
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 3기가 마지막이라니..!
- 부트 스트래핑
- lightgbm
- 인프런
- splitlines
- 캐글 신용카드 사기 검출
- 그룹 연산
- WITH CUBE
- 캐글 산탄데르 고객 만족 예측
- pmdarima
- 데이터 정합성
- 리프 중심 트리 분할
- 그로스 해킹
- DENSE_RANK()
- python
- tableau
- sql
- 데이터 증식
- 분석 패널
- XGBoost
- 그로스 마케팅
- WITH ROLLUP
- 스태킹 앙상블
- 마케팅 보다는 취준 강연 같다(?)
- ARIMA
- 데이터 핸들링
- 로그 변환
- Growth hacking
- 컨브넷
- ImageDateGenerator
- Today
- Total
LITTLE BY LITTLE
[1] 전처리&EDA 연습 - 캐글 Mall Customer Segmentation Data 본문
https://www.kaggle.com/datasets/vjchoudhary7/customer-segmentation-tutorial-in-python
Mall Customer Segmentation Data
Market Basket Analysis
www.kaggle.com
- Customer ID, age, gender, annual income, spending score과 같은 기본 정보만 있음
- 여기서 spending score은 customer behavior, purchasing data등에 기반해 매긴 점수
- 분석의 최종 목표는 "k-means clustering"기법으로 고객들을 segmentation 하는 것
참고
https://www.kaggle.com/code/gadigevishalsai/mall-customer-segmentation-clustering-analysis
Mall Customer Segmentation - Clustering + Analysis
Explore and run machine learning code with Kaggle Notebooks | Using data from Mall Customer Segmentation Data
www.kaggle.com

[Product] 내 눈에 안 보이는 고객 패턴 찾기
이전 섹션인 #2_ RFM Sementation 에서는 RFM value를 기준으로 RFM_score라는 것을 부여했고, 이 스코어를 기준으로 customer segmentation을 해보았습니다. 그렇지만 이런 방식의 segmentation은 분석가인 제가 분
velog.io

=> 검색해보고 제일 꼼꼼한 과정을 참고해서 따라해보았다.
Steps
- 결측치 처리 Drop and fill missing values
- 문자열 값 변환 (LabelEncoder() 객체 생성 OR 원-핫 인코딩)
- 특정 알고리즘 (EX.
선형 회귀)에서는 레이블 인코딩된 값에 가중치를 부여하여 예측 성능이 떨어질 수 있어 주의, 트리 계열 알고리즘에서는 사용해도 무관 - 원-핫 인코딩시,
- 문자열에서 숫자형으로 변환 먼저(LabelEncoder이용)한 후,
- 2차원 데이터로 변환(reshape(-1,1)) 한 후에
- OneHotEncoder() 객체 생성해서 변환 가능
- 혹은 pd.get_dummies() API 사용 가능 (위 단계 모두 생략 가능)
- 특정 알고리즘 (EX.
- 피처 스케일링(표준화, 정규화) - 서로 다른 변수의 값 범위를 일정 수준으로 맞춰주는 작업
- 표준화는 평균이 0, 분산이 1인 정규분포로 변환
- 순서
- StandScalers() 객체 생성
- fit()으로 데이터 변환을 위한 기준 정보 설정=> transform
- transform()은 설정된 정보를 통해 데이터를 반환
- 정규분포 변환은 몇몇 알고리즘에서 매우 중요 - SVM, 선형 회귀, 로지스틱 회귀
- MinMaxScaler() : 음수 값이 있으면 -1,과 1값으로 변환한다는 점이 다름, 데이터 분포가 가우시안 분포가 아닐 경우에 사용
- 주의해야할 점은 Scaler 객체를 이용해 학습 데이터셋으로 fit()과 transform()을 적용할 때 train data를 사용해야함 (test데이터는 훈련 과정에서 단 한번도 쓰이지 않음) => 따라서 test_array에 scale 변환시 fit() 호출
- 순서
- 정규화는 데이터 크기를 모두 같은 단위로 변경
- KMeans clustering시 변수들의 평균과 분산이 같아야한다.
- 표준화는 평균이 0, 분산이 1인 정규분포로 변환
- EDA
- EDA는 Summary statistics와 Graphical representations로 패턴을 찾고, 변칙을 발견, 가설을 테스트하는 것
- Feature Analysis
- 데이터 타입(df.info()), 결측치 여부 확인(df.isna().any()), Summary Statistics(df.describe()) 확인
- (결측치가 있을 경우, Visual representation of the missing data)
- 데이터 분포 확인
- 범주형 - df['Gender'].value_counts())
- 연속형 - diagnostic plots - 히스토그램, QQ플롯, 박스플롯 그려서 이상치여부/Skewness 확인
- Skewness있을시 manipulation(ex. log tranformation)필요
- 다른 변수와의 상관관계 시각화하여 확인
- 범주형 - Groupby()로 mean계산 후, barplot으로 시각화해서 확인
- 연속형 - sns.scatterplot()
- 데이터 타입(df.info()), 결측치 여부 확인(df.isna().any()), Summary Statistics(df.describe()) 확인
- Drop unnecessary columns & Detect and remove outliers in numerical data
- Manipulation
패키지 및 파일 불러오기, 피처 확인
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
pd.read_csv("/content/Mall_Customers.csv")[Out]

=> 5개의 피처,
- CustomerID (고객ID)
- Gender (성별)
- Age (나이)
- Annual Income (k$) (연간 수입)
- Spending Score (1-100) (지출 지수)
=> Shape은 (200,5)
df=pd.read_csv("/content/Mall_Customers.csv")
print(df.info())[Out]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200 entries, 0 to 199
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CustomerID 200 non-null int64
1 Gender 200 non-null object
2 Age 200 non-null int64
3 Annual Income (k$) 200 non-null int64
4 Spending Score (1-100) 200 non-null int64
dtypes: int64(4), object(1)
memory usage: 7.9+ KB
None=> dtype은 Gender 제외하고 모두 int64
df.isna().any()[Out]
CustomerID False
Gender False
Age False
Annual Income (k$) False
Spending Score (1-100) False
dtype: bool=> 다른 방법으로 결측치 여부 확인, 없다.
EDA (Exploratory Data Analysis)
Feature Analysis
import seaborn as sns
import scipy.stats as stats
# Numerical 컬럼들의 분포 그래프를 그려서 확인할 수 있는 함수 정의
def diagnostic_plots(df, variable):
plt.figure(figsize=(16,4))
# 히스토그램
plt.subplot(1,3,1)
sns.histplot(df[variable], bins=30)
plt.title('Histogram')
# Q-Q Plot
plt.subplot(1,3,2)
stats.probplot(df[variable], dist="norm", plot=plt)
# 박스 플롯
plt.subplot(1,3,3)
sns.boxplot(y=df[variable])
plt.title('Boxplot')
plt.show()1. Categorical Variable - Gender
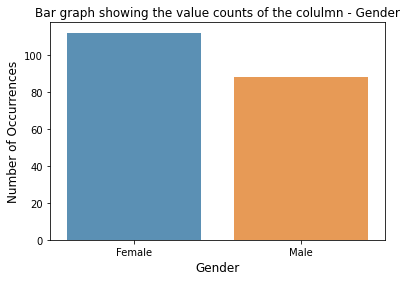
# 1. Categorical - Gender 컬럼 분포 확인
gender_count = df['Gender'].value_counts(dropna=False)
gender_count[Out]
Gender 값 분포 :
Female 112
Male 88
Name: Gender, dtype: int64# 위의 Gender컬럼의 분포를 보여주는 막대그래프 생성
sns.barplot(gender_count.index, gender_count.values, alpha=0.8)
plt.title('Bar graph showing the value counts of the colulmn - Gender')
plt.ylabel('Number of Occurrences', fontsize=12)
plt.xlabel('Gender', fontsize=12)
plt.show()
[Out]
1-1. Gender별 Average Income 확인 (성별별로 데이터 분포가 고르지 않기에 확인하는 것)
# Mean of Annual Income by Gender
gender_income = df[['Gender', 'Annual Income (k$)']].groupby('Gender', as_index=False).mean()
gender_income[Out]
Gender Annual Income (k$)
0 Female 59.250000
1 Male 62.227273# 위의 결과 시각화
sns.barplot(gender_income['Gender'], gender_income['Annual Income (k$)'],alpha=0.8)
plt.title('Annual Income By Gender')
plt.ylabel('Mean Annual Income', fontsize=12)
plt.xlabel('Gender', fontsize=12)
plt.show()[Out]

=> 평균 임금은 성별에 따라 차이가 없음을 알 수 있다.
1-2. Gender별 Spending Score 확인
# Mean Spending Score by Gender
gender_score = df[['Gender', 'Spending Score (1-100)']].groupby('Gender', as_index=False).mean()
gender_score[Out]
Gender Spending Score (1-100)
0 Female 51.526786
1 Male 48.511364# 위의 결과 시각화
sns.barplot(gender_score['Gender'], gender_score['Spending Score (1-100)'], alpha=0.8)
plt.title('Spending Score By Gender')
plt.ylabel('Mean Spending Score', fontsize=12)
plt.xlabel('Gender', fontsize=12)
plt.show()[Out]

=> 여성이 mean spending score이 남성보다 아주 조금 더 높다.
1-3. Gender별 Age 확인
# Mean Age By Gender
gender_age = df[['Gender', 'Age']].groupby('Gender', as_index=False).mean()
gender_age[Out]
Gender Age
0 Female 38.098214
1 Male 39.806818# 위의 결과 시각화
sns.barplot(gender_age['Gender'], gender_age['Age'], alpha=0.8)
plt.title('Mean Age By Gender')
plt.ylabel('Mean Age of the customer', fontsize=12)
plt.xlabel('Gender', fontsize=12)
plt.show()[Out]
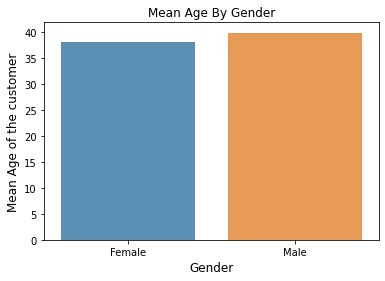
=> 남성이 여성 고객들보다 평균 나이가 아주 조금 더 높다.
2. Numerical Variable - Age
앞서 정의한 diagnostic_plots 함수 사용
# Age 컬럼의 분포 확인
diagnostic_plots(df, 'Age')[Out]
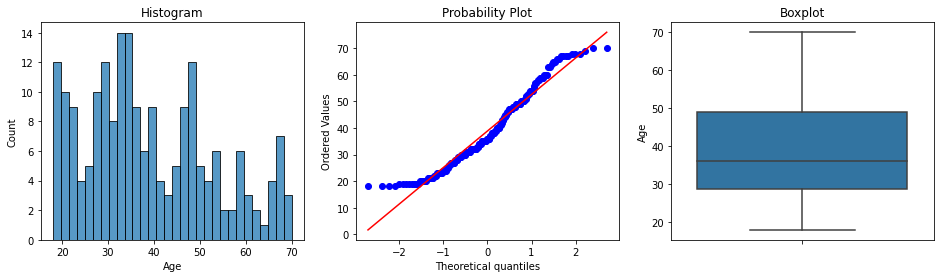
=> Data is slightly Skewed
=> Data has no Outliers
2-1. Age와 Annual Income 의 산점도를 그려보자 (hue=Gender)
# scatterplot btw Age and Annual Income
sns.scatterplot(data=df, x='Age', y='Annual Income (k$)', hue='Gender')[Out]
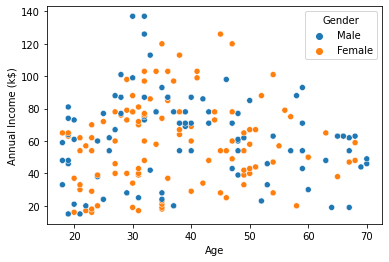
=> Age와 Annaul Income 사이에는 유의미한 관계가 없어보인다.
2-2. Age와 Spending Score 의 산점도를 그려보자 (hue=Gender)
# scatterplot btw Age and Spending Score
sns.scatterplot(data=df, x='Age', y='Spending Score (1-100)', hue='Gender')[Out]

=> Age와 Spending Score 사이에는 유의미한 관계가 없어보인다.
2. Numerical Variable - Annual Income
# Annaul Income 데이터 분포 확인
diagnostic_plots(df, 'Annual Income (k$)')[Out]

=> Data has a slight degree of Skewness
=> Data has a hint of an Outlier
3-1. Annual Income과 Spending Score 의 산점도를 그려보자 (hue=Gender)
# scatterplot btw Annual Income and Spending Score
sns.scatterplot(data=df, x='Annual Income (k$)', y='Spending Score (1-100)', hue='Gender')[Out]

=> 군집이 보인다. 후에 K-Means사용시 Annual Income과 Spending Score을 다시 볼 것
2. Numerical Variable - Spending Score
# Spending Score의 데이터 분포 확인
diagnostic_plots(df, 'Spending Score (1-100)')[Out]
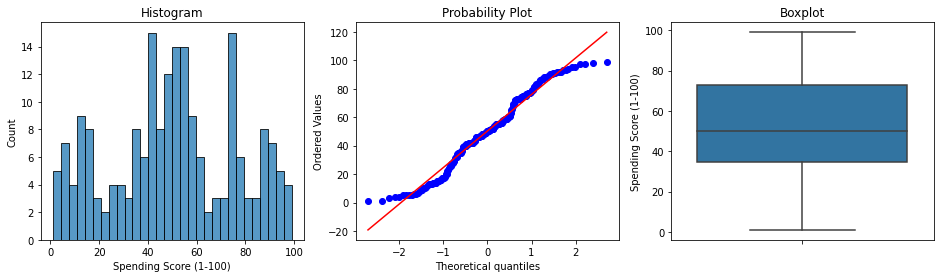
=> Data is slightly Skewed
=> Data has no outliers
feature anlysis 끝, data preprocessing 하기
(detect & remove outliers, drop unnecessory columns, drop and fill na)
def detect_outliers(df, n, features_list):
outlier_indices = []
for feature in features_list:
Q1 = np.percentile(df[feature], 25)
Q3 = np.percentile(df[feature], 75)
IQR = Q3 - Q1
outlier_step = 1.5 * IQR
outlier_list_col = df[(df[feature] < Q1 - outlier_step) | (df[feature] > Q3 + outlier_step)].index
outlier_indices.extend(outlier_list_col)
outlier_indices = Counter(outlier_indices)
multiple_outliers = list(key for key, value in outlier_indices.items() if value > n)
return multiple_outliers
outliers_to_drop = detect_outliers(df, 2, ['Age', 'Annual Income (k$)', 'Spending Score (1-100)'])
print("We will drop these {} indices: ".format(len(outliers_to_drop)), outliers_to_drop)[Out]
We will drop these 0 indices: []=> 아웃라이어가 없다.
결측치가 없기 때문에, counter column인 Customer ID만 삭제
# Drop the columns - CustomerId from the data
df.drop(['CustomerID'], axis=1, inplace=True)
df[Out]
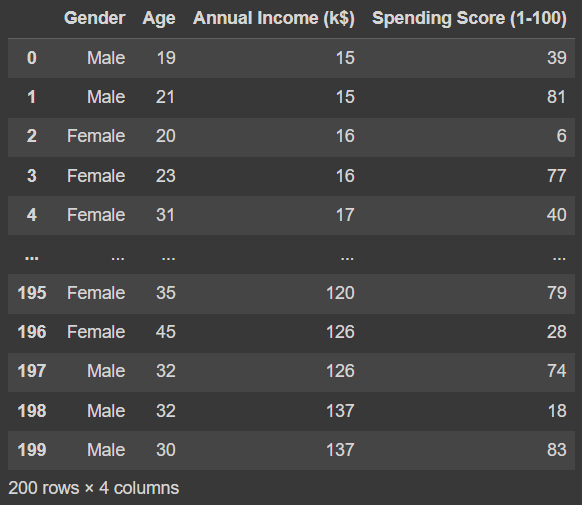
*참고
결측치 처리 함수 Fillna, 머신러닝 알고리즘에 불필요한 속성 제거 함수 drop_features, 레이블 인코딩 함수 format_features, 모든 함수 호출 함수 transform_features
(https://noelee.tistory.com/65?category=1294038)
# Null처리 함수 fillna
def fillna(df):
df['Age'].fillna(df['Age'].mean(), inplace=True)
df['Cabin'].fillna('N', inplace=True)
df['Fare'].fillna(0,inplace=True)
return df
# 머신러닝 알고리즘에 불필요한 속성 제거 함수 drop_features
def drop_features(df):
df.drop(['PassengerId','Name','Ticket'],axis=1, inplace=True)
return df
# 레이블 인코딩 함수 format_features
def format_features(df):
df['Cabin'] = df['Cabin'].str[:1]
features = ['Cabin', 'Sex', 'Embarked']
for feature in features:
le = LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
# 모든 함수 호출 함수 transform_features(df):
def transform_features(df):
df = fillna(df)
df = drop_features(df)
df = format_features(df)
return dfManipulation
위 칼럼들에게서 slight skewness가 발견되었기 대문에, log transformation으로 보정해주자.
(*log transformation을 하려면 변수들이 모두 0보다 커야한다.)
# Clustering에 필요한 Age, Anual Income, Spending Score 컬럼만 가지고 새로운 데이터프레임을 만들자.
df_cluster = df.iloc[:, 1:]
df_cluster.head()[Out]

import numpy as np
df_cluster_log = np.log(df_cluster)
sns.distplot(df_cluster_log['Age'])
plt.show()[Out]

sns.distplot(df_cluster_log['Annual Income (k$)'])
plt.show()[Out]

=> Age와 Annual_Income을 log transformation 해주었다. 조금 더 symmetric해짐
=> Spendign score은 로그변환시 더 skewed되어 하지x
Standardization
K-Means clustering을 하기 위한 조건 중 하나는 변수들의 평균과 분산이 같아야한다는 것
Numerical Variables들의 mean과 std 확인
df_cluster.describe()[Out]
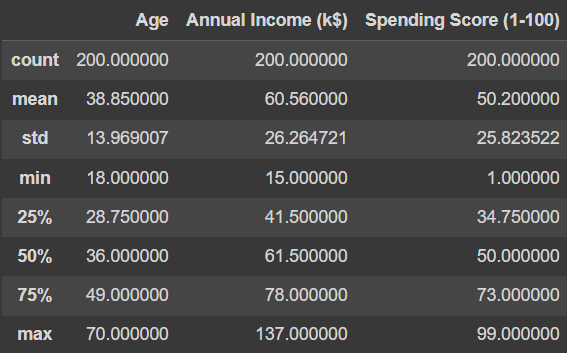
=> 정규화를 위해 scikit-learn 라이브러리의 StandardScaler() 함수 이용
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()scaler.fit(df_cluster_log)
df_scaled = scaler.transform(df_cluster_log)=> .fit 적용시 numpy array가 생성된다. transform 함수를 적용하여 df_scaled에 저장하였다.
# 정규화가 잘 되었는지 확인
print(df_scaled.mean(axis=0).round(2))
print(df_scaled.std(axis=0),round(2))[Out]
[ 0. -0. 0.]
[1. 1. 1.] 2=> mean이 0, std가 1으로 정규화가 잘 수행되었다.
https://noelee.tistory.com/65?category=1294038
[5] 파이썬 머신러닝 완벽가이드 - 사이킷런 데이터 전처리, 타이타닉 예제, 정리
*목차 파이썬 기반의 머신러닝과 생태계 이해 머신러닝의 개념 주요 패키지 넘파이 판다스 (데이터 핸들링) (39p) 정리 사이킷런으로 시작하는 머신러닝(87p) 사이킷런 소개 첫번째 머신러닝 만들
noelee.tistory.com
data prerpocessing 참고(▲)
k-means clustering 이어서 해보기
'데이터 분석 > 파이썬 Basic & EDA' 카테고리의 다른 글
| 시계열 데이터 Datetime / parse_dates / DatetimeIndex / Shift (0) | 2022.07.15 |
|---|---|
| 파이썬 기초 - 조건문, Numpy, Pandas (0) | 2022.07.15 |
| Pandas - apply method 활용 & 문자열 처리 기본 (0) | 2022.07.13 |
| Pandas - 그룹 연산 (0) | 2022.07.12 |

