
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Growth hacking
- tableau
- ARIMA
- ImageDateGenerator
- 분석 패널
- 그로스 마케팅
- lightgbm
- python
- splitlines
- WITH ROLLUP
- 데이터 정합성
- sql
- 마케팅 보다는 취준 강연 같다(?)
- WITH CUBE
- 리프 중심 트리 분할
- 인프런
- 로그 변환
- 캐글 산탄데르 고객 만족 예측
- 부트 스트래핑
- pmdarima
- 컨브넷
- 스태킹 앙상블
- 그룹 연산
- 캐글 신용카드 사기 검출
- 그로스 해킹
- DENSE_RANK()
- 데이터 증식
- 3기가 마지막이라니..!
- 데이터 핸들링
- XGBoost
- Today
- Total
LITTLE BY LITTLE
Pandas - apply method 활용 & 문자열 처리 기본 본문
apply 메소드
사용자가 작성한 함수를 한번에 적용하여 실행할 수 있게 해주는 메소드
함수를 브로드캐스팅할 때 사용
for문을 사용하는 것과 같은 결과 출력, 하지만 더 빠르다.
함수의 기본 구조
def my_function():
인자가 1개인 함수 my_sq(x)
def my_sq(x):
return x **2
print(my_sq(4))→ 16
인자가 2개인 함수 my_exp(x,n)
def my_exp(x,n):
return x**n
print(my_exp(2,4))→ 16
시리즈에 적용
apply 사용 x o 비교 (결과는 같음)
import pandas as pd
df = pd.DataFrame({'a':[10,20,30],'b':[20,30,40]})
print(df)
#apply 적용x
print(df['a']**2)
#인자가 1개인 함수 apply로 적용
sq = df['a'].apply(my_sq)
print(sq)
#인자가 2개인 함수 apply로 적용
ex = df['a'].apply(my_exp,n=2)
print(ex)
데이터 프레임에 적용
def print_me(x):
print(x)
# 데이터프레임에 함수를 적용할 때에는 열/행방향 정해주어야함
print(df.apply(print_me,axis=0))
def avg_3(x,y,z):
return (x+y+z)/3
→ 위처럼 만든 avg_3함수를 apply매소드에 전달할시 에러가 난다. 인자가 3개인데 1개의 인자로 인식했기 때문이다.
→ 열 단위로 데이터를 처리할 수 있게 수정해야한다.
# 열 단위로 데이터를 처리할 수 있도록 개선한 ave_3_apply 함수
def avg_3_apply(col):
x = col[0]
y = col[1]
z = col[2]
return (x+y+z) / 3
print(df.apply(avg_3_apply))
위의 예제에서는 데이터프레임의 개수가 3개인 것을 알고 있었지만,
일반적으로는 데이터프레임의 개수를 모르기 때문에 for문을 이용하여 이렇게 작성함
def avg_3_apply(col):
sum = 0
for item in col:
sum += item
return sum / df.shape[0]
# 행 방향으로 데이터를 처리하는 함수를 만들고 싶은 경우
def avg_2_apply(row):
sum = 0
for item in row:
sum += item
return sum / df.shape[1]
print(df.apply(avg_2_apply,axis=1))
seaborn 라이브러리의 titanic 데이터를 이용하여 실습
import seaborn as sns
titanic = sns.load_dataset("titanic")
titanic.info()
결측치 개수 구하는 함수 count_missing 만들기
import numpy as np
def count_missing(vec):
null_vec = pd.isnull(vec)
null_count = np.sum(null_vec)
return null_count
cmis_col = titanic.apply(count_missing)
print(cmis_col)
결측치 비율 계산 함수 prop_missing 만들기
def prop_missing(vec):
num = count_missing(vec)
dem = vec.size
return num / dem
cmis_col_p=titanic.apply(prop_missing)
print(cmis_col_p)
결측치가 아닌 데이터의 비율 계산함수 prop_complete 만들기
def prop_complete(vec):
return 1 - prop_missing(vec)
cmpl_col_p = titanic.apply(prop_complete)
print(cmpl_col_p)
행 방향으로 결측치 처리하기 (axis=1)
cmis_row = titanic.apply(count_missing,axis=1)
pmis_row = titanic.apply(prop_missing, axis=1)
pcom_row = titanic.apply(prop_complete,axis=1)
print(cmis_row.head())
print(pmis_row.head())
print(pcom_row.head())titanic['num_missing'] = titanic.apply(count_missing,axis=1)
print(titanic.head())
위처럼 데이터프레임에 결측치 개수 열을 추가하면, 결측치가 있는 데이터만 따로 볼 수 있다. 결측치가 2개 이상인 데이터만 추출해보기
print(titanic.loc[titanic.num_missing>1,:].sample(10))문자열 처리 기본
word = 'grail'
sent = 'a scratch'
#인덱싱
print(word)
print(word[0])
print(word[-5])#슬라이싱
print(sent[-9:-5])
print(sent[2:len(sent)])
문자열을 일정한 간격으로 건너뛰며 추출해야할 경우, 콜론(:)을 하나더 추가하여 추출 간격 지정 가능.
자신을 포함하여 거리가 2인 인덱스의 문자를 추출하면
print(sent[::2])
*문자열 메소드
- capitalize , count, startswith, endswith
- find 찾을 문자열의 첫번째 인덱스를 반환, 실패시 -1 반환
- index 위와 같은 역할, 실패시 ValueError 반환
- isalpha 모든 문자가 알파벳이면 참 , isdecimal , isalnum(알파벳이거나 숫자)
- lower, upper, replace,
- strip 문자열의 맨 앞, 맨뒤에 있는 빈칸 제거
- partition 위와 비슷하지만, 구분자(separator)도 반환
- center 지정한 너비로 문자열을 늘리고 문자열을 가운데 정렬
- zfill 문자열의 빈칸을 0 으로 채운다
적용 예시
"black Knight".capitalize() # 'Black knight'
"It's just a flesh wound!".count(u) # 2
"Halt! who goes there?".startswith('Halt') # True
"coconut".endswith('nut') # True
"It's just a flesh wound!".find('u') # 6
"It's just a flesh wound!".index('scratch') # valueError
"old woman".isalpha() # False
"37".isdecimal() # True
"flesh wound!".replace('flesh woound','scratch') # scratch!
" I'm not dead.".strip() # "I'm not dead."
"NI! NI! NI! NI!".split(sep=' ') # ['NI!','NI!','NI!','NI!']
"3,4".partition(',') ('3',',','4')
"nine".center(10) ' nine '
"9".zfill(5) # 00009
join / splitlines / replace 예시
join : 앞에 문자(' ') 를 지정하면 해당 문자를 단어 사이에 넣어 연결해준다.
d1 = '40'
m1 = "46'"
s1 = "52.837"
u1 = 'N'
d2 = '73'
m2 = "58'"
s2 = '26.302"'
u2 = 'W'
coords = ' '.join([d1,m1,s1,u1,d2,m2,s2,u2]) # 작음 따옴표 안의 문자를 단어 사이에 넣어 연결해줌
print(coords)
# 결과 : 40 46' 52.837 N 73 58' 26.302" W
splitlines : 여러 행을 가진 문자열을 분리한 후, 리스트로 반환한다.
splitlines 유무 결과 비교
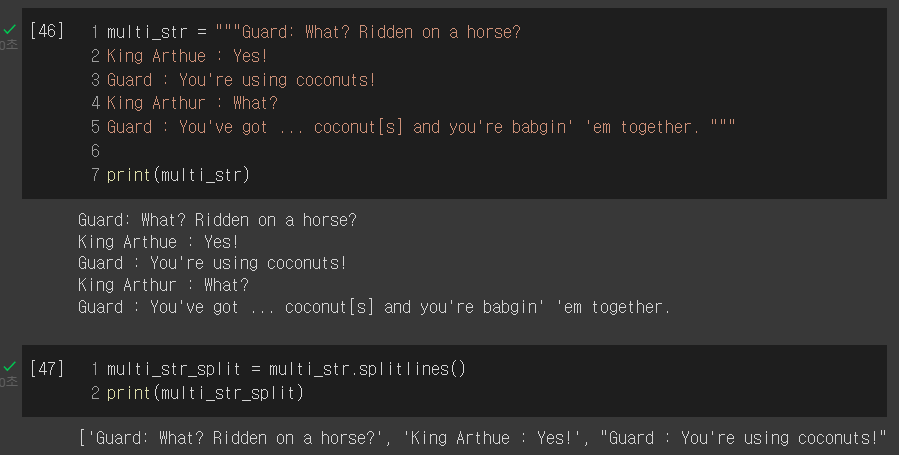
guard = multi_str_split[::2] # guard의 대사만 가져옴
print(guard)
replace : 문자열 치환
Guard의 대사에서 'Guard:'라는 문자열을 공백으로 대체하기
guard = multi_str.replace("Guard: ", "").splitlines()[::2]
print(guard)
문자열 포매팅 - format() 매소드
* {} 를 플레이스 홀더라고 부른다.
단어를 삽입할 위치를 {}로 지정하고, format 매소드에 원하는 단어를 전달하면 {}위치에 전달한 단어를 삽입해줌
var = 'flesh wound'
s = "It's just a {}!"
print(s.format(var))
print(s.format('scratch')){} 여러번 사용시, 인덱스를 사용
s = """Black Knight: 'This but a {0}. #플레이스 홀더를 여번 사용할 때, 인덱스 사용
King Arthur: A {0}? Yours arm's off!"""
print(s.format('scratch'))혹은 {} 안에 문자 입력해서 구분해도 된다.
s = 'Hayden Planetarium Coordinates: {lat},{lon}'
print(s.format(lat='40.7814 N',lon='73.9733 W'))# 숫자 데이터 포매팅
print ('Som digits of pi: {}'.format(3.14159265359)){} 안에 쉼표를 넣어 숫자를 표현할 수도 있다.
print("In 2005, Lu Chao of China receited {:,} digits of pi".format(67890))소수는 다양한 포매팅이 가능하다.
아래에서 0은 전달받을 값의 인덱스, .4는 소수점 이하의 숫자, %는 사용시 백분율로 환산하여 출력해준다.
print ("I remember {0:.4} or {0:4%} of what Lu Chao recited".format(7/67890))% 연산자로 포매팅하기
s = 'I only know %d digits of pi' %7
print(s)문자열은 %s
print('Some digits of %(cont)s: %(value).2f' % {'cont':'e','value':2.718})정규식
*정규식 표현 매소드
- search : 첫번째로 찾은 패턴의 양 끝 인덱스 반환
- match : 문자열의 처음부터 검색하여 찾아낸 패턴의 양 끝 인덱스 반환
- fullmatch : 전체 문자열이 일치하는지 검사
- split : 지정한 패턴으로 잘라낸 문자열을 리스트로 반환
- findall : 지정한 패턴으로 찾아 리스트로 반환
- finditer : findall 메소드와 기능은 동일하지만 iterator를 반환
- sub : 첫 번째로 전달한 패턴을 두 번째 인자로 전달한 값으로 교체
import re
tele_num = '12345678890'
m = re.match(pattern='\d\d\d\d\d\d\d\d\d\d',string = tele_num)
print(type(m))
# 패턴을 찾으면 Match 오브젝트를 반환한다.
print(bool(m))
# Match 오브젝트는 bool메소드로 True,False 판단 가능
if m:
print('match')
else:
print('no match')
print(m.start()) #0
print(m.end()) #10
print(m.span()) #(0,10)
print(m.group()) #1234567889
전화번호 입력을 위처럼 이어서 하지 않고, 띄어쓰거나 바(-)로 구분하여 입력하였을 경우, 기존의 패턴과 다르게 인식하여 None을 출력한다.
tele_num_spaces = '123 456 7890'
m = re.match(pattern = '\d{10}',string = tele_num_spaces)
print(m) # None
if m:
print('match')
else:
print('no match') # no match
위의 문제 해결을 위해 정규식을 다시 작성.
빈칸을 의미하는 정규식 \s? 를 이용하였다.
p = '\d{3}\s?\d{3}\s?\d{4}'
m = re.match(pattern = p, string = tele_num_spaces)
print(m)
또 번호가 (123) 456-7890 의 형식인 경우에는
tele_num_space_paren_dash = '(123) 456-7890'
p = '\(?\d{3}\)?\s\d{3}\s?-?\d{4}'
m = re.match(pattern = p, string = tele_num_space_paren_dash)
print(m)
또는 +1 (123) 456-7890 의 형식일 경우
cnty_tele_num_space_paren_dash = '+1 (123) 456-7890'
p = '\+1\s?\(?\d{3}\)?\s?\d{3}\s?-?\d{4}'
m = re.match(pattern=p,string=cnty_tele_num_space_paren_dash)
print(m)
compile 메소드 & 정규식
패턴을 반복해서 사용하려면 패턴을 compile 한 다음, 변수에 저장하여 사용하자.
p = re.compile('\d{10}')
s = '1234567890'
m = p.match(s)
print(m)
'데이터 분석 > 파이썬 Basic & EDA' 카테고리의 다른 글
| [1] 전처리&EDA 연습 - 캐글 Mall Customer Segmentation Data (1) | 2022.09.12 |
|---|---|
| 시계열 데이터 Datetime / parse_dates / DatetimeIndex / Shift (0) | 2022.07.15 |
| 파이썬 기초 - 조건문, Numpy, Pandas (0) | 2022.07.15 |
| Pandas - 그룹 연산 (0) | 2022.07.12 |

