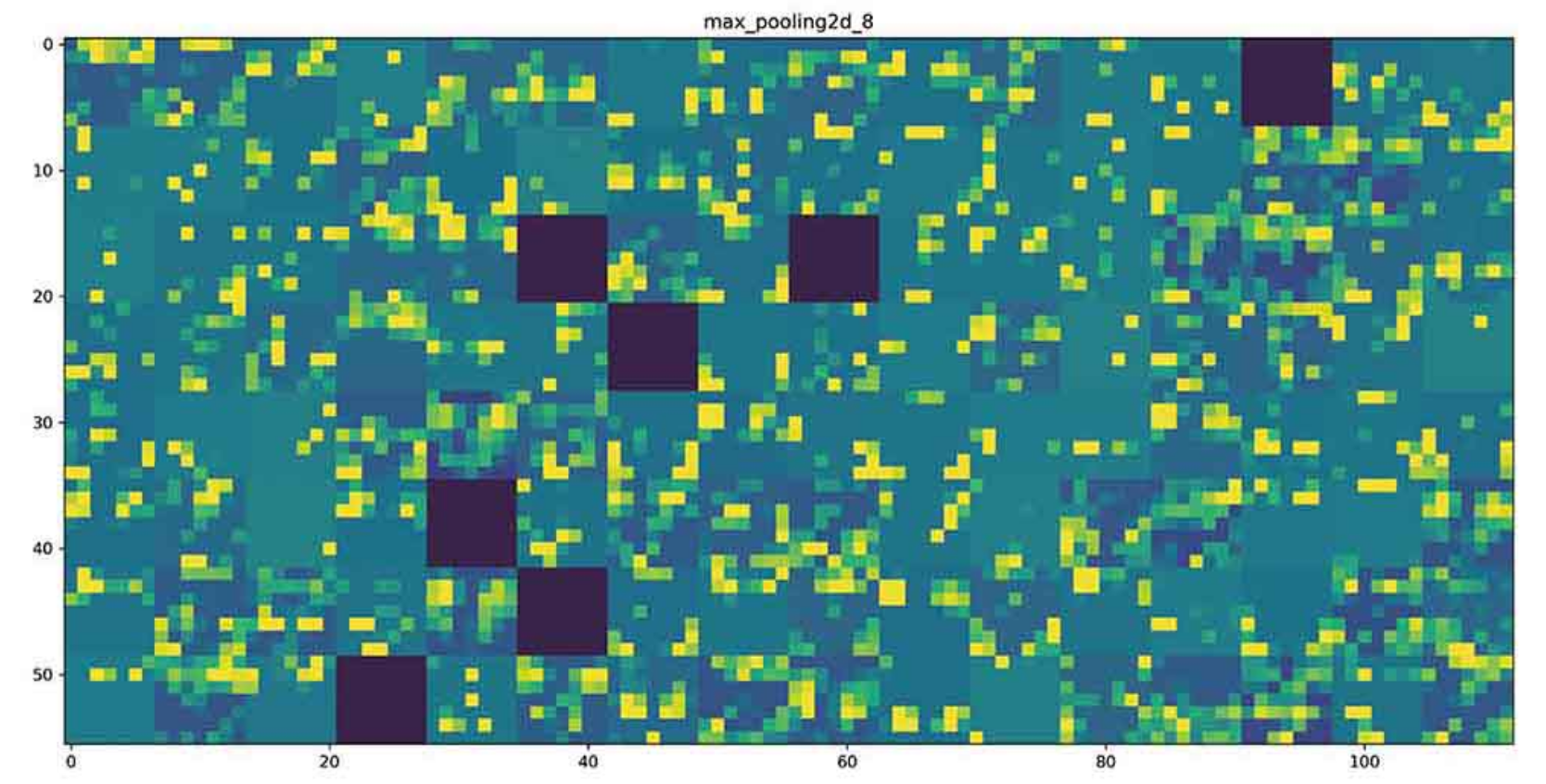
- 상위 층으로 갈 수록 활성화는 점점 더 추상적으로 되고, 시각적으로 이해하기 어려워진다. '고양이 귀'와 '고양이 눈'처럼 고수준 개념을 인코딩하기 시작한다.
- 상위 층의 표현은 이미지의 시각적 콘텐츠에 대한 정보가 점점 줄어들고, 이미지의 클래스에 관한 정보가 점점 증가함
- 심층 신경망은 입력되는 원본 데이터(여기서는 rgb 포맷 사진)에 대한 정보 정제 파이프라인처럼 작동
- 반복적 변환을 통해 관계 없는 정보(ex.이미지의 특정 요소)를 걸러내고, 유용한 정보는 강조하고 개선됨(여기서는 이미지의 클래스)
- 사람과 동물이 세상을 인지하는 방식과 비슷하다. 사람은 몇 초동안 한 장면을 보고난 후, 그 안에 있었던 추상적 물체(자전거,나무)를 기억할 수 있다. 구체적 모양은 기억하지 못함
- 이렇게 기억을 더듬어 보았더라도 비슷하게 그리기 어려우며, 우리의 뇌는 시각적 입력에서 관련성이 적은 요소를 필터링하여 고수준의 개념으로 변환한다. 이렇듯 추상적으로 학습하기에 자세히 기억하기 어려움
'데이터 분석 > 케라스 창시자에게 배우는 딥러닝' 카테고리의 다른 글
| [5] 케라스 창시자에게 배우는 딥러닝 - 5. 컴퓨터 비전을 위한 딥러닝( 합성곱 신경망 소개, MaxPooling, 고양이vs강아지 분류 예제, 데이터 증식) (0) | 2022.08.16 |
|---|---|
| [4] 케라스 창시자에게 배우는 딥러닝 - 4. (머신러닝) 분류, 특성 공학, 특성 학습, 과/소적합, 해결법(가중치 규제,드롭아웃 추가..) (1) | 2022.08.11 |
| [3,실습] 케라스 창시자에게 배우는 딥러닝 - 신경망 시작하기 (분류/회귀 문제 풀어보기 (1) | 2022.08.09 |
| [3] 케라스 창시자에게 배우는 딥러닝 - 신경망 시작하기(분류/예측 예제 풀어보기) (0) | 2022.08.08 |
| [2] 케라스 창시자에게 배우는 딥러닝 - 신경망의 수학적 구성 요소 (1) | 2022.08.08 |



