
- 분류 전체보기 (192)

Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 로그 변환
- WITH ROLLUP
- 그로스 마케팅
- sql
- 3기가 마지막이라니..!
- DENSE_RANK()
- 데이터 정합성
- 스태킹 앙상블
- python
- pmdarima
- 캐글 산탄데르 고객 만족 예측
- lightgbm
- 리프 중심 트리 분할
- tableau
- 캐글 신용카드 사기 검출
- 데이터 증식
- 부트 스트래핑
- XGBoost
- 그로스 해킹
- WITH CUBE
- 마케팅 보다는 취준 강연 같다(?)
- 분석 패널
- splitlines
- 데이터 핸들링
- Growth hacking
- 인프런
- ARIMA
- 컨브넷
- ImageDateGenerator
- 그룹 연산
Archives
- Today
- Total
LITTLE BY LITTLE
[2] 파이썬 머신러닝 완벽가이드 - 넘파이 마무리, 사이킷런 fit(), predict(), 교차검증 본문
데이터 분석/파이썬 머신러닝 완벽가이드
[2] 파이썬 머신러닝 완벽가이드 - 넘파이 마무리, 사이킷런 fit(), predict(), 교차검증
위나 2022. 7. 26. 16:23*목차
- 파이썬 기반의 머신러닝과 생태계 이해
- 머신러닝의 개념
- 주요 패키지
- 넘파이
- 판다스 (데이터 핸들링)
- 정리
- 사이킷런으로 시작하는 머신러닝(87p)
- 사이킷런 소개
- 첫번째 머신러닝 만들어보기 - 붓꽃 품종 예측
- 사이킷런 기반 프레임워크 익히기 ( fit(), predict() ..)
- Model selection 모듈 소개 (교차검증, GridSerachCV..)
- 데이터 전처리
- 사이킷런으로 수행하는 타이타닉 생존자 예측
- 정리
더보기
- 평가
- 정확도
- 오차 행렬
- 정밀도와 재현율
- F1스코어
- ROC 곡선과 AUC
- 피마 인디언 당뇨병 예측
- 정리
- 분류
- 분류의 개요
- 결정 트리
- 앙상블 학습
- 랜덤 포레스트
- GBM(Gradient Boosting Machine)
- XGBoost(eXtra Gradient Boost)
- LightGBM
- 분류 실습 - 캐글 산탄데르 고객 만족 예측
- 분류 실습 - 캐글 신용카드 사기 검출
- 스태킹 앙상블
- 정리
- 회귀
- 회귀 소개
- 단순 선형 회귀를 통한 회귀 이해
- 비용 최소화하기 - 경사 하강법 (Gradient Descent) 소개
- 사이킷런 Linear Regression을 이용한 보스턴 주택 가격 예측
- 다항 회귀와 과(대)적합/과소적합 이해
- 규제 선형 모델 - 릿지, 라쏘, 엘라스틱 넷
- 로지스틱 회귀
- 회귀 트리
- 회귀 실습 - 자전거 대여 수요 예측
- 회귀 실습 - 캐글 주택 가격 : 고급 회귀 기법
- 정리
- 차원 축소
- 차원 축소의 개요
- PCA (Principal Component Anlysis)
- LDA (Linear Discriminant Anlysis)
- SVD (Singular Value Decomposition)
- NMF (Non-Negative Matrix Factorization)
- 정리
- 군집화
- K-평균 알고리즘 이해
- 군집 평가
- 평균 이동 (Mean shift)
- GMM(Gaussian Mixture Model)
- DBSCAN
- 군집화 실습 - 고객 세그먼테이션
- 정리
- 텍스트 분석
- 텍스트 분석 이해
- 텍스트 사전 준비 작업(텍스트 전처리) - 텍스트 정규화
- Bag of Words - BOW
- 텍스트 분류 실습 - 20 뉴스그룹 분류
- 감성 분석
- 토픽 모델링 - 20 뉴스그룹
- 문서 군집화 소개와 실습 (Opinion Review 데이터셋)
- 문서 유사도
- 한글 텍스트 처리 - 네이버 영화 평점 감성 분석
- 텍스트 분석 실습 - 캐글 mercari Price Suggestion Challenge
- 정리
- 추천 시스템
- 추천 시스템의 개요와 배경
- 콘텐츠 기반 필터링 추천 시스템
- 최근접 이웃 협업 필터링
- 잠재요인 협업 필터링
- 콘텐츠 기반 필터링 실습 - TMDV 5000 영화 데이터셋
- 아이템 기반 최근접 이웃 협업 필터링 실습
- 행렬 분해를 이용한 잠재요인 협업 필터링 실습
- 파이썬 추천 시스템 패키지 - Surprise
- 정리





불리언 인덱싱(31p)
- 조건 필터링과 검색을 동시에 할 때 사용
- ex. 1차원 ndarray [1,2,3,4,5,6,7,8,9]에서 데이터 값이 5보다 큰 데이터만 추출할 때
- for loop를 돌면서 하나씩 if '추출값>5' 를 하지 않아도됨
- for loop / if else문보다 훨씬 간단하게 구현 가능
- ndarray 인덱스를 지정하는 [] 내에 조건문만 그대로 기재하면 된다.
- 불리언 인덱싱이 동작하는 단계
- array1d > 5 와 같이 ndarray의 필터링 조건을 [] 안에 기재
- False 값은 무시하고, True 값에 해당하는 인덱스 값만 저장(유의해야할 사항은 True값 자체인 1을 저장하는 것이 아니라, True 값을 가진 인덱스를 저장한다는 것)
- 저장된 인덱스 데이터셋으로 ndarray 조회
행렬의 정렬 - sort() 와 argsort()
- 넘파이의 행렬 정렬은
- np.sort()와 같이 넘파이에서 sort()를 호출하는 방식 : 원 행렬 유지, 정렬된 행렬 반환
- ndarray.sort()와 같이 행렬 자체에서 sort()를 호출하는 방식 : 원 행렬 자체를 정렬한 형태로 변환, 반환값은 None
- 내림차순으로 정렬하기 [::-1] (디폴트는 오름차순)
- 2차원 이상인 경우 정렬

- 정렬된 행렬의 인덱스를 반환하는 np.argsort()
- 넘파이에서 활용도가 높다. 넘파이의 ndarray는 'RDBMS 의 TABLE 칼럼이나, 판다스 DataFrame 칼럼'과 같은 메타 데이터를 가질 수 없다. 따라서 실제 값과 그 값이 뜻하는 메타 데이터를 별도의 ndarray로 가져야한다.
- ex. 학생별 시험 성적을 데이터로 표현
- 학생의 이름과 시험 성적 각각을 ndarray로 가져야함. (2개의 ndarray를 만들어야함)
- 이 때 시험 성적 순으로 학생 이름을 출력하고자 한다면, np.argsort (score_array)를 이용해 반환된 인덱스를 name_array에 팬시 인덱스로 적용해 추출 가능
선형대수 연산 - 행렬 내적과 전치 행렬 구하기
- 행렬 내적(행렬 곱) : np.dot()

- 전체 행렬 : np.transpose()
2-3. 사이킷런 기반 프레임워크 익히기 (93p)
Estimator 이해 및 fit() , predict() 메소드
- 사이킷런은 ML 모델 학습을 위해서 fit(), 학습된 모델의 예측을 위해서 predict() 메소드 제공
- 지도 학습의 주요 두 축인 분류와 회귀의 다양한 알고리즘 구현
- fit()과 predict()만을 이용해 간단하게 학습과 예측 결과 반환
- 분류 알고리즘 구현 클래스 = Classifier
- 회귀 알고리즘 구현 클래스 = Regressor
- Classifier와 Regressor을 합쳐서 Estimator 이라고 부름
- Estimator 클래스는 fit()과 predict()를 내부에서 구현
- 아래 두가지의 경우 이 Estimator을 인자로 받음
- evaluation 함수 : cross_val_score()
- 하이퍼 파라미터 튜닝 지원 클래스 : GridSearchCV - GridSerachCV.fit() 내에서 fit(),predict() 호출

- 비지도 학습인 차원 축소, clustering, feature extraction 등을 구현한 클래스 역시 대부분 fit()과 transform() 적용
- 단, 비지도학습과 피처 추출에서의 fit()은 지도학습에서처럼 학습을 의미하는 것이 아니라, 입력 데이터의 형태에 맞춰 데이터를 변환하기 위한 사전 구조를 맞추는 작업이다.
- fit()으로 변환을 위한 사전 구조를 맞추면, 이후 입력 데이터의 차원 변환, clustering, feature extraction 등 실제 작업은 transform()으로 수행한다.
- 두가지를 합친 fit_transform()도 있다.
- 단, 비지도학습과 피처 추출에서의 fit()은 지도학습에서처럼 학습을 의미하는 것이 아니라, 입력 데이터의 형태에 맞춰 데이터를 변환하기 위한 사전 구조를 맞추는 작업이다.
사이킷런의 주요 모듈
- 예제 데이터 - sklearn.datasets
- 피처 처리
- sklearn.preprocessing - 전처리에 필요한 가공 기능 제공(인코딩,정규화,스케일링..)
- sklearn.feature_selection - 알고리즘에 큰 영향을 미치는 피처 순서대로 셀렉션 작업 수행 기능 제공
- sklearn.feature_extraction - 텍스트/이미지 데이터의 벡터화된 피처 추출에 사용 (ex. 텍스트 데이터에서 Count Vectorizer / Tf-Idf Vectorizer 생성 기능 제공)
- 텍스트 데이터의 피처 추출 - sklearn.feature_extraction.text 모듈에 지원 API가 있음
- 이미지 데이터의 피처 추출 - sklearn.feature_extraction.image 모듈에 지원 AIP가 있음
- 피처 처리 & 차원 축소 - sklearn.decomposition - 차원 축소 관련 알고리즘 지원. (PCA, NMF, Truncated SVD)
- 데이터 분리,검증 & 파라미터 튜닝 - sklearn.model_selection - 교차 검증을 위한 학습용/테스트용 데이터 분리, Grid Serach로 최적 파라미터 추출등의 API 제공
- 평가 - sklearn.metrics - 분류,회귀,클러스터링,페어와이즈에 대한 다양한 성능 측정 방법 제공 (Accuracy, Precision, Recall, ROC-AUC, RMSE ..)
- ML 알고리즘
- sklearn.ensemble (random forest, adaboost, gradiant boosting)
- sklearn.linear_model (linear regression, Ridge, Lasso, logistic Regression. SGD[Stochastic Gradient Descent])
- sklearn.naive_bayes - 나이브 베이즈 알고리즘 제공, 가우시안 NB, 다항 분포 NB
- sklearn.neighbors - 최근접 이웃 알고리즘 제공 (K-NN..)
- sklearn.svm - suppport vector machine
- sklearn.tree - decision tree
- sklearn.cluster - 비지도 클러스터링 알고리즘 제공(K-평균, 계층형, DBSCAN..)
- 유틸리티 - sklearn.pipeline - 피처처리 등 변환과 ML 알고리즘 학습, 예측등을 함께 묶어 실행할 수 있는 유틸리티 제공

fetch 계열 명령
- 인터넷에서 내려받아 홈 디렉터리 아래 scikit_learn_data라는 서브 디렉터리에 저장 후 추후 불러들이는 데이터

표본 데이터 생성기
- datasets.make_classifications() : 분류를 위한 데이터셋을 만듦. 높은 상관도, 불필요한 속성 등 노이즈 효과를 위한 데이터를 무작위로 생성함
- datasets.make_blobs() : 클러스터링을 위한 데이터셋을 무작위로 생성해줌. 군집 지정 개수에 따라 여러가지 클러스터링을 위한 데이터셋을 쉽게 만들어줌.
iris 데이터셋 구성
- 일반적으로 딕셔너리 형태로 되어있다.
- 키는 보통 data, target, target_name, feature_names, DESCR로 구성
- data : 피처의 데이터셋
- target : 분류시 레이블 값, 회귀일 때에는 숫자 결괏값 데이터 셋
- target_names : 개별 레이블 이름
- feature_names : 피처의 이름
- DESCR : 데이터셋에 대한 설명과 각 피처의 설명을 나타냄
- data, target은 넘파이 배열 ndarray 형태
- target_names, feature_names는 ndarray 또는 파이썬리스트 list 타입
- DESCR은 스트링 string
- 피처의 데이터 값 반환을 위해서는 내장 데이터셋 API 먼저 호출, 그 뒤에 Key 값 지정하기



2-4. Model Selection 모듈 소개 (100p)
학습/테스트 데이터 셋 분리 - train_test_split()
- 테스트 데이터셋을 이용하지 않고, 학습 데이터셋으로만 학습하고, 예측하면 무엇이 문제인지 살펴보자

- train_test_split 옵션 설명
- test_size : 테스트 데이터셋 크기 (디폴트는 25%)
- train_size : 학습용 데이터셋 크기 (잘 사용하지 x)
- shuffle : 데이터 분리 전 섞을 것인지결정 (디폴트는 True)
- random_state (호출할 때마다 동일한 학습/테스트용 데이터셋 생성하기위해 주어지는 난수값, 수행ㅎ알 때마다 같은 학습/테스트용 데이터셋을 생성하려면 일정한 숫자로 부여하기.)
- train_test_split()의 반환값은 튜플 형태이다. 순차적으로 학습용, 테스트용, 학습용 레이블, 테스트용 레이블 반환

교차 검증
- 과적합 : 모델이 학습 데이터에만 과도하게 최적화되어, 실제 예측은 다른 데이터로 수행할 경우에는 예측 성능이 과도하게 떨어지는 것
- 고정된 학습데이터와 테스트 데이터로 평가하다보면, 테스트 데이터에만 최적의 성능을 발휘할 수 있도록 편향되게 모델을 유도하는 경향이 생기게된다. 따라서, 해당 테스트 데이터에만 과적합되는 학습모델이 만들어져 다른 테스트용 데이터가 들어올 경우 성능이 저하됨
- 이러한 문제 개선을 위해 교차 검증을 이용해 더 다양하고 많은 학습,평가 수행
- 데이터는 이상치, 분포도, 다양한 속성값, 피처 중요도 등 여러가지 ML에 영향을 미치는 요소를 가지고있음 그렇기 때문에 특정 ML알고리즘에서 최적으로 동작하도록 데이터를 선별해 학습한다면 실제와 많은 차이가 있고, 성능저하로 이어질 것
- 이러한 데이터 편중을 막기위해, 별도로 여러 세트로 구성된 학습 데이터셋의 검증 데이터셋에서 학습과 평가를 수행하는 것. 그리고 각 세트에서 수행한 평가 결과에 따라 하이퍼 파라미터 튜닝 등 모델 최적화를 더 쉽게 할 수 있음.
- 테스트 데이터 외에 별도의 "검증 데이터"를 두어, 최종 평가 이전 학습된 모델을 다양하게 평가하는데 사용

K 폴드 교차 검증
- 5-fold의 경우,
- 먼저 데이터 셋을 5등분하고,
- 첫번째 반복에서는 처음부터 4개 등분을 학습 데이터셋, 마지막 5번째 등분 하나를 검증 데이터셋으로 설정
- 학습 데이터셋에서 학습 수행, 검증 데이터셋에서 평가 수행
- 단, 이번에는 학습 데이터와 검증 데이터를 변경 (처음부터 3개 등분까지, 그리고 마지막5번째 등분을 학습 데이터셋으로, 4번째 등분 하나를 검증 데이터셋으로)
- 이런식으로 반복하며 5번째까지 학습과 검증을 수행하는 것이 k-fold cross validation
- 사이킷런에서는 k-fold 교차검증 프로세스 구현을 위해 k-fold와 stratifiedKFold 클래스 제공
- KFold(n_splits=)
- kfold.split()
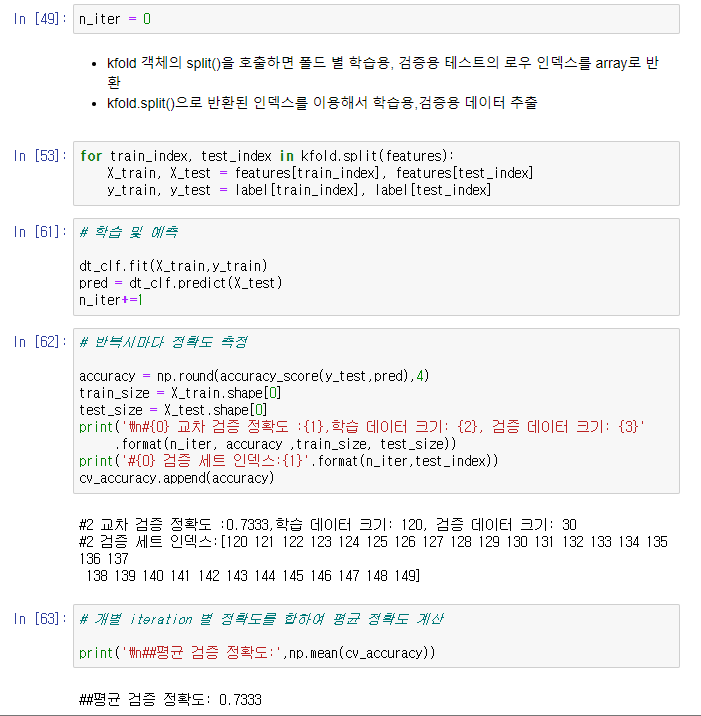
- 교차 검증시마다 검증 세트의 인덱스가 달라짐을 눈으로 확인해볼 수 있다.
- 학습 데이터 세트의 인덱스는 수가 많아서 출력하지 않았지만, 검증 세트의 인덱스를 보면 교차검증시마다 split()함수가 어떻게 인덱스를 할당하는지 알 수 있다.
- 1번째 교차검증에서는 0~29번, 두번째는 30~59번 .. 이런식으로 각각 30개의 검증 세트 인덱스를 생성했고, 이를 기반으로 검증 세트를 추출하였다.
'데이터 분석 > 파이썬 머신러닝 완벽가이드' 카테고리의 다른 글
| [6] 파이썬 머신러닝 완벽 가이드 - 3.평가(정확도, 오차행렬, 정밀도, ROC AUC..) (0) | 2022.08.13 |
|---|---|
| [5] 파이썬 머신러닝 완벽가이드 - 사이킷런 데이터 전처리, 타이타닉 예제, 정리 (0) | 2022.08.10 |
| [4] 파이썬 머신러닝 완벽가이드 - 판다스(데이터 핸들링) 마무리, 사이킷런 모듈 연습 마무리(Stratified K fold, GridSearchCV) (0) | 2022.08.06 |
| [3] 파이썬 머신러닝 완벽가이드 - 판다스(데이터 핸들링) (0) | 2022.08.05 |
| [1] 파이썬 머신러닝 완벽가이드 - 넘파이(~팬시인덱싱), 사이킷런(~붓꽃 품종 예측) (0) | 2022.07.25 |
'데이터 분석/파이썬 머신러닝 완벽가이드' Related Articles
more




Comments