
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- ARIMA
- XGBoost
- tableau
- 스태킹 앙상블
- splitlines
- 로그 변환
- 분석 패널
- 그룹 연산
- Growth hacking
- ImageDateGenerator
- sql
- 그로스 해킹
- 리프 중심 트리 분할
- 인프런
- 3기가 마지막이라니..!
- WITH CUBE
- DENSE_RANK()
- pmdarima
- WITH ROLLUP
- 캐글 산탄데르 고객 만족 예측
- lightgbm
- 데이터 증식
- 그로스 마케팅
- 컨브넷
- python
- 부트 스트래핑
- 마케팅 보다는 취준 강연 같다(?)
- 캐글 신용카드 사기 검출
- 데이터 정합성
- 데이터 핸들링
- Today
- Total
LITTLE BY LITTLE
[5] 데이터 가공을 위한 SQL - 여러 개의 테이블에 대한 조작 : union all, left join, 상관 서브 쿼리, cte (with구문), values, generate_series 본문
[5] 데이터 가공을 위한 SQL - 여러 개의 테이블에 대한 조작 : union all, left join, 상관 서브 쿼리, cte (with구문), values, generate_series
위나 2024. 1. 20. 15:25
목차
3. 데이터 가공을 위한 SQL
3-1. 하나의 값 조작하기 (5강) 3-2. 여러 개의 값에 대한 조작 (6강) 3-3. 하나의 테이블에 대한 조작 (7강)
3-4. 여러 개의 테이블 조작하기 (8강)
4. 매출을 파악하기 위한 데이터 추출
4-1. 시계열 기반으로 데이터 집계하기
4-2. 다면적인 축을 사용해 데이터 집약하기
5. 사용자를 파악하기 위한 데이터 추출
5-1. 사용자 전체의 특징과 경향 찾기
5-2. 시계열에 따른 사용자 전체의 상태 변화 찾기
5-3. 시계열에 따른 사용자의 개별적인 행동 분석하기
6. 웹사이트에서 행동을 파악하는 데이터 추출하기
6-1. 사이트 전체의 특징/경향 찾기
6-2. 사이트 내의 사용자 행동 파악하기
6-3. 입력 양식 최적화하기
7. 데이터 활용의 정밀도를 높이는 분석 기술
7-1. 데이터를 조합해서 새로운 데이터 만들기
7-2. 이상값 검출하기
7-3. 데이터 중복 검출하기
7-4. 여러 개의 데이터셋 비교하기
8. 데이터를 무기로 삼기 위한 분석 기술
8-1. 검색 기능 평가하기
8-2. 데이터 마이닝
8-3. 추천
8-4. 점수 계산하기
9. 지식을 행동으로 옮기기
9-1. 데이터 활용의 현장
3장 - 8강. 여러 개의 테이블에 대한 조작
여러 개의 테이블을 조작할 때 SQL을 간단하고 가독성 높게 작성하는 방법과, 부족한 데이터를 보완하는 방법
업무 데이터를 사용하는 경우 (RDB)
- RDB: 데이터를 정규화하고, 여러 테이블로 나누어서 데이터를 관리한다
- 이러한 RDB에서 관리되는 데이터이기에, 여러 테이블을 기반으로 정보를 추출해야하는 경우가 많음
로그 데이터를 사용하는 경우
- 하나의 테이블에 저장된 로그 파일 일 때에는, 자기 결합해서 레코드들을 비교해야 한다.
- 테이블이 하나라도, 여러 테이블을 다루는 것처럼 처리해야 하는 경우도 있음
8-1. 여러 개의 테이블을 세로로 결합하기
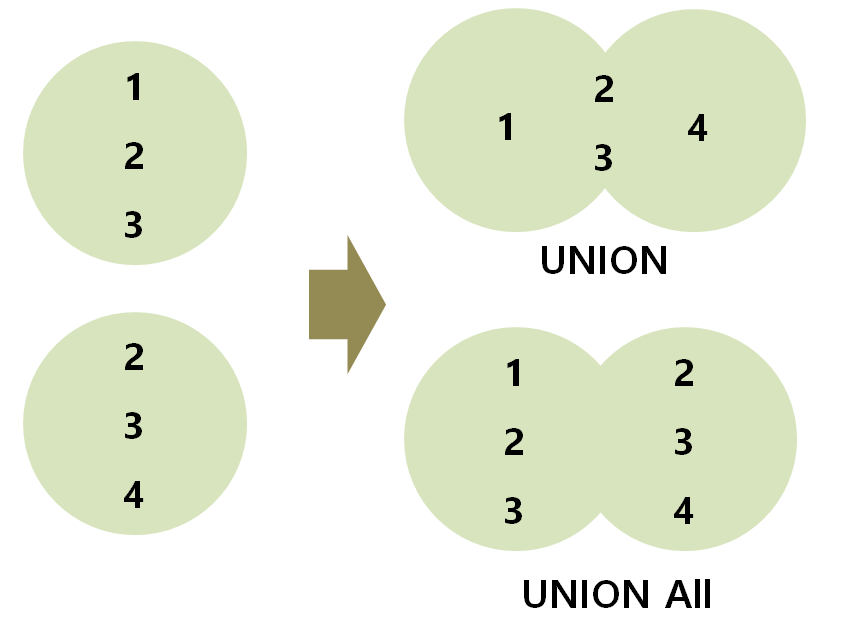
union all 구문

UNION ALL()
비슷한 구조를 가진 테이블의 데이터를 일괄 처리할 때 사용
- 결합 시 컬럼이 완전히 일치해야 한다.
- 따라서 한쪽에만 존재하는 컬럼은 1) SELECT 구문으로 제외하거나, 2) 디폴트 값을 줘야 함
- UNION ALL과 유사한 UNION (DISTINCT) 구문을 사용하면, 데이터의 중복을 제외한 결과를 얻을 수 있으나, 자주 사용되지 않고 계산 비용이 많이 들어간다고 함
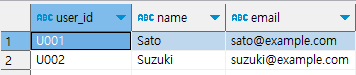
select 'app1' as app_name, user_id, name, email from app1_mst_users
union all
select 'app2' as app_name, user_id, name, null as email from app2_mst_users;※ app2에만 존재하는 phone 컬럼을 select하지 않고, 존재하지 않는 email 컬럼은 null as email 로 공통된 컬럼을 추가해줌

8-2. 여러 개의 테이블을 가로로 정렬하기
left join, 상관 서브 쿼리


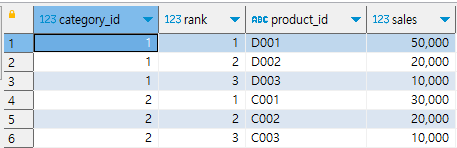
카테고리 별 마스터 테이블(1번)에 매출/순위 데이터(2,3번)를 기반으로 카테고리 별 가장 잘 팔리는 상품 ID 출력하기
JOIN()
SELECT <Columns> FROM <Table1> JOIN <Table2> ON <Condition> WHERE ~
- 가로 정렬 시 일반적으로 사용하는 방법
- 주의할 점 - 마스터 테이블에 join 사용 시 결합하지 못한 데이터가 사라지거나, 반대로 중복된 데이터가 발생할 수 있다.
m,s,r의 공통 컬럼 상품id를 기준으로 세 테이블 조인하기
(master 테이블에 sales, ranking 정보 추가하기)
m - master
s - sales
r - ranking
select
m.category_id
, m.name
, s.sales
, r.product_id as sales_product
from
mst_categories as m
join
-- 카테고리 별 매출액 결합
category_sales as s
on m.category_id = s.category_id
join
-- 카테고리 별로 상품 결합
product_sale_ranking as r
on m.category_id = r.category_id;(inner) join
↕
left join
*rank가 1위인 상품만 추출하는 조건 추가
select
m.category_id,
m.name,
s.sales,
r.product_id as top_sale_product
from
mst_categories as m
-- left join 사용하여, 결합한 레코드 남기기
left join
-- 카테고리 별 매출액 결합하기
category_sales as s
on m.category_id = s.category_id
-- left join 사용하여, 결합하지 못한 레코드 남기기
left join
-- 카테고리별 최고 매출 상품 하나만 추출해서 결합
product_sale_ranking as r
on m.category_id = r.category_id
and r.rank = 1;

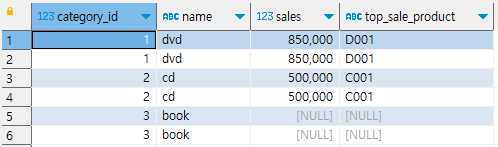
상관 서브 쿼리
- 데이터의 중복, 누락을 피하고 마스터 테이블의 행 수가 변하지 않는 left join과 동일한 결과 출력
- 부모 명령과 자식인 서브쿼리가 특정 관계를 맺는 것
- 내부에서 order by 구문과 limit 구문을 사용하면 사전 처리를 하지 않고도 데이터를 하나로 압축할 수 있다.
select
m.category_id,
m.name,
-- 상관 서브쿼리로 카테고리 별 sales 추출
(select s.sales
from category_sales as s
where m.category_id = s.category_id
) as sales,
-- 상관서브쿼리로 카테고리 별 최고 매출 상품 1개 추출 (순위 추출 불필요)
(select r.product_id
from product_sale_ranking as r
where m.category_id = r.category_id
order by sales desc
limit 1
) as top_sale_product
from mst_categories as m;
8-3. 조건 플래그를 0과 1로 표현하기
case 식, sign 함수
사용자 마스터 테이블에 구매 로그 테이블을 결합해서 '구매 이력 여부' 등을 0과 1로 표현하기
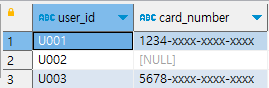

사용자 마스터에 구매 로그 정보 결합하고, 조건 플래스를 0,1로 변환하기
case 식과 sign 함수 사용
case when 식 - null이 아니면 1, null이면 0으로 표현
sign 함수 - user id count개수가 1개 이상이면 1으로, 0이면 0으로 표현
select
m.user_id,
m.card_number,
count(p.user_id) as purchase_count,
-- 신용카드 번호 등록 시 1, 등록 안했을 시 0으로 표현
case when m.card_number is not null then 1 else 0 end as has_card,
-- 구매 이력이 있는 경우 1, 없는 경우 0으로 표현
sign(count(p.user_id)) as has_purchased
from
mst_users_with_card_number as m
left join
new_purchase_log as p
on m.user_id = p.user_id
group by m.user_id, m.card_number;
※ 특정 조건을 만족하는지 플래그로 나타내는 방법은 벤다이어그램(11강 5절)이나 복잡한 조건을 충족하는 비율 (12강 2절) 등 다양한 분석에 활용할 수 있다.
8-4. 계산한 테이블에 이름 붙여 재사용하기
cte(with 구문)
복잡한 처리를 하는 sql문 작성 시 서브 쿼리의 중첩이 많아진다. 이런 경우 공통 테이블식(CTE, Common Table Expression)을 사용하면 가독성이 크게 높아진다.
카테고리 별 상품 매출 정보(product_sale)로 순위를 가로로 전개하고, 카테고리 별 매출 순위를 한 번에 볼 수 있는 형식으로 변환하기

CTE 구문
WITH <테이블 이름> AS (SELECT ~)
row number(윈도 함수) - 카테고리 별 순위 계산하기
join - 가로로 전개하기
계산한 테이블 product_sale_ranking 만들기
with
product_sale_ranking as (
select
category_name,
product_id,
sales,
row_number() over (partition by category_name order by sales desc) as rank
from product_sales)
select *
from product_sale_ranking;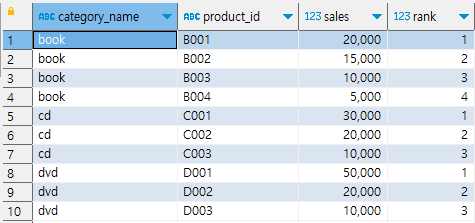
계산한 테이블 product_sale_ranking을 자기결합해서 카테고리 수만큼 넓게 펼치기
- 카테고리 별 상품 수가 다르기에, 최대 상품 수에 맞는 결과를 계산할 수 있도록 순위의 고유한 목록 계산하기
with
product_sale_ranking as (
--- 앞의 쿼리와 동일한 부분
with
product_sale_ranking as (
select
category_name,
product_id,
sales,
row_number() over (partition by category_name order by sales desc) as rank
from product_sales)
select *
from product_sale_ranking),
--- 앞의 쿼리와 동일한 부분 end
mst_rank as (
select distinct rank
from product_sale_ranking)
select * from mst_rank;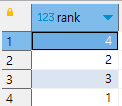
--- 앞의 쿼리와 동일한 부분
with product_sale_ranking as (
select
category_name,
product_id,
sales,
row_number() over (partition by category_name order by sales desc) as rank
from product_sales),
mst_rank as (
select distinct rank
from product_sale_ranking)
--- 앞의 쿼리와 동일한 부분 end
select
m.rank,
r1.product_id as dvd,
r1.sales as dvd_sales,
r2.product_id as cd,
r2.sales as cd_sales,
r3.product_id as book,
r3.sales as book_sales
from mst_rank as m
left join
product_sale_ranking as r1
on m.rank = r1.rank
and r1.category_name = 'dvd'
left join
product_sale_ranking as r2
on m.rank = r2.rank
and r2.category_name = 'cd'
left join
product_sale_ranking as r3
on m.rank = r3.rank
and r3.category_name = 'book'
order by m.rank;
※ 위 쿼리를 cte를 사용하지 않고, row_number로 순위를 계산하는 처리를 여러 번 작성했다면, 가독성이 굉장히 떨어졌을 것
※ 만약 일시 테이블이 많이 사용된다면, 물리적인 테이블로 저장하는 것이 재사용 측면과 성능 측면에서 모두 좋다. 하지만 만들 수 있는 권한이 없는 경우가 많기에, 권한이 없다면 cte를 사용하여 일시 테이블을 활용해야 함
8-5. 유사 테이블 만들기
union all 구문, values 구문, explode 함수, generate_series 함수
테이블 생성 권한이 없는 경우, 유사 테이블을 통해서 테스트와 작업 효율을 크게 향상 시킬 수 있다.
임의의 레코드를 가진 유사 테이블 만들기
with
mst_devices as (
select 1 as device_id, 'PC' as device_name
union all select 2 as device_id, 'SP' as device_name
union all select 3 as device_id, '애플리케이션' as device_name)
select * from mst_devices;
user_id의 register_device 컬럼을 공통으로 left join
-- 앞 쿼리와 동일
with
mst_devices as(
select 1 as device_id, 'PC' as device_name
union all select 2 as device_id, 'SP' as device_name
union all select 3 as device_id, '애플리케이션' as device_name)
-- 앞 쿼리와 동일 end
select u.user_id,
d.device_name
from
mst_users as u
left join
mst_devices as d
on u.register_device = d.device_id;

VALUES 구문을 사용한 유사 테이블 만들기
<PostgreSQL>
INSERT 이외에도 VALUES 구문으로 레코드를 만들 수 있다.
with
mst_devices(device_id, device_name) as (
values
(1, 'PC')
, (2, 'SP')
, (3, '애플리케이션')
)
select * from mst_devices;
배열형 테이블 함수를 사용한 유사 테이블 만들기
<Hive, SparkSQL>
EXPLODE ()
= unnest와 유사
: array를 입력받아, array의 각 요소에 대한 행이 한 개씩 포함된 테이블을 리턴
※ Array
<Big Query>
- 데이터 유형이 동일한 값으로 구성된 목록을 배열이라 함
- 하나의 행에 type이 동일한 여러 값이 저장
- [ ] 대괄호, array(), generate_array(start, end, step), array_agg(<-table) 으로 array 생성
모든 데이터를 같은 자료형으로 정의하고, 컬럼 값을 배열로 정의하기
with
mst_devices as (
select
-- 배열을 열로 전개하기
d[0] as device_id,
d[1] as device_name
from
-- 배열을 테이블로 전개하기
(select explode(
array(
array('1','PC'),
array('2','SP'),
array('3','애플리케이션')
))d
) AS t
)
select * from mst_devices;
map 자료형을 사용하기
with
mst_devices as (
select
-- map 자료형의 데이터를 열로 전개하기
d['device_id'] as device_id,
d['device_name'] as device_name
from
-- 배열을 테이블로 전개하기
(select explode(
array(
map('device_id','1','device_name','PC'),
map('device_id','2','device_name','SP'),
map('device_id','3','device_name','애플리케이션')
))d
) AS t
)
select * from mst_devices;순번을 사용해 임의의 레코드 수를 가진 유사 테이블 작성하기
< PostgreSQL, BigQuery >
- 지금까지는 레코드를 직접 정의해서 유사 테이블을 작성했으나, 레코드 수가 다르면 작성이 귀찮아짐
- 자동으로 순번을 생성하는 테이블 함수로 임의의 레코드 수를 가진 유사 테이블을 만들 수 있다.
GENERATE_SERIES()
: 자동으로 순번을 생성해주는 함수
- BigQuery → generate_array()
with
series as(
-- 1~5까지의 순번 생성
select generate_series(1,5) as idx
)
select * from series;
Hive, SparkSQL의 경우
지정 문자열을 n번 반복하는 repeat 함수와 split 함수를 조합해서 explode로 전개하기
select
row_number() over(order by x) as idx
from
-- repeat 함수와 split 함수를 조합해서 임의의 길이를 가진 배열 생성, explode로 전개
(select explode(split(repeat('x',5-1),'x')) as x) as t;



