
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 로그 변환
- sql
- 데이터 정합성
- Growth hacking
- 리프 중심 트리 분할
- XGBoost
- python
- 데이터 핸들링
- 그로스 마케팅
- ARIMA
- 분석 패널
- 캐글 신용카드 사기 검출
- tableau
- 인프런
- 부트 스트래핑
- 그룹 연산
- WITH ROLLUP
- WITH CUBE
- 3기가 마지막이라니..!
- 캐글 산탄데르 고객 만족 예측
- 스태킹 앙상블
- 마케팅 보다는 취준 강연 같다(?)
- lightgbm
- pmdarima
- 데이터 증식
- 컨브넷
- DENSE_RANK()
- ImageDateGenerator
- splitlines
- 그로스 해킹
- Today
- Total
LITTLE BY LITTLE
[5-2] 실무로 통하는 인과추론 with 파이썬 - 5장. 성향점수 본문

목차
<5장 성향점수>
5.1 관리자 교육의 효과
5.2 회귀분석과 보정
5.3 성향점수
5.3.1 성향점수 추정
5.3.2 성향점수의 직교화
5.3.3 성향점수 매칭
5.3.4 역확률 가중치
5.3.5 역확률 가중치의 분산
5.3.6 안정된 성향점수 가중치
5.3.7 유사 모집단
5.3.8 선택편향
5.3.9 편향-분산 트레이드오프
5.3.10 성향점수의 양수성 가정
5.4 디자인 vs 모델 기반 식별
5.5 이중 강건 추정
5.5.1 처치 모델링이 쉬운 경우
5.5.2 결과 모델링이 쉬운 경우
5.6 연속형 처치에서의 일반화 성향 점수
5.7 요약
5장. 성향점수
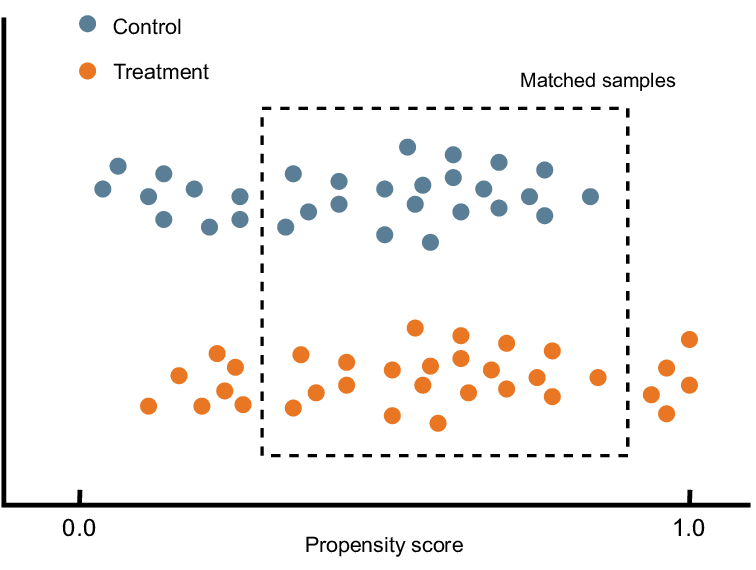
4장에서는 선형회귀분석을 사용하여 교란 요인을 보정하는 방법과, 직교화를 활용한 편향 제거라는 개념을 소개했다.
5장에서는 또다른 편향 제거 방법 중 하나인 성향점수 가중치를 배운다.
→ "잔차 생성" 대신에, "처치 배정 메커니즘을 모델링하고 모델 예측을 사용하여 데이터를 재조정"한다.
→ '이진'이나 '이산형' 처치가 있을 때 적합한 방법을 주로 소개한다.
5.4 디자인 vs. 모델 기반 식별
- 앞서 성향점수 가중치를 사용해서 처치효과를 추정하는 두 가지 방법인 성향점수 매칭(PSM)과 역확률 가중치(IPW)를 다뤘다.
- 그렇다면, 회귀분석과 역확률 가중치 중에서 어떤 것을 사용하면 좋을지 알 수 있는 방법이 있을까?
이 선택은, '모델 기반 식별'과 '디자인 기반 식별'에 관한 논의를 내포한다.
✅모델 기반 식별 (9장. 통제집단합성법)
: 처치 및 추가 공변량을 조건부로 설정하고, 잠재적 결과에 대한 모델 형태로 가정하는 것을 포함하는 것으로, 추정에 필요한 누락된 잠재적 결과를 대체하는 것을 목표로 한다.
✅디자인 기반 식별 (ex. IPW)
: 처치 배정 메커니즘에 대한 가정을 하는 것으로, 통계적 모델링이 아닌, 연구 디자인(ex. 자연 실험, 준실험 등)에 기반한 인과추론을 디자인 기반 식별(인과추론)이라고 부르기도 한다.
4장에서 회귀분석은 두 가지 전략에 모두 부합하는 방법임을 살펴보았다.
- 회귀분석은 직교화 관점에서 보면 디자인 기반이고,
- 또 잠재적 결과 모델의 추정량 관점에서는 모델 기반이다.
따라서 두 가지 식별 중 하나를 선택하려면, 다음의 두 가지 질문을 해야 한다.
- 처치가 어떻게 배정되었는지 잘 이해하고 있는지
- 잠재적 결과 모델을 올바르게 지정하는 더 좋은 방법이 있는지
5.5 이중 강건 추정
이중 강건(DR, doubly robust) 추정
: 모델 기반과 디자인 기반 식별을 모두 결합하여, 적어도 둘 중 하나가 정확하기를 기대하는 방법으로, 이번 절에서는 성향점수와 선형회귀분석을 결합하는 방법을 살펴본다.
* 이중 강건 추정량은 IPW에 덧붙인 식(augmentation)이 추가되었다고 하여 Augmented IPW(AIPW)라고 부른다.
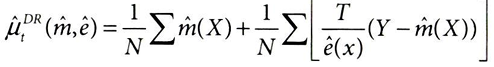
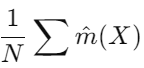
① 결과 모델 기반 예측
: 주어진 공변량 X에서, E[Yt|X]에 대한 모델에서 예측된 결과 m^(X) (선형회귀)
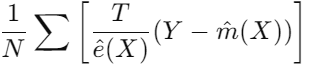
② 성향 점수 기반 가중치 적용
: P(T|X)의 성향점수의 역수(1/ e^(X))로 관찰된 결과와 예측된 결과 간의 차이를 조정하는 부분
→ 두 모델 중 하나만 올바르게 지정하면 되기에, 위의 식은 이중 강건하다.
- 만약 성향점수 모델이 잘못되고, 결과 모델이 정확(m^(X)=Y) 하다고 가정했을 때,
- E[Y-m^(X)]=0이므로 ② 성향 점수 기반 가중치 적용 부분은 0에 수렴한다.
- 따라서 결과 모델인 첫 번째 항만 남게된다.
반대로 결과 모델이 부정확하고, 성향점수 모델이 정확하다 했을 때를 보기 위해 앞의 식을 약간 변형해보면,아래와 같은 식이 된다.
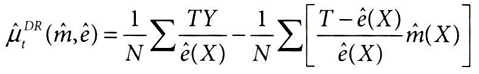

① 처치에 대한 결과 가중치 적용 (IPW 추정량)
: 처치가 이루어진 샘플(TY)에 대해 성향 점수로 가중치를 적용한(1/e^(X)) 실제 결과
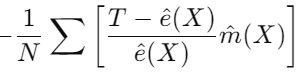
② 결과 모델 기반 조정
: 처치와 성향점수의 차이를 결과 모델 예측값으로 조정하는 부분
- 성향점수 모델이 정확(e^(X)=T) 하다면, T-e^(X)는 0으로 수렴할 것
- 그러면 첫 번째 항인 IPW추정량만 남게 된다.
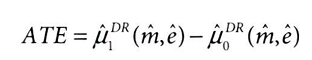
이중 강건 추정량을 코드로 구현해보자.
1. 로지스틱 회귀분석을 사용하여 성향점수 모델을 적합시켜 e^(X)를 얻기
from sklearn.linear_model import LinearRegression
def doubly_robust(df, formula, T, Y):
X = dmatrix(formula, df)
ps_model = LogisticRegression(penalty="none",
max_iter=1000).fit(X, df[T])
ps = ps_model.predict_proba(X)[:, 1]
2. 처치 변형(variant)별로 하나의 선형회귀를 적합시켜, 실험군-대조군 각각에 대해 두 모델 만들기
*모델은 실험군, 대조군 각각에 적합되지만, 전체 데이터셋에 대한 예측을 하는 것
m0 = LinearRegression().fit(X[df[T]==0, :], df.query(f"{T}==0")[Y])
m1 = LinearRegression().fit(X[df[T]==1, :], df.query(f"{T}==1")[Y])
m0_hat = m0.predict(X)
m1_hat = m1.predict(X)
3. 마지막으로 이중 강건 추정량 공식을 코드로 구현
(처치 그룹에서 관찰된 결과 T(Y)와 예측 결과(m^(X) 차이를 성향점수(e(X)로 조정한 값) - (비처치 그룹에서 ~)
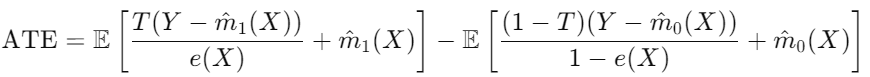
* 실험-대조군 모두 m^(X) 더해주는 이유는, 전체 추정량이 성향 점수 모델의 편향을 보정하면서도 결과 모델 예측값을 유지하게 하기 위함
return (
np.mean(df[T]*(df[Y] - m1_hat)/ps + m1_hat) -
np.mean((1-df[T])*(df[Y] - m0_hat)/(1-ps) + m0_hat)
)
앞의 함수로 관리자 교육에서의 이중강건 추정량을 구해보자.
formula = """tenure + last_engagement_score + department_score
+ C(n_of_reports) + C(gender) + C(role)"""
T = "intervention"
Y = "engagement_score"
print("DR ATE:", doubly_robust(df, formula, T, Y))
>> DR ATE: 0.27115831057931455
est_fn = partial(doubly_robust, formula=formula, T=T, Y=Y)
print("95% CI", bootstrap(df, est_fn)) ## 앞서 만든 부트스트랩 함수에 전달하여 신뢰구간도 출력
>> 95% CI [0.23012681 0.30524944]- 앞서 살펴본 IPW 추정량과, 회귀 추정량과 꽤 비슷하다. 이중 강건 추정량이 정상적으로 작동함을 알 수 있다.
이중 강건성이 왜 흥미로운지 이해를 돕기 위한 두 가지 예시를 살펴보자.
5.5.1 처치 모델링이 쉬운 경우
: 처치 배정을 모델링하기 쉽지만, 결과 모델은 조금 더 복잡한 경우
처치가 다음의 성향점수에 따라 주어진 확률로, 베르누이 분포를 따른다고 가정해보자.
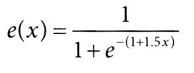
위 식은 로지스틱 회귀분석이 가정하는 형태와 정확히 일치하므로 추정하기 매우 쉽다.
np.random.seed(123)
n = 10000
x = np.random.beta(1,1, n).round(2)*2
e = 1/(1+np.exp(-(1+1.5*x)))
t = np.random.binomial(1, e) ## 처치는 베르누이 분포를 따른다고 가정
y1 = 1
y0 = 1 - 1*x**3
y = t*(y1) + (1-t)*y0 + np.random.normal(0, 1, n)
df_easy_t = pd.DataFrame(dict(y=y, x=x, t=t))
print("True ATE:", np.mean(y1-y0))
>> True ATE: 2.0056243152
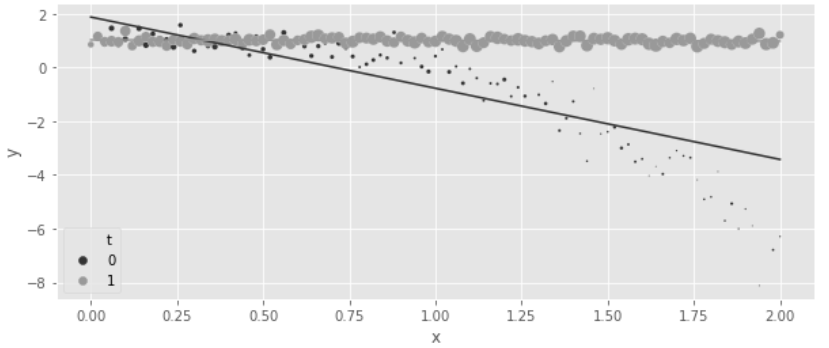
- 왼쪽 그래프(P(T|X))는 성향 점수 모델링이 쉽다는 것을 보여줌
- X 값이 증가함에따라 P(T=1|X)가 증가하는 경향이 존재
- X와 T의 관계가 명확하고, 성향 점수 e(X)가 잘 정의되어 있기 때문
- 오른쪽 그래프(E(Y|X,T))에서 효과 이질성 존재하여 결과 모델링이 어려움을 보여줌
- X값이 낮을 때에는 효과가 0이고, X가 증가함에 따라 비선형적으로 효과가 증가한다.
- 특히 T=0일 때 Y값이 비선형적으로 감소하는 반면, T=1일 때에는 Y갑싱 일정하게 유지되어 결과 모델링이 더 어려움을 보여줌
m0 = smf.ols("y~x", data=df_easy_t.query("t==0")).fit()
m1 = smf.ols("y~x", data=df_easy_t.query("t==1")).fit()
regr_ate = (m1.predict(df_easy_t) - m0.predict(df_easy_t)).mean()
print("Regression ATE:", regr_ate)
>> Regression ATE: 1.786678396833022→ 예상대로 회귀 모델은 실제 ATE인 2를 추정하지 못했다.
원본 데이터에 대해 예측값을 시각화해서 이유를 살펴보면,
→ 회귀모델이 대조군(T=0)에서의 곡률을 제대로 포착하지 못했기 때문임을 알 수 있다.
데이터의 실제 곡률을 알면 정확하게 모델링할 수 있다.
m = smf.ols("y~t*(x + np.power(x, 3))", data=df_easy_t).fit() # 공변량 X와 X^3을 포함시켜 곡률 반영
regr_ate = (m.predict(df_easy_t.assign(t=1))
- m.predict(df_easy_t.assign(t=0))).mean()
print("Regression ATE:", regr_ate)
>> Regression ATE: 1.9970999747190072 → 하지만 현실에서는 데이터 생성 과정을 정확히 알 수 없다.
반면, IPW는 어떤지 살펴보자
*처치 배정을 모델링하기 쉬우므로, IPW는 이 데이터에서 잘 적용될 것
est_fn = partial(est_ate_with_ps, ps_formula="x", T="t", Y="y")
print("Propensity Score ATE:", est_fn(df_easy_t))
print("95% CI", bootstrap(df_easy_t, est_fn))
>> Propensity Score ATE: 2.002350388474011
>> 95% CI [1.80802227 2.22565667]* est_fn 함수(🔻)
# IPW로 ATE를 추정하는 함수
def est_ate_with_ps(df, ps_formula, T, Y):
# 데이터프레임 df를 디자인 행렬 X로 변환 (로지스틱 회귀의 input으로 사용)
X = dmatrix(ps_formula, df)
# 로지스틱 회귀 모델 생성, 디자인 행렬 x와 T로 모델 학습
ps_model = LogisticRegression(penalty="none",
max_iter=1000).fit(X, df[T])
# 학습한 모델을 사용하여 각 샘플에 대해 T=1에 속할 확률 예측
ps = ps_model.predict_proba(X)[:, 1]
# ATE 추정(역확률 가중치 공식 활용)
return np.mean((df[T]-ps) / (ps*(1-ps)) * df[Y])
est_fn = partial(est_ate_with_ps, ps_formula=formula, T=T, Y=Y)이제 이중 강건 추정값을 확인해보자.
*두 모델 중 P(T|X) 모델은 정확하고, E[Yt|X]모델은 정확하지 않기에, 한 가지만 정확하면 되는 이중 강건 추정량은 정확히 ATE 를 추정할 것
est_fn = partial(doubly_robust, formula="x", T="t", Y="y")
print("DR ATE:", est_fn(df_easy_t))
print("95% CI", bootstrap(df_easy_t, est_fn))
>> DR ATE: 2.001617934263116
>> 95% CI [1.87088771 2.145382]
- 예상대로 정확하게 2로 ATE를 추정했다.
- 더 주목할 점은, 순수 IPW 추정값에 비해 95% 신뢰구간이 더 좁다는 것, 즉 이중 강건 추정량이 더 정밀함을 의미
그렇다면 반대의 경우는 어떨까?
5.5.2 결과 모델링이 쉬운 경우
이번에는 결과 함수는 단순히 선형이지만, P(T|X)는 비선형인 데이터로 추정량을 비교해보자. (실제 ATE=-1)
np.random.seed(123)
n = 10000
x = np.random.beta(1,1, n).round(2)*2
e = 1/(1+np.exp(-(2*x - x**3)))
t = np.random.binomial(1, e)
y1 = x
y0 = y1 + 1 # ate of -1
y = t*(y1) + (1-t)*y0 + np.random.normal(0, 1, n)
df_easy_y = pd.DataFrame(dict(y=y, x=x, t=t))
print("True ATE:", np.mean(y1-y0))
>> True ATE:-1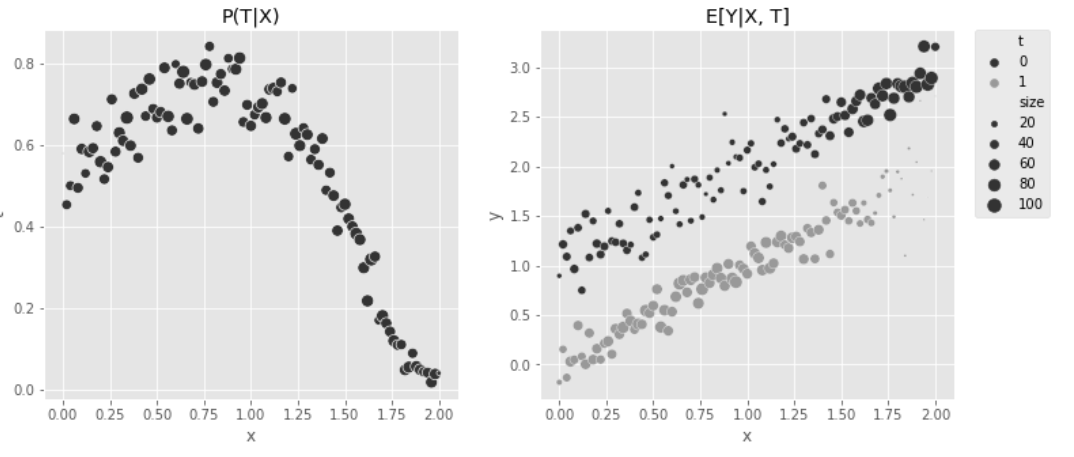
성향 점수 모델링이 복잡한 경우이므로, IPW는 실제 ATE를 제대로 추정하기 어렵다.
est_fn = partial(est_ate_with_ps, ps_formula="x", T="t", Y="y")
print("Propensity Score ATE:", est_fn(df_easy_y))
print("95% CI", bootstrap(df_easy_y, est_fn))
>> Propensity Score ATE: -1.1042900278680896
>> 95% CI [-1.14326893 -1.06576358]
반면 회귀 모델은 ATE를 정확하게 추정할 수 있다.
m0 = smf.ols("y~x", data=df_easy_y.query("t==0")).fit()
m1 = smf.ols("y~x", data=df_easy_y.query("t==1")).fit()
regr_ate = (m1.predict(df_easy_y) - m0.predict(df_easy_y)).mean()
print("Regression ATE:", regr_ate)
>> Regression ATE: -1.0008783612504342
이중 강건 추정량을 확인해보자. 여기에서도 실제 ATE를 구할 수 있을 것
est_fn = partial(doubly_robust, formula="x", T="t", Y="y")
print("DR ATE:", est_fn(df_easy_y))
print("95% CI", bootstrap(df_easy_y, est_fn))
>> DR ATE: -1.0028459347805823
>> 95% CI [-1.04156952 -0.96353366]- 위 두가지 예시로 이중 강건 추정이 왜 매우 흥미로운지 이해할 수 있었다.
- 중요한 점은, 이중 강건 추정이 정확도를 높일 2번의 기회를 제공한다는 것
- P(T|X)와 E[Yt|X] 모델 중 하나만 정확히 모델링)할 수 있다면 충분하다.
* 이중 강건(DR) 추정량은 여러 추정량 중 하나로, DR추정량을 사용하되, 가중치를 e^(X)로 설정하여 회귀 모델에 적용하거나, 회귀 모델에 e^(X)를 추가하는 등 다양한 방법이 있다. (선형회귀 자체는 e(X)=βX를 모델링하는 DR추정량이라고 한다.)
5.6 연속형 처치에서의 일반화 성향 점수
- 4장 회귀분석에서는 연속형 처치에 대해 처치 반응의 함수 형태를 가정하여 연속형 처치를 다루었었다.
- y=a+bt (선형) 형태나, y=a+b √t (제곱근) 형태를 가정한 다음 OLS로 추정
- 하지만 성향 점수 가중치(1/e(X))에서 모수적 반응 함수와 같은 것은 존재하지 않음
- 성향 점수 가중치는 잠재적 결과를 재조정하고, 평균을 구하는 형태인 비모수적 방식으로 추정됨
- T가 연속형일 때에는, 잠재적 결과 Yt가 무한히 많이 존재하고,
- 연속형 변수의 확률은 항상 0이므로 P(T=t|X)를 추정할 수 없음
위의 문제를 해결하기 위해서,
- 연속형 처치를 이산화(discretize)하거나,
- 일반화 성향점수(GPS, Generalized Propensity Score)를 사용할 수 있다.
✅ 대출 금리(T)가 고객이 대출금을 상환하는 기간(Y, 월 단위)에 미치는 영향을 알고 싶을 때
- 사람들은 이자 지불을 최소화하기 위해 고금리 대출을 빨리 상환하고 싶어할 것이기 때문에, 금리가 대출 상환기간에 미치는 영향은 음수여야 한다.
- 금리를 무작위로 배정해서 답을 얻을 수 있으나, 큰 비용이 소모되기에 이미 보유한 데이터를 사용해서 추정하기
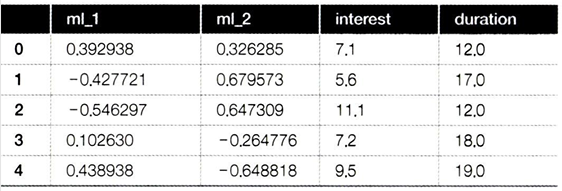
- 금리는 두 가지 머신러닝 모델(ml_1, ml_2)에 따라 배정되었으며, 금리 결정 과정에 가우스 잡음을 추가하여 정책이 비결정적이고 양수성 가정을 위배하지 않도록 했다.
- ml_1과 ml_2는 교란 요인
*가우스 잡음: 가우스 분포를 따르는 잡음으로, 가우스 분포는 우리가 흔히 아는 정규분포를 의미하며, 백색 잡음이라고 불리기도 함
아무것도 보정하지 않으면 양의 처치효과를 얻게 된다.
m_naive = smf.ols("duration ~ interest", data=df_cont_t).fit()
m_naive.summary().tables[1]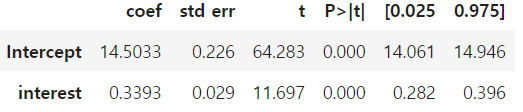
→ ml_1과 ml_2를 모델에 포함해서 보정할 수 있지만, 재조정으로 문제를 다뤄보자.
- 연속형 변수가 어디서나 확률이 0이라는 사실 (P(T=t) = 0) 해결
- 조건부 확률 P(T=t|X) 대신 조건부 밀도함수 f(T|X)를 사용할 수 있다.
- 조건부 밀도 함수는 샘플이 얼마나 '일반적'인지 측정한다. 특정 처치 값에서 밀도가 낮으면, 해당 조건에서 드문 사례
- 드문 사례일수록, 모델이 그 샘플에 대해 잘 예측하지 못할 가능성이 높아지고, 그로 인해 잔차가 커질 수 있어, 잔차가 큰 실험 대상(조건부 밀도함수가 낮은)에 높은 가중치(역수)를 부여하는 것
- 대신, 처치 분포를 정해야 한다. 여기에서는 정규분포에서 추출되었다고 가정하자. (T~N(μ,σ ^2))
- 또한, 이분산이 아닌 등분산 σ ^2을 가정한다.
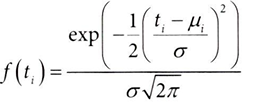
✅ 연속형 처치에서 조건부 밀도 함수를 사용하여 처치 효과 추정하기
조건부 밀도함수로 연속형 처치에서 공변량 X에 따른 처치 T의 분포를 추정하여 성향점수의 연속형 버전 값 구하기
1. 조건부 정규분포의 매개변수인 평균과 표준편차를 추정하기 위해서 공변량X로 처치변수(interest) 적합
model_t = smf.ols("interest~ml_1+ml_2", data=df_cont_t).fit()
2. 조건부 밀도함수의 추정값 얻기
: 적합된 값을 μi로 사용하고, 잔차의 표준편차를 σ 로 사용, 처치에 해당하는 조건부 밀도를 평가하기 위해 밀도 함수의 x인수에 t전달하기
def conditional_density(x, mean, std):
denom = std*np.sqrt(2*np.pi) # denominator, 정규분포의 분모
num = np.exp(-((1/2)*((x-mean)/std)**2)) #nominator, 정규분포의 분자
return (num/denom).ravel() # 정규분포의 밀도 값 계산, ravel()함수를 사용하여 1차원 배열로 반환
3. 함수 호출 및 조건부 밀도 함수 계산
gps = conditional_density(df_cont_t["interest"], # x
model_t.fittedvalues, # mean = OLS(T~X) 회귀모델의 적합된 값 = 예측 값
np.std(model_t.resid)) # std = 회귀모델의 잔차의 표준편차(=분포의 변동성)
gps
>> array([0.1989118 , 0.14524168, 0.03338421, ..., 0.07339096, 0.19365006,
0.15732008])
*위의 2,3 대신 scipy의 정규분포 함수 활용
scipy.stats.norm.pdf(x, loc=0, scale=1) *loc=mean, scale=std
from scipy.stats import norm
gps = norm(loc=model_t.fittedvalues,
scale=np.std(model_t.resid)).pdf(df_cont_t["interest"])
gps
>> array([0.1989118 , 0.14524168, 0.03338421, ..., 0.07339096, 0.19365006,
0.15732008])✅ 처치가 정규분포가 아닌 다른 분포를 따를 때
일반화선형모델(glm, generatlized linear model) 사용하기
smf.glm(formula=formula, data=data, family=sm.families.Binomial()) ←family로 분포 지정
예를 들어 T가 포아송 분포에 따라 배정된 경우, 다음과 같이 일반화 성향점수의 가중치 만들기
import statsmodels.api as sm
from scipy.stats import poisson
mt = smf.glm("t~x1+x2",
data=df, family=sm.families.Poisson()).fit()
gps = poisson(mu=m_pois.fittedvalues).pmf(df["t"])
w = 1/gps
scipy.stats.norm.pdf로 구한 조건부 밀도 함수(↔일반화 성향점수)의 역수를 가중치로 편향 보정하기
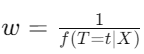
final_model = smf.wls("duration~interest",
data=df_cont_t, weights=1/gps).fit()
final_model.params["interest"]
>> -0.6673977919925854→ 금리(T)가 상환기간(Y)에 미치는 음의 영향을 발견하여 결과가 사업적으로 더 타당함을 알 수 있다.
- 이 점수를 사용하여 가중치를 구성하면, 특정 T값이 주어진 공변량X에서 나올 확률이 낮을수록(↔밀도가 낮을수록) 그 샘플에 더 많은 중요성을 부여한다.
- 그러면, 적합된 처치 모델에서 잔차가 큰 실험 대상에 높은 가중치를 할당한다.
✅ 주변 밀도 함수 f(t)로 가중치 안정화시키기
정규분포의 지수적 특성

- 정규 분포의 밀도 함수는 관찰값 X가 평균 μ에서 멀어질수록 지수적으로 감소한다.
- 따라서 그 역수인 가중치는 잔차의 크기에 따라 기하급수적으로 증가함
- 이는 잔차가 큰 실험 대상에 더 높은 가중치를 부여하여, 이러한 샘플이 적합 과정에서 더 큰 비중을 가지게 만듦
✅ 예를 들어 ml1_1과 ml_2를 모두 사용하지 않고 ml_1만 사용하여 금리를 적합시킨 경우를 가정해보자.

- 왼쪽 그래프는 원본 데이터를 교란요인 ml_1에 따라 색상으로 구분해서 보여준다. (T와 X의 관계)
- ml_1 점수가 낮은(색상이 진한) 고객은 y축인 duration(상환 기간)이 길다.
- x축인 금리(T)와 y축인 상환기간(Y)에는 상향 편향이 존재
- 가운데 그래프는 처치 모델의 적합된 값과 얻은 가중치가 표시된다. (교란 요인 ml_1에 따른 처치 interest)
- 가중치(원의 크기)는 적합된 선에서 멀어질수록 커진다.
- 일반화 성향점수(가중치)가 가능성이 낮은 처치에 더 많은 가중치를 부여했기 때문
- 가중치가 1,000을 넘는 등 값이 매우 클 수 있어 가중치의 크기가 얼마나 커질 수 있는지에 유의해야 한다.
- 오른쪽 그래프는 가중치를 동일하게 유지하면서 금리(T)와 상환기간(Y)의 관계를 보여준다.
- 양쪽 끝(교란요인 ml_1이 매우 높거나 낮을 때)에 높은 이자율(T)가 드물게 나타나므로, 이러한 포인트에 큰 중요도가 부여된다.
- 이를 통해서 왼쪽 그래프에 나타나는 상향 편향된 관계를 뒤집을 수 있다.
→ 이산형 처치에서 가중치 안정화는 선택사항이었으나, 연속형 처치에서 일반화 성향점수를 사용할 때는 필수이다.
→ 가중치 안정화를 통해 처치 값이 평균에서 멀리 떨어진 샘플에 대해 가중치를 줄여 분산을 줄임
*가중치 안정화
: 가중치가 너무 클 때 계산 상의 문제가 발생할 수 있기에, T의 주변확률 P(T=t)로 가중치를 안정화시킬 수 있다. 안정된 가중치는 실험군과 대조군의 유효 크기(↔ 가중치의 합)가 각각 원래의 실험군과 대조군의 크기와 일치하는 유사모집단을 재구성하는 방법이다.
1. Stabilizer 생성
: 처치 값의 분포를 정규분포로 가정하고, 처치 값이 정규 분포에서 나올 확률 밀도 계산
*loc = T의 mean, scale = T의 std, pdf = T의 확률 밀도
# gps(generalized propensity score)
stabilizer = norm(
loc=df_cont_t["interest"].mean(),
scale=np.std(df_cont_t["interest"] - df_cont_t["interest"].mean())
).pdf(df_cont_t["interest"])2. gipw(안정화된 가중치) 계산
: 일반화 성향 점수(gps)에 대해 stabilizer을 나누어 가중치 조정하기
gipw = stabilizer/gps
print("원래 표본 크기:", len(df_cont_t))
>> 원래 표본 크기: 10000
print("안정화 후 유효 크기:", sum(gipw))
>> 안정화 후 유효 크기: 9988.19595174861- 역확률 가중치는 처치 모델의 적합된 값에서 멀리 떨어진 포인트에 높은 중요도를 부여하고,
- 가중치 안정화는 f(t)에서 멀리 떨어진 포인트에도 낮은 중요도를 부여한다.
- 위 두 단계에 따라 두 가지 결과가 나온다.
- 첫째, 안정된 가중치는 훨씬 작아져 분산이 작아짐
- ml_1의 값이 낮고 금리가 낮은 포인트(그 반대도) 더 많은 중요도를 부여하는 것이 분명해짐
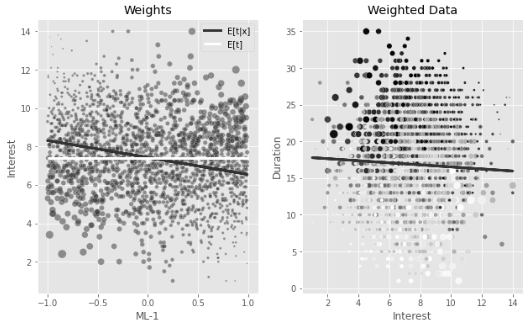
- 안정화 후, 왼쪽 그래프에서 가중치의 분포가 균일해짐을 확인할 수 있다.
- 또한 오른쪽 그래프에서 가중치를 적용한 데이터에서 T와 Y간의 관계가 더 명확해졌다.
안정화된 가중치로 ATE를 추정해보자
final_model = smf.wls("duration ~ interest",
data=df_cont_t, weights=gipw).fit()
final_model.params["interest"]
>> -0.7787046278134069
→ 실제 ATE인 -0.8에 더 가까운 추정값을 얻을 수 있다는 것을 확인할 수 있다.
→ 부트스트랩 함수로 95% 신뢰구간을 구한 결과도, 안정화 적용 후 신뢰구간이 훨씬 좁음을 알 수 있다,
* 모든 걸 직접 코딩할 필요 없이 패키지 causal_curve를 활용할 수 있다.
5.7 요약
회귀분석 및 직교화에 이어 편향을 보정하는 두 번째 핵심 방법인 역확률 가중치(IPW)에 대해 배웠다.
두 방법 모두 처치를 모델링해야 하며, 이는 인과추론 문제에서 처치 배정 메커니즘의 중요성을 보여줌
- 직교화: 처치를 잔차화하여, 처치 모델링에 사용된 공변량 X와 직교인 새로운 공간으로 투영
- IPW: 처치의 차원을 그대로 유지하면, 데이터를 처치 성향점수의 역수로 재조정
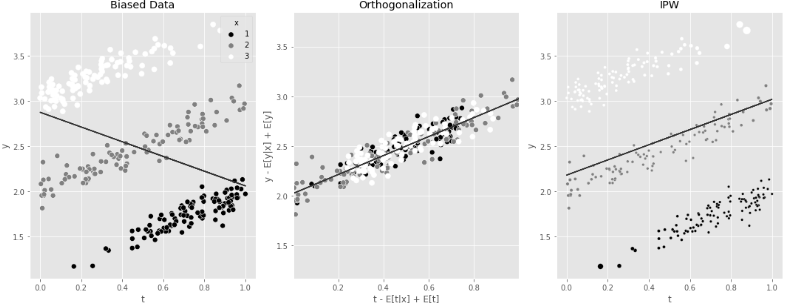
1. 왼쪽 그래프에서는 X에 따른 편향 때문에 기울기가 음수이다.
2. 가운데 그래프(직교화)는 공변량 X의 영향을 제거하기 위해서 T와 Y 각각에서 공변량의 조건부 기댓값을 빼고, 전체 데이터의 평균을 더해주는 방식이다. T와 Y간의 관계가 직선적이고 명확하게 나타난다.

3. 오른쪽 그래프(IPW)는 처치 모델을 사용하여 처치 받을 확률일 성향 점수를 계산하여 역수를 가중치로 주는 방식이다. '처치 값의 분포'가 조정되어, T와 Y간의 관계가 명확하게 드러난다.

그렇다면 어떤 방법을 선택해야할까? 일반적으로는,
- 이산형 처치일 때 - IPW + 이중 강건 접근법
- 연속형 처치일 때 - 회귀 모델링 (IPW는 처치 반응 함수에 대한 모수적 가정을 하지 않기 때문) 을 선택한다.
'데이터 분석 > 인과추론' 카테고리의 다른 글
| [7] 실무로 통하는 인과추론 with 파이썬 - 7장. 메타 러너 (0) | 2024.06.02 |
|---|---|
| [6] 실무로 통하는 인과추론 with 파이썬 - 6장. 이질적 처치효과 (0) | 2024.05.28 |
| [5-1] 실무로 통하는 인과추론 with 파이썬 - 5장. 성향점수 (0) | 2024.05.14 |
| [4-2] 실무로 통하는 인과추론 with 파이썬 - 4장. 유용한 선형회귀 (0) | 2024.05.12 |
| [4-1] 실무로 통하는 인과추론 with 파이썬 - 4장. 유용한 선형회귀 (0) | 2024.05.09 |



