
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 데이터 증식
- 스태킹 앙상블
- 그로스 해킹
- pmdarima
- 리프 중심 트리 분할
- sql
- lightgbm
- ImageDateGenerator
- DENSE_RANK()
- splitlines
- 데이터 핸들링
- 3기가 마지막이라니..!
- 로그 변환
- 그로스 마케팅
- 캐글 신용카드 사기 검출
- WITH ROLLUP
- 그룹 연산
- 캐글 산탄데르 고객 만족 예측
- 마케팅 보다는 취준 강연 같다(?)
- python
- WITH CUBE
- tableau
- 인프런
- Growth hacking
- 데이터 정합성
- XGBoost
- ARIMA
- 컨브넷
- 분석 패널
- 부트 스트래핑
Archives
- Today
- Total
LITTLE BY LITTLE
[4] 파이썬 머신러닝 완벽가이드 - 판다스(데이터 핸들링) 마무리, 사이킷런 모듈 연습 마무리(Stratified K fold, GridSearchCV) 본문
데이터 분석/파이썬 머신러닝 완벽가이드
[4] 파이썬 머신러닝 완벽가이드 - 판다스(데이터 핸들링) 마무리, 사이킷런 모듈 연습 마무리(Stratified K fold, GridSearchCV)
위나 2022. 8. 6. 16:48*목차
- 파이썬 기반의 머신러닝과 생태계 이해
- 머신러닝의 개념
- 주요 패키지
- 넘파이
- 판다스 (데이터 핸들링) (39p)
- 정리
- 사이킷런으로 시작하는 머신러닝(87p)
- 사이킷런 소개
- 첫번째 머신러닝 만들어보기 - 붓꽃 품종 예측
- 사이킷런 기반 프레임워크 익히기 ( fit(), predict() ..)
- Model selection 모듈 소개 (교차검증, GridSerachCV..)
- 데이터 전처리
- 사이킷런으로 수행하는 타이타닉 생존자 예측
- 정리
더보기
닫기
- 평가
- 정확도
- 오차 행렬
- 정밀도와 재현율
- F1스코어
- ROC 곡선과 AUC
- 피마 인디언 당뇨병 예측
- 정리
- 분류
- 분류의 개요
- 결정 트리
- 앙상블 학습
- 랜덤 포레스트
- GBM(Gradient Boosting Machine)
- XGBoost(eXtra Gradient Boost)
- LightGBM
- 분류 실습 - 캐글 산탄데르 고객 만족 예측
- 분류 실습 - 캐글 신용카드 사기 검출
- 스태킹 앙상블
- 정리
- 회귀
- 회귀 소개
- 단순 선형 회귀를 통한 회귀 이해
- 비용 최소화하기 - 경사 하강법 (Gradient Descent) 소개
- 사이킷런 Linear Regression을 이용한 보스턴 주택 가격 예측
- 다항 회귀와 과(대)적합/과소적합 이해
- 규제 선형 모델 - 릿지, 라쏘, 엘라스틱 넷
- 로지스틱 회귀
- 회귀 트리
- 회귀 실습 - 자전거 대여 수요 예측
- 회귀 실습 - 캐글 주택 가격 : 고급 회귀 기법
- 정리
- 차원 축소
- 차원 축소의 개요
- PCA (Principal Component Anlysis)
- LDA (Linear Discriminant Anlysis)
- SVD (Singular Value Decomposition)
- NMF (Non-Negative Matrix Factorization)
- 정리
- 군집화
- K-평균 알고리즘 이해
- 군집 평가
- 평균 이동 (Mean shift)
- GMM(Gaussian Mixture Model)
- DBSCAN
- 군집화 실습 - 고객 세그먼테이션
- 정리
- 텍스트 분석
- 텍스트 분석 이해
- 텍스트 사전 준비 작업(텍스트 전처리) - 텍스트 정규화
- Bag of Words - BOW
- 텍스트 분류 실습 - 20 뉴스그룹 분류
- 감성 분석
- 토픽 모델링 - 20 뉴스그룹
- 문서 군집화 소개와 실습 (Opinion Review 데이터셋)
- 문서 유사도
- 한글 텍스트 처리 - 네이버 영화 평점 감성 분석
- 텍스트 분석 실습 - 캐글 mercari Price Suggestion Challenge
- 정리
- 추천 시스템
- 추천 시스템의 개요와 배경
- 콘텐츠 기반 필터링 추천 시스템
- 최근접 이웃 협업 필터링
- 잠재요인 협업 필터링
- 콘텐츠 기반 필터링 실습 - TMDV 5000 영화 데이터셋
- 아이템 기반 최근접 이웃 협업 필터링 실습
- 행렬 분해를 이용한 잠재요인 협업 필터링 실습
- 파이썬 추천 시스템 패키지 - Surprise
- 정리
판다스(데이터 핸들링) 마무리¶
불리언 인덱싱¶
- loc, iloc처럼 명확히 인덱싱을 지정하는 경우보다는 불리언 인덱싱에 의해 데이터를 가져오는 경우가 더 많음
- 단, loc[]과 사용할 수 있고, iloc[]과는 사용할 수 없다. iloc은 정수형값만 지원하기 때문
- [] 내에 불리언 조건을 입력하면 불리언 인덱싱으로 자동으로 결과를 찾아줌
In [2]:
import numpy as np
import pandas as pd
In [4]:
titanic_df = pd.read_csv('titanic_train.csv')
titanic_boolean = titanic_df[titanic_df['Age']>60]
print(type(titanic_boolean))
titanic_boolean
<class 'pandas.core.frame.DataFrame'>
Out[4]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 33 | 34 | 0 | 2 | Wheadon, Mr. Edward H | male | 66.0 | 0 | 0 | C.A. 24579 | 10.5000 | NaN | S |
| 54 | 55 | 0 | 1 | Ostby, Mr. Engelhart Cornelius | male | 65.0 | 0 | 1 | 113509 | 61.9792 | B30 | C |
| 96 | 97 | 0 | 1 | Goldschmidt, Mr. George B | male | 71.0 | 0 | 0 | PC 17754 | 34.6542 | A5 | C |
| 116 | 117 | 0 | 3 | Connors, Mr. Patrick | male | 70.5 | 0 | 0 | 370369 | 7.7500 | NaN | Q |
| 170 | 171 | 0 | 1 | Van der hoef, Mr. Wyckoff | male | 61.0 | 0 | 0 | 111240 | 33.5000 | B19 | S |
| 252 | 253 | 0 | 1 | Stead, Mr. William Thomas | male | 62.0 | 0 | 0 | 113514 | 26.5500 | C87 | S |
| 275 | 276 | 1 | 1 | Andrews, Miss. Kornelia Theodosia | female | 63.0 | 1 | 0 | 13502 | 77.9583 | D7 | S |
| 280 | 281 | 0 | 3 | Duane, Mr. Frank | male | 65.0 | 0 | 0 | 336439 | 7.7500 | NaN | Q |
| 326 | 327 | 0 | 3 | Nysveen, Mr. Johan Hansen | male | 61.0 | 0 | 0 | 345364 | 6.2375 | NaN | S |
| 438 | 439 | 0 | 1 | Fortune, Mr. Mark | male | 64.0 | 1 | 4 | 19950 | 263.0000 | C23 C25 C27 | S |
| 456 | 457 | 0 | 1 | Millet, Mr. Francis Davis | male | 65.0 | 0 | 0 | 13509 | 26.5500 | E38 | S |
| 483 | 484 | 1 | 3 | Turkula, Mrs. (Hedwig) | female | 63.0 | 0 | 0 | 4134 | 9.5875 | NaN | S |
| 493 | 494 | 0 | 1 | Artagaveytia, Mr. Ramon | male | 71.0 | 0 | 0 | PC 17609 | 49.5042 | NaN | C |
| 545 | 546 | 0 | 1 | Nicholson, Mr. Arthur Ernest | male | 64.0 | 0 | 0 | 693 | 26.0000 | NaN | S |
| 555 | 556 | 0 | 1 | Wright, Mr. George | male | 62.0 | 0 | 0 | 113807 | 26.5500 | NaN | S |
| 570 | 571 | 1 | 2 | Harris, Mr. George | male | 62.0 | 0 | 0 | S.W./PP 752 | 10.5000 | NaN | S |
| 625 | 626 | 0 | 1 | Sutton, Mr. Frederick | male | 61.0 | 0 | 0 | 36963 | 32.3208 | D50 | S |
| 630 | 631 | 1 | 1 | Barkworth, Mr. Algernon Henry Wilson | male | 80.0 | 0 | 0 | 27042 | 30.0000 | A23 | S |
| 672 | 673 | 0 | 2 | Mitchell, Mr. Henry Michael | male | 70.0 | 0 | 0 | C.A. 24580 | 10.5000 | NaN | S |
| 745 | 746 | 0 | 1 | Crosby, Capt. Edward Gifford | male | 70.0 | 1 | 1 | WE/P 5735 | 71.0000 | B22 | S |
| 829 | 830 | 1 | 1 | Stone, Mrs. George Nelson (Martha Evelyn) | female | 62.0 | 0 | 0 | 113572 | 80.0000 | B28 | NaN |
| 851 | 852 | 0 | 3 | Svensson, Mr. Johan | male | 74.0 | 0 | 0 | 347060 | 7.7750 | NaN | S |
- titanic_boolean 객체의 타입은 dataframe이다. 따라서 원하는 칼럼명만 별도로 추출도 가능
In [8]:
titanic_df[titanic_df['Age']>60][['Name','Age']].head(3) # 60세 이상인 데이터의 이름과 나이만 3개 추출
Out[8]:
| Name | Age | |
|---|---|---|
| 33 | Wheadon, Mr. Edward H | 66.0 |
| 54 | Ostby, Mr. Engelhart Cornelius | 65.0 |
| 96 | Goldschmidt, Mr. George B | 71.0 |
In [16]:
titanic_df.loc[titanic_df['Age']>60,['Name','Age']].head(3)
# 위와 같은 결과 출력(loc을 붙여도되고 안붙여도되고)
Out[16]:
| Name | Age | |
|---|---|---|
| 33 | Wheadon, Mr. Edward H | 66.0 |
| 54 | Ostby, Mr. Engelhart Cornelius | 65.0 |
| 96 | Goldschmidt, Mr. George B | 71.0 |
In [25]:
titanic_df[ (titanic_df['Age']>60) & (titanic_df['Pclass']==1) & (titanic_df['Sex']=='female')].head(3)
# 60세 이상이고, pclass가 1이고, sex가 female인 데이터만 추출
Out[25]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 54 | 55 | 0 | 1 | Ostby, Mr. Engelhart Cornelius | female | 65.0 | 0 | 1 | 113509 | 61.9792 | B30 | C |
| 96 | 97 | 0 | 1 | Goldschmidt, Mr. George B | female | 71.0 | 0 | 0 | PC 17754 | 34.6542 | A5 | C |
| 170 | 171 | 0 | 1 | Van der hoef, Mr. Wyckoff | female | 61.0 | 0 | 0 | 111240 | 33.5000 | B19 | S |
In [23]:
# 조건 할당 후 불리언 인덱싱 해도 된다.
cond1 = titanic_df['Age']>60
cond2 = titanic_df['Pclass']==1
cond3 = titanic_df['Sex']=='female'
titanic_df[cond1 & cond2 & cond3 ].head(3)
Out[23]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 54 | 55 | 0 | 1 | Ostby, Mr. Engelhart Cornelius | female | 65.0 | 0 | 1 | 113509 | 61.9792 | B30 | C |
| 96 | 97 | 0 | 1 | Goldschmidt, Mr. George B | female | 71.0 | 0 | 0 | PC 17754 | 34.6542 | A5 | C |
| 170 | 171 | 0 | 1 | Van der hoef, Mr. Wyckoff | female | 61.0 | 0 | 0 | 111240 | 33.5000 | B19 | S |
정렬, Aggregation 함수, Group By 함수¶
dataframe과 series의 정렬 - sort_values()¶
- SQL의 order by 와 유사함
- 주요 입력 파라미터는 by , ascending, inplace
In [26]:
titanic_sorted = titanic_df.sort_values(by=['Name'])
titanic_sorted.head(3)
Out[26]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 845 | 846 | 0 | 3 | Abbing, Mr. Anthony | female | 42.0 | 0 | 0 | C.A. 5547 | 7.55 | NaN | S |
| 746 | 747 | 0 | 3 | Abbott, Mr. Rossmore Edward | female | 16.0 | 1 | 1 | C.A. 2673 | 20.25 | NaN | S |
| 279 | 280 | 1 | 3 | Abbott, Mrs. Stanton (Rosa Hunt) | female | 35.0 | 1 | 1 | C.A. 2673 | 20.25 | NaN | S |
In [27]:
titanic_sorted = titanic_df.sort_values(by=['Pclass','Name'],ascending=False)
titanic_sorted.head(3)
Out[27]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 868 | 869 | 0 | 3 | van Melkebeke, Mr. Philemon | female | NaN | 0 | 0 | 345777 | 9.5 | NaN | S |
| 153 | 154 | 0 | 3 | van Billiard, Mr. Austin Blyler | female | 40.5 | 0 | 2 | A/5. 851 | 14.5 | NaN | S |
| 282 | 283 | 0 | 3 | de Pelsmaeker, Mr. Alfons | female | 16.0 | 0 | 0 | 345778 | 9.5 | NaN | S |
Aggregation 함수 적용¶
- dataframe에서 min(), max(), sum(), count()와 같은 aggregation 함수의 적용은 SQL의 aggregation과 유사
- 차이점은 dataframe의 경우, dataframe에서 바로 aggregation 호출시, 모든 칼럼에 해당 aggreagation을 적용한다는 차이가 있다.
In [28]:
titanic_df.count()
Out[28]:
PassengerId 891
Survived 891
Pclass 891
Name 891
Sex 891
Age 714
SibSp 891
Parch 891
Ticket 891
Fare 891
Cabin 204
Embarked 889
dtype: int64- 특정 칼럼에 aggregation 함수를 적용하기 위해서는 dataframe에 대상 칼럼들만 추출해 aggregation을 적용하면 된다.
In [29]:
titanic_df[['Age','Fare']].mean()
Out[29]:
Age 29.699118
Fare 32.204208
dtype: float64groupby() 적용¶
- SQL의 groupby와 유사하긴 하나, 다른 점이 있어 주의해야한다.
- dataframe에 groupby() 사용시, 입력 파라미터 by에 칼럼을 입력하면 대상 칼럼으로 groupby 된다.
- dataframe에 groupby()를 호출하면 dataframe GroupBy 라는 다른 형태의 dataframe 반환
In [30]:
titanic_groupby = titanic_df.groupby(by='Pclass')
print(type(titanic_groupby))
<class 'pandas.core.groupby.generic.DataFrameGroupBy'>
- SQL의 gruopby와 다르게, dataframe에 groupby()를 써서 반환된 결과에 aggregation 함수를 호출하면 groupby() 대상 칼럼을 제외한 모든 칼럼에 해당 aagregation 함수 적용 **
In [32]:
titanic_groupby = titanic_df.groupby('Pclass').count()
titanic_groupby
# groupby로 묶은 pclass를 "제외하고" count() (aggregation함수) 적용됨
Out[32]:
| PassengerId | Survived | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pclass | |||||||||||
| 1 | 216 | 216 | 216 | 216 | 186 | 216 | 216 | 216 | 216 | 176 | 214 |
| 2 | 184 | 184 | 184 | 184 | 173 | 184 | 184 | 184 | 184 | 16 | 184 |
| 3 | 491 | 491 | 491 | 491 | 355 | 491 | 491 | 491 | 491 | 12 | 491 |
- 반면에 SQL의 경우, group by 적용시 여러개의 칼럼에 aggregation 함수를 호출하려면 대상 칼럼을 모두 Select 절에 나열해야 한다.
- groupby('Pclass')로 반환된 dataframe groupby 객체에 [['PassengerId','Survived']]로 필터링해서 두 칼럼에만 count() 수행하기
In [33]:
titanic_groupby = titanic_df.groupby('Pclass')[['PassengerId','Survived']].count()
titanic_groupby
Out[33]:
| PassengerId | Survived | |
|---|---|---|
| Pclass | ||
| 1 | 216 | 216 |
| 2 | 184 | 184 |
| 3 | 491 | 491 |
In [34]:
titanic_df.groupby('Pclass')['Age'].agg([max,min])
Out[34]:
| max | min | |
|---|---|---|
| Pclass | ||
| 1 | 80.0 | 0.92 |
| 2 | 70.0 | 0.67 |
| 3 | 74.0 | 0.42 |
- 서로 다른 aggregation 함수를 groupby에서 호출하려면 SQL은 Select max(Age) , sum(SibSp), avg(Fare) from titanic_table group by Pclass와 같이 쉽게 가능하지만
- dataframe groupby에서는 조금 더 복잡하다.
- groupby()는 agg()를 이용해 이 같은 처리가 가능한데, agg() 내에 입력 값으로 딕셔너리 형태로 aggregation이 적용될 칼럼들과 aggregation 함수를 입력함
In [38]:
agg_format = {'Age':'max','SibSp':'sum','Fare':'mean'}
titanic_df.groupby('Pclass').agg(agg_format)
Out[38]:
| Age | SibSp | Fare | |
|---|---|---|---|
| Pclass | |||
| 1 | 80.0 | 90 | 84.154687 |
| 2 | 70.0 | 74 | 20.662183 |
| 3 | 74.0 | 302 | 13.675550 |
결손 데이터 처리하기¶
- isna() - 보통 sum() 추가해서 개수 구함
- fillna()
In [39]:
titanic_df.isna().head(3)
Out[39]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False | False | False | False | False | True | False |
| 1 | False | False | False | False | False | False | False | False | False | False | False | False |
| 2 | False | False | False | False | False | False | False | False | False | False | True | False |
In [40]:
titanic_df.isna().sum()
Out[40]:
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64In [41]:
titanic_df['Cabin'] = titanic_df['Cabin'].fillna('C000')
titanic_df.head(3)
Out[41]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | female | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | C000 | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | C000 | S |
- 주의해야할 점은 1. fillna()로 반환값을 다시 받거나 (ex. titanic_df['Cabin'] = titanic_df['Cabin'].fillna('C000')
- inplace=True 해야지 원본 데이터에 반영
In [49]:
titanic_df['Age'] = titanic_df['Age'].fillna(titanic_df['Age'].mean())
titanic_df['Embarked'] = titanic_df['Embarked'].fillna('S')
titanic_df.isna().sum()
Out[49]:
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int64apply lambda 식으로 데이터 가공¶
- apply 함수에 lambda 식을 결합해 dataframe이나 series의 레코드별로 데이터 가공 가능
- lambda 식을 이용할 때, 여러개의 인자를 사용해야할 경우 map() 함수를 결합해서 사용함
In [51]:
# lambda 함수 적용 전
def get_square(a): # def로 합수명과 () 입력 인자 먼저 선언
return a**2 # 인자 가공(a**2), 결괏값을 return으로 반환
print('3의 제곱은:',get_square(3))
3의 제곱은: 9
- # 함수명 = lambda 인자 : 인자 가공 식
In [54]:
# lambda 함수 적용
lambda_square = lambda x : x **2
print('3의 제곱은:',lambda_square(3))
3의 제곱은: 9
In [56]:
a = [1,2,3]
squares = map(lambda x : x**2,a) # 여러개의 인자는 map함수 이용
list(squares)
Out[56]:
[1, 4, 9]In [57]:
# lambda 식 적용해서 데이터 가공해보기
titanic_df['Name_len'] = titanic_df['Name'].apply(lambda x : len(x))
titanic_df[['Name','Name_len']].head(3)
Out[57]:
| Name | Name_len | |
|---|---|---|
| 0 | Braund, Mr. Owen Harris | 23 |
| 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 51 |
| 2 | Heikkinen, Miss. Laina | 22 |
- lambda 식에서 if else 절을 사용해 조금 더 복잡한 가공을 해보자.
- 15세 미만이면 child, 그렇지 않으면 adault로 구분하는 새로운 칼럼 child_adault를 만들어보자.
In [58]:
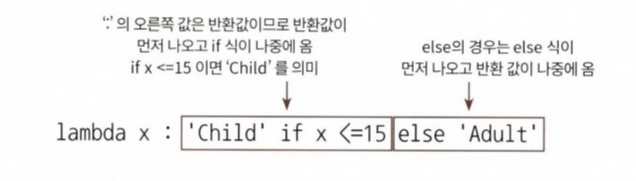
titanic_df['Child_Adult'] = titanic_df['Age'].apply(lambda x : 'Child' if x <=15 else 'Adult')
titanic_df[['Age','Child_Adult']].head(8)
Out[58]:
| Age | Child_Adult | |
|---|---|---|
| 0 | 22.000000 | Adult |
| 1 | 38.000000 | Adult |
| 2 | 26.000000 | Adult |
| 3 | 35.000000 | Adult |
| 4 | 35.000000 | Adult |
| 5 | 29.699118 | Adult |
| 6 | 54.000000 | Adult |
| 7 | 2.000000 | Child |
- lambda식은 if else를 지원하는데, 주의해야할 점은 if 절의 경우, if식보다 반환 값을 먼저 기술해야한다. 이는 lambda 식에서 콜론 기호 뒤에 반환값이 있어야 하기 때문
- 위에서 사용한 람다함수를 보면 lambda x : 'child' 를 적은 다음 if절이 온다.
- 주의! else if는 지원하지 않는다.
- 따라서 else 여러개 쓰고 싶으면 else절을 괄호 내에서 괄호로 내포해 다시 if else를 적용해야함
- apply( lambda x : 'Child' if x<=15 else ('Adult' if x<=60 else 'Elderly'))
In [62]:
titanic_df['Age_cat'] = titanic_df['Age'].apply(
lambda x : 'Child' if x<=15 else ('Adult' if x<=60 else 'Elderly'))
titanic_df['Age_cat'].value_counts()
Out[62]:
Adult 786
Child 83
Elderly 22
Name: Age_cat, dtype: int64- else if가 많이 나와야 하는 경우나 switch case 문의 경우, 계속 else를 내포해서 쓰기에는 부담스럽다. 따라서 별도의 함수를 만드는게 나을 수 있음
- 나이에 대해 더 세분화된 분류를 해보자. 5세 이하는 Baby, 12세 이하는 Child, 18세 이하는 Teenage, 25세 이하는 Student, 35세 이하는 Young Adult, 60세 이하는 Adult, 그 이상은 Elderly
In [68]:
def get_category(age):
cat = ''
if age <=5 : cat = 'Baby'
elif age <=12 : cat = 'Child'
elif age <=18 : cat = 'Teenager'
elif age <=25 : cat = 'Student'
elif age <=35 : cat = 'Young Adult'
elif age <=60 : cat = 'Adult'
else : cat = 'Elderly'
return cat
- # lambda 식에 위에서 생성한 get_cateogry() 함수를 반환값으로 지정하자.
- titanic_df['Age'].apply(lambda x : get_category(x))
In [69]:
titanic_df['Age_cat'] = titanic_df['Age'].apply(lambda x : get_category(x))
titanic_df[['Age','Age_cat']].head()
Out[69]:
| Age | Age_cat | |
|---|---|---|
| 0 | 22.0 | Student |
| 1 | 38.0 | Adult |
| 2 | 26.0 | Young Adult |
| 3 | 35.0 | Young Adult |
| 4 | 35.0 | Young Adult |
2-4. 사이킷런으로 시작하는 머신러닝 - Model Selection 모듈 소개 (Stratified K 폴드 ~)(106p)¶
- statified k 폴드는 불균형한 분포도를 가진 레이블(결정 클래스) 데이터 집합을 위한 k 폴드 방식.
- ex. 대출 사기 데이터를 예측한다고 가정해보았을 때, 데이터셋은 1억건, 수십개의 피처와 대출 사기 여부를 뜻하는 레이블(대출 사기:1, 정상 대출:0)으로 구성돼있음. 대부분의 데이터는 정상 대출일 것이고, 전체의 0.0001% 의 아주 작은 확률로 대출 사기 레이블이 존재 -> 이렇게 작으면 k폴드로 랜덤하게 고르더라도 레이블 값인 0과1의 비율을 제대로 반영하지 X
- 이러한 경우 Stratified k폴드는 레이블 데이터 집합이 원본 데이터 집합의 레이블 분포를 학습 및 테스트 데이터셋에 제대로 분배하지 못하는 경우의 문제를 해결해준다.
- 원본 데이터의 레이블 분포 고려 후, 이 분포와 동일하게 test and train 데이터 분배해줌
- ex. 대출 사기 데이터를 예측한다고 가정해보았을 때, 데이터셋은 1억건, 수십개의 피처와 대출 사기 여부를 뜻하는 레이블(대출 사기:1, 정상 대출:0)으로 구성돼있음. 대부분의 데이터는 정상 대출일 것이고, 전체의 0.0001% 의 아주 작은 확률로 대출 사기 레이블이 존재 -> 이렇게 작으면 k폴드로 랜덤하게 고르더라도 레이블 값인 0과1의 비율을 제대로 반영하지 X
In [79]:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data,columns=iris.feature_names)
iris_df['label'] = iris.target
iris_df['label'].value_counts()
Out[79]:
0 50
1 50
2 50
Name: label, dtype: int64- 레이블 값은 0,1,2 값 모두 50개로 동일하다. 불균형 데이터를 생성해서 stratified k fold를 실습해보자.
- 복습
- k-fold 교차검증
- KFold(n_splits=)
- kfold.split()
In [132]:
# 저번에 배운 k fold 복습
iris = load_iris()
features = iris.data
label = iris.target
dt_clf = DecisionTreeClassifier(random_state=156)
In [133]:
for train_index, test_index in kfold.split(features):
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = label [train_index], label[test_index]
# 학습 및 예측
dt_clf.fit(X_train,y_train)
pred = dt_clf.predict(X_test)
n_iter +=1
In [134]:
kfold = KFold(n_splits=3)
n_iter = 0
for train_index, test_index in kfold.split(iris_df):
n_iter +=1
label_train = iris_df['label'].iloc[train_index]
label_test = iris_df['label'].iloc[test_index]
print('## 교차 검증: {0}'.format(n_iter))
print('학습 레이블 데이터 분포.\n', label_train.value_counts())
print('검증 레이블 데이터 분포:\n', label_test.value_counts())
iris_df['label'].value_counts()
## 교차 검증: 1
학습 레이블 데이터 분포.
1 50
2 50
Name: label, dtype: int64
검증 레이블 데이터 분포:
0 50
Name: label, dtype: int64
## 교차 검증: 2
학습 레이블 데이터 분포.
0 50
2 50
Name: label, dtype: int64
검증 레이블 데이터 분포:
1 50
Name: label, dtype: int64
## 교차 검증: 3
학습 레이블 데이터 분포.
0 50
1 50
Name: label, dtype: int64
검증 레이블 데이터 분포:
2 50
Name: label, dtype: int64
- 교차 검증시 마다 3개의 폴드 세트로 만들어지는 학습 레이블과 검증 레이블이 완전히 다른 값으로 추출
- 문제점
- 첫번째 교차 검증에서는 학습 레이블의1,2값이 각각 50개 추출
- 검증 레이블의 0값이 50개 추출
- 학습 레이블은 1,2밖에 없으므로 0의 경우는 학습하지 못함
- 반대로 검증 레이블은 0밖에 없으므로 학습 모델은 0을 예측하지 못함
- 따라서 이런 유형으로 교차 검증 데이터셋 분할시, 검증 정확 예측도는 0이 될 수 밖에 없다
- Stratified KFold는 이렇게 KFold로 분할된 레이블 데이터셋이 전체 레이블 값의 분포도를 반영하지 못하는 문제를 해결해줌
- Stratified KFold와 그냥 KFold의 차이는 split() 메소드에 인자로 피처 데이텃세 뿐만 아니라, 레이블 데이터셋도 반드시 필요하다는 점이다.
In [135]:
from sklearn.model_selection import StratifiedKFold
# 폴드 세트는 3개로 설정하자.
# 위 kfold와 같음, 차이점은
skf = StratifiedKFold(n_splits=3)
n_iter=0
kfold = KFold(n_splits=3)
n_iter=0
#이전과 다른 부분: kfold_split(iris_df) -> skf.split(iris_df,iris_df['label']):split괄호 안에 label도있음
for train_index, test_index in skf.split(iris_df, iris_df['label']):
n_iter +=1
label_train = iris_df['label'].iloc[train_index]
label_test = iris_df['label'].iloc[test_index]
print('## 교차 검증: {0}'.format(n_iter))
print('학습 레이블 데이터 분포:\n',label_train.value_counts())
print('검증 레이블 데이터 분포:\n',label_test.value_counts())
## 교차 검증: 1
학습 레이블 데이터 분포:
2 34
0 33
1 33
Name: label, dtype: int64
검증 레이블 데이터 분포:
0 17
1 17
2 16
Name: label, dtype: int64
## 교차 검증: 2
학습 레이블 데이터 분포:
1 34
0 33
2 33
Name: label, dtype: int64
검증 레이블 데이터 분포:
0 17
2 17
1 16
Name: label, dtype: int64
## 교차 검증: 3
학습 레이블 데이터 분포:
0 34
1 33
2 33
Name: label, dtype: int64
검증 레이블 데이터 분포:
1 17
2 17
0 16
Name: label, dtype: int64
- 아까와 다른 결과! 문제 해결됨
- 폴드 세트로 만들어지는 학습 레이블과 검증 레이블이 완전히 다른 값으로 추출됨
- (변화) 학습 레이블1,2의값=50개, 검증레이블0의값=50개
- => 학습 레이블 0,1,2값이모두 33개, 검증레이블 역시 0,1,2값이 모두 17개
- skfold = StratifiedKFold(n_splits=)
- skfold.split(df, df['label'])
In [148]:
# Stratified KFold로 데이터를 분리해보자.
dt_clf = DecisionTreeClassifier(random_state=156)
skfold = StratifiedKFold(n_splits=3)
n_iter = 0
cv_accuracy=[]
# StratifiedKFold의 split() 호출시 반드시 레이블 데이터셋도 입력!
for train_index, test_index in skfold.split(features,label):
# split()으로 반환된 인덱스를 이용해 학습용, 검증용 데이터 추출
X_train, X_test =features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
# label_train = iris_df['label'].iloc[train_index]
# label_test = iris_df['label'].iloc[test_index]
#학습 및 예측
dt_clf.fit(X_train,y_train)
pred = dt_clf.predict(X_test)
# 반복시마다 accuracy 측정
n_iter +=1
accuracy = np.round(accuracy_score(y_test,pred),4)
train_size = X_train.shape[0]
test_size = X_test.shape[0]
print('\n#{0} 교차 검증 정확도 :{1}, 학습 데이터 크기: {2}, 검증 데이터 크기:{3}'.format(
n_iter, accuracy, train_size, test_size))
print('#{0} 검증 세트 인덱스:{1}'.format(n_iter, test_index))
cv_accuracy.append(accuracy)
# 교차 검증별 정확도 및 평균 정확도 계산
print('\n## 교차 검증별 정확도:', np.round(cv_accuracy,4))
print('## 평균 검증 정확도:', np.mean(cv_accuracy))
#1 교차 검증 정확도 :0.98, 학습 데이터 크기: 100, 검증 데이터 크기:50
#1 검증 세트 인덱스:[ 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 83 84
85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 133 134 135
136 137 138 139 140 141 142 143 144 145 146 147 148 149]
## 교차 검증별 정확도: [0.98]
## 평균 검증 정확도: 0.98
- 불균형 데이터에는 반드시 strafitied kfold로 교차 검증하자.
- 일반적으로 분류(Classification)에서의 교차 검증은 stratified kfold로 분할되어야한다.
- 회귀에서는 지원되지 않음! 그 이유는 회귀의 결정값은 이산 값 형태의 레이블이 아니라, 연속된 숫자값이기 때문에 결정값별로 분포를 정하는 의미가 없기 때문
교차 검증을 간편하게 해주는 cross_val_score()¶
- kfold로 학습,예측 하는 코드를 보면
- 폴드 세트 설정 (skfold = StratifiedFold(n_splits=))
- for 루프에서 반복으로 학습 및 테스트 데이터의 인덱스 추출
- 반복적으로 학습,예측 수행 후 예측 성능 반환
=> 모든 과정을 한꺼번에 수행해주는 API인 cross_val_score()
- cross_val_score(estimator , X, y=None, scoring = None, cv = None, n_jobs = 1, verbose = 0, fit_params = None, pre_dispatch = '2*n_jobs')
- 이중 주요 파라미터는 estimator, X, y, scoring, cv 이다.
- estimator은 분류 알고리즘 클래스인 Classifier 혹은 회귀 알고리즘 클래스인 Regressor의미
- X는 피처 데이터 셋, y는 레이블 데이터 셋, scoring은 예측 성능 평가 지표, cv는 교차 검증 폴드 수
- 반환 값은 scroing 파라미터로 지정된 성능 지표 측정값을 배열 형태로 반환
- classifier가 입력되면, Stratified K Fold 방식으로 분할해줌 (회귀는 k fold)
In [149]:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score, cross_validate
from sklearn.datasets import load_iris
In [151]:
iris_data = load_iris()
dt_clf = DecisionTreeClassifier(random_state=156)
data = iris_data.data
label = iris_data.target
# 성능 지표는 정확도(accuracy), 교차 검증 세트는 3개
scores = cross_val_score(dt_clf, data, label, scoring = 'accuracy', cv=3)
print('교차 검증별 정확도:', np.round(scores,4))
print('평균 검증 정확도:', np.round(np.mean(scores),4))
교차 검증별 정확도: [0.98 0.94 0.98]
평균 검증 정확도: 0.9667
- cv로 지정된 횟수만큼 (3회) scring 파라미터로 지정된 평가지표로 평가 결괏값을 배열로 반환
- 그리고 일반적으로 이를 평균해 평가 수치로 사용
- 내부에서 estimator을 학습(fit), 예측(predict), 평가(evaluation) 시켜주므로 간단하게 교차검증 가능
- 비슷한 API로 cross_validate()가 있다. 여러개의 평가 지표를 반환하고자할 때 쓰이고, 학습 데이터에 대한 성능 평가 지표와 수행 시간도 같이 제공
GridSearchCV - 교차 검증과 최적 하이퍼 파라미터 튜닝을 한번에¶
- 하이퍼 파라미터는 머신러닝 알고리즘을 구성하는 주요 구성 요소로, 이 값을 조정해 알고리즘의 예측 성능 개선 가능
- GridSearchCV API를 이용해 분류나 회귀와 같은 알고리즘에 사용되는 하이퍼 파라미터를 순차적으로 입려갛면서 편하게 최적의 파라미터 도출 가능
- (Grid 이름이 격자 .. 인 이유는 촘촘하게 파라미터를 입력하면서 테스트하는 방식이기 때문)
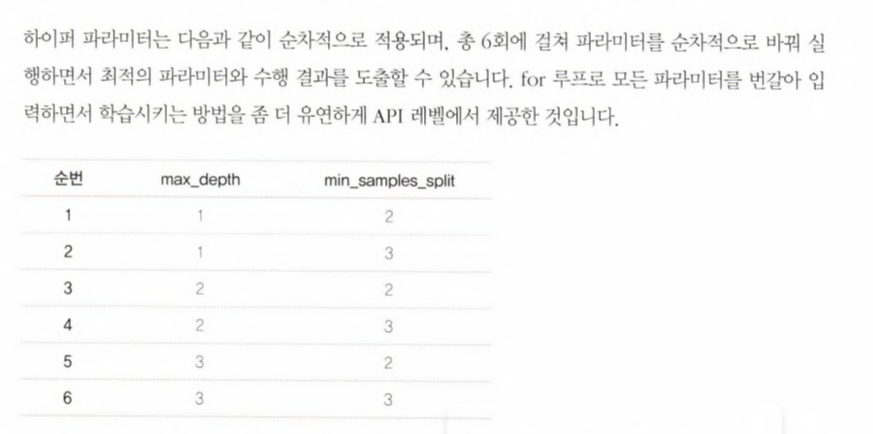
- ex. 결정 트리 알고리즘의 여러 하이퍼 파라미터를 순차적으로 변경하면서 최고 성능을 가지는 파라미터 조합을 찾고자 한다면, 파라미터의 집합을 만들고, 이를 순차적으로 적용하면서 최적화를 수행할 수 있다.
In [157]:
grid_parameters = {'max_depth':[1,2,3],'min_samples_split':[2,3]}
print(grid_parameters)
{'max_depth': [1, 2, 3], 'min_samples_split': [2, 3]}
- GridSerachCV 는 교차 검증을 기반으로, 이 하이퍼 파라미터의 최적값을 찾게 해준다.
- 즉, 데이터 셋을 CV를 위한 학습/테스트 셋으로 자동 분할한 뒤에, 하이퍼 파라미터 그리드에 기술된 모든 파라미터를 순차적으로 적용해서, 최적의 파라미터를 찾을 수 있게 해준다.
- 수행시간이 오래 걸리는게 단점
- CV가 3회라면, 개별 파라미터 조합마다 3개의 폴딩 세트를 3회에 걸쳐 학습/평가해서 평균 값으로 성능을 측정한다. 6개의 파라미터 조합이라면 CV 3회 X 6개 파라미터 조합 = 18회의 학습/평가가 이루어짐
- GridSerachCV의 주요 파라미터
- estimator : classifier, regressor, pipeline이 사용될 수 있다.
- param_grid : key + 리스트 값을 가지는 딕셔너리가 주어진다. estimator의 튜닝을 위해 '파라미터 명'과 사용될 여러 '파라미터 값'을 지정한다.
- scoring : 예측 성능을 측정할 평가 방법을 지정, accruacy등 사이킷런의 성능 평가 지표로 지정해도되고, 별도의 함수로 지정해도 무관
- cv : 교차 검증을 위해 분할되는 학습/테스트 세트의 개수 지정
- refit : 디폴트가 True이며, True로 생성시 가장 최적의 하이퍼 파라미터를 찾은 뒤, 입력된 estimator 객체를 해당 하이퍼 파라미터로 재학습시킴
In [158]:
# 결정 트리 알고리즘의 여러가지 최적화 파라미터를 순차적으로 적용해 붓꽃 데이터를
# 예측 분석하는데 GridSearchCV를 이용해보자.
In [159]:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
In [161]:
# 데이터를 로딩하고 학습 데이터와 테스트 데이터 분리
iris = load_iris()
X_train, X_test, y_train , y_test = train_test_split(
iris_data.data, iris_data.target, test_size = 0.2, random_state=121)
dtree = DecisionTreeClassifier()
## 파라미터를 딕셔너리 형태로 설정
parameters = {'max_depth':[1,2,3], 'min_samples_split':[2,3]}
- 테스트할 하이퍼 파라미터 세트는 딕셔너리 형태로
- 하이퍼 파라미 터의 명칭은 문자열 Key 값으로,
- 하이퍼 파라미터의 값은 리스트 형으로 설정
- Grid Serach CV 동작 과정을 자세히 알아보자.
- 학습 데이터 세트를 GridSearchCV 객체의 fit(학습 데이터 세트) 메소드에 인자로 입력
- GridSearchCV 객체의 fit(학습 데이터 세트) 메소드를 수행하면 학습 데이터를 cv에 기술된 폴딩 세트로 분할해 param grid에 기술된 하이퍼 파라미터를 순차적으로 변경하면서 학습/평가를 수행하고
- 그 결과를 cvresults 속성에 기록
- cv_results는 gridsearch cv의 결과 세트로서 딕셔너리 형태로 key 값과 리스트 형태의 value 값을 가지므로, cv_results」를 Pandas의 DataFrame으로 변환하면 내용을 좀 더 쉽게 볼 수 있음
In [165]:
import pandas as pd
# param_grid가 하이퍼 파라미터를 3개의 train, test set fold로 나누어 테스트 수행 결정
### refit=True가 default ( refit은 가장 좋은 파라미터 설정으로 재학습시키는 옵션 )
grid_dtree = GridSearchCV(dtree, param_grid = parameters, cv=3, refit=True)
# 붓꽃 학습 데이터로 param_grid의 하이퍼 파라미터를 순차적으로 학습/평가
grid_dtree.fit(X_train, y_train)
# Grid Search CV 결과를 추출해 DataFrame으로 변환
scores_df = pd.DataFrame(grid_dtree.cv_results_)
scores_df [['params', 'mean_test_score', 'rank_test_score', 'split0_test_score',
'split1_test_score', 'split2_test_score']]
Out[165]:
| params | mean_test_score | rank_test_score | split0_test_score | split1_test_score | split2_test_score | |
|---|---|---|---|---|---|---|
| 0 | {'max_depth': 1, 'min_samples_split': 2} | 0.700000 | 5 | 0.700 | 0.7 | 0.70 |
| 1 | {'max_depth': 1, 'min_samples_split': 3} | 0.700000 | 5 | 0.700 | 0.7 | 0.70 |
| 2 | {'max_depth': 2, 'min_samples_split': 2} | 0.958333 | 3 | 0.925 | 1.0 | 0.95 |
| 3 | {'max_depth': 2, 'min_samples_split': 3} | 0.958333 | 3 | 0.925 | 1.0 | 0.95 |
| 4 | {'max_depth': 3, 'min_samples_split': 2} | 0.975000 | 1 | 0.975 | 1.0 | 0.95 |
| 5 | {'max_depth': 3, 'min_samples_split': 3} | 0.975000 | 1 | 0.975 | 1.0 | 0.95 |
- 칼럼별 의미 정리
- params : 수행할 때마다 적용된 개별 하이퍼 파라미터 값
- rank_test_score : 하이퍼 파라미터별로 성능이 좋은 score 순위(1위인게 최적)
- mean_test_score : 개별 하이퍼 파라미터별로 cv의 폴딩 테스트 세트에 대해 총 수행한 평가 평균값
- best_params , best_score : fit() 수행시 최고 성능을 나타낸 하이퍼 파라미터 값,결과값
- 즉, cv_results의 rank_test_score가 1일 때의 값
- 총 6개의 결과 - 하이퍼 파라미터 max_depth와 min_samples_split을 순차적으로 여섯번 변경하면서 학습,평가 수행
- params 칼럼 : 수행할 때마다 적용된 하이퍼 파라미터 값을 의미
- 인덱스4 행을 보면 rank_test_score 칼럼 값이 1이다. 그 의미는 예측 성능이 1위라는 의미
- 이떄의 mean_test_score 칼럼값을 보아도 가장 높은 것을 알 수 있음
- 인덱스5 행도 값이 1이고, mean_test_score값이 위와 같음 -> 공동 1위!
- split0_test_score , split1_test_score, split2_test_score는 CV가 3인 경우 (즉 3개의 폴딩 세트에서 각각 테스트한 성능 수치)
- 이 세가지를 평균한 것이 mean_test_score
In [168]:
print('GridSearchCV 최적 파라미터:', grid_dtree.best_params_)
print('GridSearchCV 최고 정확도:{0:.4f}'.format(grid_dtree.best_score_))
GridSearchCV 최적 파라미터: {'max_depth': 3, 'min_samples_split': 2}
GridSearchCV 최고 정확도:0.9750
- max_depth가 3, min_sample_spllit이 2일 때 검증용 폴드 세트에서 평균 최고정확도가 97.5%로 측정됨
- 최적 성능을 나타내는 하이퍼 파라미터로 estimator을 학습한 best_estimator을 이용해서 앞서 분리한 테스트 데이터셋을 예측하고 평가해보자.
In [170]:
# GridSearchCV의 refit으로 이미 학습된 estimator 반환
estimator = grid_dtree.best_estimator_
In [171]:
# GridSearchCV의 best_estimator는 이미 최적 학습이 됐으므로 별도의 학습이 필요 없음
pred = estimator.predict(X_test)
print('테스트 데이터 셋 정확도: {0:4f}'.format(accuracy_score(y_test,pred)))
테스트 데이터 셋 정확도: 0.966667
1-4,1-5. 파이썬 기반의 머신러닝과 생태계 이해 - 판다스(데이터 핸들링),정리
2-4. 사이킷런으로 시작하는 머신러닝 - Model Selection 모듈 소개 (Stratified K 폴드 ~)
사이킷런 리뷰
- fit()과 predict()로 학습 및 예측 결과 반환
- classifier과 regressor을 합쳐서 estimator이라 부르고, estimator을 인자로 받는 두가지 경우는
- evaluation 함수 - cross_val_score()
- 하이퍼 파라미터 튜닝 지원 클래스 GridSearchCV.fit()
- 분류 - DecisionTreeClassifier / RandomForestClassifier / GradientBoostingClassifier / GuassianNB / SVC
- 회귀 - LineaRegression / Ridge / Lasso / RandomForestRegressor / GradientBoostingRegressor
- fit()
- 지도 학습에서는 학습을 의미
- 비지도 학습에서는 입력 데이터의 형태에 맞춰 데이터를 변환하기 위한 사전 구조를 맞추는 작업, 후에 clustering 이나 feature extraction과 같은 실제 작업은 tranform()으로 수행, 두가지를 합친 fit_transform()도 있음
- 예제 데이터 sklearn.datasets
- 피처 처리
- sklearn.preprocessing - 전처리(인코딩, 정규화, 스케일링..)
- sklearn.feature_selection - 알고리즘에 영향 미치는 순서대로 셀렉션
- sklearn.feature_extraction - 텍스트/이미지 데이터 관련 (sklearn.feature_extraction.text(image))
- sklearn.decompostion - 피처 처리, 차원 축소 (PCA, NMF, Truncated SVD)
- sklearn.model_selection - 이번에 배우고있는 모듈 : 교차 검증을 위한 데이터셋 분리, GridSearch로 최적 파라미터 추출
- sklearn.metrics - 평가 (accuracy, precision, recall, roc-auc, rmse)
- ML 알고리즘
- sklearn.ensemble ( rf, adaboost, gradient boosting )
- sklearn.linear_model ( linear reg, ridge, lasso, logistic reg, sgd
- sklearn.naive_bayes ( 가우시안, 다항분포 naive Bayes)
- sklearn.neighbors (k-nn .. )
- sklearn.svm
- sklearn.tree (from sklearn.tree import DecisionTreeClassifier)
- sklearn.cluster (비지도 클러스터링 알고리즘 k-평균, 계층형, dbscan ..)
- 유틸리티
- sklearn.pipeline - 피처처리 등 변환과 ml알고리즘 학습, 예측등 함께 묶어 실행할 수 있게 해줌
- 표본 데이터셋 생성기 - datasets.make_classifications() / datasets.make_blobs() 클러스터링을 위한 data set
- 학습/데이터 셋 분리 import sklearn.model_selection import train_test_split(test_size, train_size, shuffle=True, random_state = )
- 교차 검증
- 데이터는 이상치, 분포도, 다양한 속성값, 피처 중요도 등 여러가지 ML에 영향을 미치는 요소를 가지고있음 그렇기 때문에 특정 ML알고리즘에서 최적으로 동작하도록 데이터를 선별해 학습한다면 실제와 많은 차이가 있고, 성능저하로 이어질 것
- 이러한 데이터 편중을 막기위해, 별도로 여러 세트로 구성된 학습 데이터셋의 검증 데이터셋에서 학습과 평가를 수행하는 것. 그리고 각 세트에서 수행한 평가 결과에 따라 하이퍼 파라미터 튜닝 등 모델 최적화를 더 쉽게 할 수 있음.
- 테스트 데이터 외에 별도의 "검증 데이터"를 두어, 최종 평가 이전 학습된 모델을 다양하게 평가하는데 사용 (kfold 교차 검증은 k번째 등분이 검증 데이터, 그 다음은 k-1번째가 검증 데이터...k번 반복!)
- k폴드 교차 검증 : KFold(n_splits=) , kfold.split()
- 결정 트리
- 분할과 가지치기 과정을 반복하며 모델 생성, 결정 트리에는 분류와 회귀 모두에 사용 가능
- 각 특성이 개별 처리되기 때문에 데이터 스케일에 영향받지않아 정규화,표준화 필요X
- 단점 - 과적합 경향
- DecisionTreeClassifier()
- DecisionTreeClassifier(criterion, splitter, max_depth, min_samples_split, min_samples_leaf, min_weight_fraction_leaf, max_features, random_state, max_leaf_nodes,
min_impurity_decrease, min_impurity_split, class_weight, presort) - 사용 예제 : 데이터로드 -> 데이터 분리 -> 모델 학습(model = DecisionTreeClassifier(random_state=42) / model.fit(X_train, y_train) )
- DecisionTreeClassifier(criterion, splitter, max_depth, min_samples_split, min_samples_leaf, min_weight_fraction_leaf, max_features, random_state, max_leaf_nodes,
from sklearn.model_selection import sklearn.model_selection
Stratified KFold (for classification)
- StratifiedKFold(n_splits=)
- skf.split(df, df['label'])
- # StratifiedKFold의 split() 호출시 반드시 레이블 데이터셋도 입력!
- cross_val_score(estimator , X, y=None, scoring = None, cv = None, n_jobs = 1, verbose = 0, fit_params = None, pre_dispatch = '2*n_jobs')**
- cross_validate : 여러개의 평가 지표를 보고자할 때 사용
GridSearchCV - 교차 검증과 최적 하이퍼 파라미터 튜닝을 한 번에
'데이터 분석 > 파이썬 머신러닝 완벽가이드' 카테고리의 다른 글
| [6] 파이썬 머신러닝 완벽 가이드 - 3.평가(정확도, 오차행렬, 정밀도, ROC AUC..) (0) | 2022.08.13 |
|---|---|
| [5] 파이썬 머신러닝 완벽가이드 - 사이킷런 데이터 전처리, 타이타닉 예제, 정리 (0) | 2022.08.10 |
| [3] 파이썬 머신러닝 완벽가이드 - 판다스(데이터 핸들링) (0) | 2022.08.05 |
| [2] 파이썬 머신러닝 완벽가이드 - 넘파이 마무리, 사이킷런 fit(), predict(), 교차검증 (0) | 2022.07.26 |
| [1] 파이썬 머신러닝 완벽가이드 - 넘파이(~팬시인덱싱), 사이킷런(~붓꽃 품종 예측) (1) | 2022.07.25 |
'데이터 분석/파이썬 머신러닝 완벽가이드' Related Articles
more



