
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- WITH CUBE
- 캐글 신용카드 사기 검출
- python
- tableau
- Growth hacking
- 캐글 산탄데르 고객 만족 예측
- 스태킹 앙상블
- lightgbm
- 그로스 해킹
- ImageDateGenerator
- 부트 스트래핑
- 그룹 연산
- XGBoost
- 로그 변환
- 데이터 핸들링
- sql
- ARIMA
- 3기가 마지막이라니..!
- 인프런
- 리프 중심 트리 분할
- 마케팅 보다는 취준 강연 같다(?)
- splitlines
- DENSE_RANK()
- 컨브넷
- 분석 패널
- 데이터 정합성
- 그로스 마케팅
- pmdarima
- 데이터 증식
- WITH ROLLUP
- Today
- Total
LITTLE BY LITTLE
[3] 데이터 가공을 위한 SQL - 여러 개의 값에 대한 조작 : concat, sign, greatest, nullif, point, <->, age, inet, <<, lpad 본문
[3] 데이터 가공을 위한 SQL - 여러 개의 값에 대한 조작 : concat, sign, greatest, nullif, point, <->, age, inet, <<, lpad
위나 2024. 1. 10. 23:03

목차
3. 데이터 가공을 위한 SQL
3-1. 하나의 값 조작하기 (5강)
3-2. 여러 개의 값에 대한 조작 (6강)
3-3. 하나의 테이블에 대한 조작 (7강)
4. 매출을 파악하기 위한 데이터 추출
4-1. 시계열 기반으로 데이터 집계하기
4-2. 다면적인 축을 사용해 데이터 집약하기
5. 사용자를 파악하기 위한 데이터 추출
5-1. 사용자 전체의 특징과 경향 찾기
5-2. 시계열에 따른 사용자 전체의 상태 변화 찾기
5-3. 시계열에 따른 사용자의 개별적인 행동 분석하기
6. 웹사이트에서 행동을 파악하는 데이터 추출하기
6-1. 사이트 전체의 특징/경향 찾기
6-2. 사이트 내의 사용자 행동 파악하기
6-3. 입력 양식 최적화하기
7. 데이터 활용의 정밀도를 높이는 분석 기술
7-1. 데이터를 조합해서 새로운 데이터 만들기
7-2. 이상값 검출하기
7-3. 데이터 중복 검출하기
7-4. 여러 개의 데이터셋 비교하기
8. 데이터를 무기로 삼기 위한 분석 기술
8-1. 검색 기능 평가하기
8-2. 데이터 마이닝
8-3. 추천
8-4. 점수 계산하기
9. 지식을 행동으로 옮기기
9-1. 데이터 활용의 현장
3장 - 6강. 여러 개의 값에 대한 조작
새로운 지표 정의하기
6-1. 문자열 연결하기
(CONCAT 함수,|| 연산자)
mst_user_location table 생성
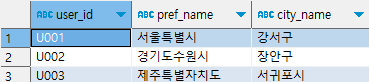
시도와 시군구를 한 문자열로 만들기
1. concat ([컬럼명],[컬럼명2]..) as 새 컬럼명
2. [컬럼명] || [컬럼명2] as 새 컬럼명
select user_id,
concat(pref_name,' ', city_name) as pref_city,
pref_name || ' ' || city_name as pref_city_2 --위와 같은 결과 출력
from mst_user_location;
6-2. 여러 개의 값 비교하기
(case 식, sign 함수, greatest 함수, least 함수, 사칙 연산자)
table quarterly_sales 생성

분기별 매출 증감 판정하기
1. case식을 통해서 컬럼의 크고 작음 비교하기
2. sign함수를 통해서 매개변수가 양수라면 1, 0이라면 0, 음수라면 -1을 리턴하도록 하기
※ 하나의 레코드에 있는 값으로는 다음과 같은 식으로 비교가 가능하지만, 작년 4분기와 올해 1분기를 비교하고자 할 때(여러 레코드에 걸쳐 있는 값을 비교할 때)에는 여러 레코드에 조합해야 한다.(7강)
select year, q1, q2,
-- Q1과 Q2 매출 변화 평가
case when q1<q2 then '+'
when q1=q2 then ' '
else '-'
end as judge_q1_q2,
-- Q1과 Q2 매출액 차이 계산
q1-q1 as diff_q2_q1,
-- Q1과 Q2 매출 변화를 1,0,-1로 표현
sign(q2-q1) as sign_q2_q1
from quarterly_sales order by year;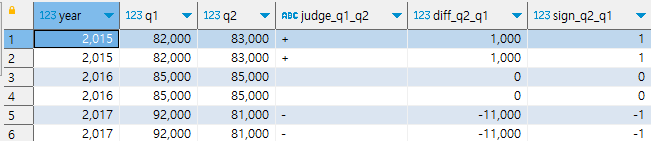
연간 최대/최소 4분기 매출 찾기
원본 테이블 quareterly_sales

greatest (as), least (as) 함수
-- 연간 최대/최소 4분기 매출 찾기
select cast(year as varchar) as year, --year에 쉼표 붙은거 거슬려서 문자형으로 select..
greatest(q1,q2,q3,q4) as greatest_sales,
least(q1,q2,q3,q4) as least_sales
from quarterly_sales
order by year;
연간 평균 4분기 매출 계산하기
-- 연간 평균 4분기 매출 계산하기
select cast(year as varchar) as year,
(q1+q2+q3+q4)/4 as average
from quarterly_sales
order by year;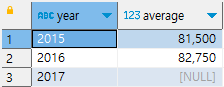
coalesce함수로 null을 0으로 변환하고 평균 구하기
--coalesce를 사용해 null값을 0으로 변환하고 평균값 구하기
select cast(year as varchar) as year,
(coalesce(q1,0)+coalesce(q2,0)+coalesce(q3,0)+coalesce(q4,0))/4 as average
from quarterly_sales
order by year;
분모 계산에서도 null값은 제외하여 평균값 구하기
분모에 포함되는 데이터 개수를 계산할 때, sign함수로 null이면 0을 리턴하는 값이 0이면 0으로 계산(제외)
--null값은 아예 제외하고 평균값 구하기
select year,
(coalesce(q1,0)+coalesce(q2,0)+coalesce(q3,0)+coalesce(q4,0))
/ (sign(coalesce(q1,0))+sign(coalesce(q2,0))+sign(coalesce(q3,0))+sign(coalesce(q4,0))) as average
from quareterly_sales
order by year;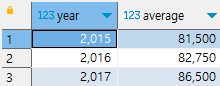
6-3. 2개의 값 비율 계산하기
(나눗셈, CAST 구문, CAST 식, NULLIF 함수)
table advertising_stats 생성

정수 자료형의 데이터 나누기
: CTR(Click Through Rate, 클릭/노출수) 구하기
※ PostgreSQL에서 정수 자료형끼리 연산 시, 결괏값도 정수 자료형이 되어버려 0이 되기 때문에, CAST함수로 형식을 double precision 자료형으로 변환하고 계산해야 한다.
※ % 계산 시 100이 아닌 100.0을 (앞에 두고) 곱하면, 자료형 변환이 자동으로 이루어져 편하다.
select dt, ad_id,
cast(clicks as double precision) / impressions as ctr,
-- 실수를 상수로 앞에 두고 계산 시, 암묵적 자료형 변환이 일어나 쿼리가 간단해짐
100.0 * clicks / impressions as ctr_as_percent
from advertising_stats
where dt='2017-04-01'
order by dt, ad_id;
0으로 나누는 것 피하기
1. case식을 사용해 값이 0인지 확인하기
2. null전파 사용하기 - null 전파란, null을 포함한 데이터의 연산 결과가 모두 null이 되는 sql의 성질
NULLIF(표현식1,표현식2) : 표현식1이 표현식2와 같으면, NULL을, 같지 않으면 표현식1을 반환
-- 1번 방법. case 식 이용하기
select dt, ad_id,
case when impressions > 0 then 100.0 * clicks / impressions
end as ctr_as_percent_by_case
from advertising_stats
order by dt, ad_id;-- 2번 방법. nullif 이용하기
select dt, ad_id
, 100.0 * clicks / nullif(impressions,0) as ctr_as_percent_by_null
from advertising_stats
order by dt, ad_id;
6-4. 두 값의 거리 계산하기
(abs함수, power 함수, sqrt함수, point 자료형, <-> 연산자)
- 평균과 떨어진 거리, 작년 매출과 올해 매출에 어느정도의 차이가 있는지, 특정 사용자와 구매 경향이 비슷한 사용자를 뽑는 경우 등 데이터 분석에서 거리라는 개념이 굉장히 중요하게 작용한다.
- 또한, 거리 계산은 7장(유사도 계산)과 8장(추천 구현)의 기초가 되는 개념이다.
숫자 데이터의 절댓값, 제곱 평균 제곱근(RMS) 계산하기
table location_1d 생성
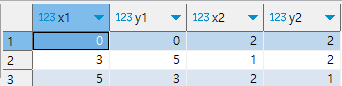
ABS () - 절대값 계산
POWER () - 제곱
SQRT () - 제곱근 구할 때
-- 일차원 데이터의 절대값과 제곱 평균 제곱근 (같은 결과를 내는 두 식) 계산
select abs(x1-x2) as abs
, sqrt(power(x1-x2,2)) as rms
from location_1d;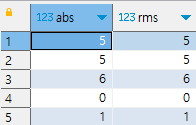
xy 평면 위에 있는 두 점의 유클리드 거리 계산하기
table location_2d 생성

1. 두 점 (x1,y1)과 (x2,y2) 사이의 유클리드 거리 계산
2. PostgreSQL에서는 POINT 자료형이라고 불리는 좌표를 다루는 자료구조가 존재하여, 이 자료형으로 변환하고 거리 연산자 <->를 사용하면 같은 결과를 얻을 수 있음
select
sqrt(power(x1-x2,2) + power(y1-y2,2)) as dist,
point(x1,y1) <-> point(x2,y2) as dist2
from location_2d;
6-5. 날짜/시간 계산하기
(interval 자료형, 날짜/시간 함수)
interval 자료형: 특정 시간 간격, 날짜나 시간을 더하거나 뺄 때 사용되는 데이터 타입
table mst_users_with_dates 생성
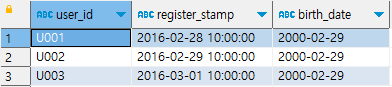
미래/과거 날짜/시간 계산하기
-- 미래 또는 과거의 날짜/시간 계산
select user_id,
-- PostgreSQL은 interval 자료형의 데이터에 사칙연산 적용
register_stamp::timestamp as regiester_stamp,
register_stamp::timestamp + '1 hour'::interval as after_1_hour,
register_stamp::timestamp + '30 minutes'::interval as before_30_minutes,
register_stamp::date as register_date,
(register_stamp::date + '1 day'::interval)::date as after_1_day,
(register_stamp::date - '1 month'::interval)::date as after_1_month
from mst_users_with_dates;
날짜 데이터들의 차이 계산하기
※ PostgreSQL(+Redshift)의 경우 날짜 자료형끼리 뺄 수 있다. (다른 미들웨어는 별도의 함수 datediff사용)
-- 두 날짜의 차이 계산
select user_id,
current_date as today,
register_stamp::date as register_date,
current_date - register_stamp::date as diff_days
from mst_users_with_dates;
사용자의 생년월일로 나이 계산하기 (YEAR 차이 계산하기)
AGE( 계산할 시점, 기준 시점(생일) );
※ AGE함수는 PostgreSQL전용, INTERVAL 자료형의 날짜 단위가 출력되기에 AGE를 구하기 위해서 YEAR만 EXTRACT해주기
※ 디폴트로는 현재 나이 리턴, 특정 날짜 지정 시 해당 날짜에서의 나이 리턴
--age 함수로 나이 계산
select user_id,
current_date as today,
register_stamp::date as register_date,
birth_date::date as birth_date,
extract(year from age(birth_date::date)) as current_age,
extract(year from age(register_stamp::date, birth_date::date)) as register_age
from mst_users_with_dates;
정수로 표현해서 나이 계산하는 함수 사용하기
-- 생일이 2000.2.29인 사람의 2016.2.28인 시점의 나이 계산하기
select floor((20160228 - 20000209) / 10000) as age;
등록 시점과 현재 시점의 나이를 문자열로 계산하기
: 날짜/시간 데이터의 계산은 미들웨어에 따라 표현에 차이가 커서, 실무에서는 수치 또는 문자열로 변환해 다루는 것이 편한 경우가 많다.
※ 문자열에서 하이픈(-)을 제거하고 정수로 캐스트해서 계산
※ substring(문자열,시작위치,길이)
※ CAST( [컬럼명] AS 변환하고자 하는 Data Type)
-- 현재 시점 - 등록 시점 = 나이
select user_id,
substring(register_stamp, 1, 10) as register_date,
birth_date,
-- 등록시점의 나이
floor((cast(replace(substring(register_stamp,1,10),'-','') as integer)
- cast(replace(birth_date, '-','') as integer)) / 10000) as register_age,
-- 현재 시점의 나이
floor((cast(replace(cast(current_date as text), '-', '') as integer)
- cast(replace(birth_date, '-','') as integer)) / 10000) as current_age
from mst_users_with_dates;
6-6. IP 주소 다루기
(inet 자료형, << 연산자, split_part 함수, lpad 함수)
보통 ip주소를 로그로 저장할 때에는 문자열로 저장
하지만, ip 주소를 서로 비교하거나 동일 네트워크의 ip주소인지 판정할 대는 단순 문자열 비교만으로는 코드가 복잡해짐
IP 주소 자료형 활용하기
※ inet 자료형: ip주소를 다루기 위한 자료형 --PostgreSQL 전용
IP 주소 대소 비교
-- ip 주소 비교 (inet 자료형)
select
cast('127.0.0.1' as inet) < cast('127.0.0.2' as inet) as lt,
cast('127.0.0.1' as inet) > cast('192.168.0.1' as inet) as gt;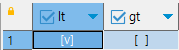
IP주소가 포함되는지 판정 (<<, >> 연산자 이용)
select cast('127.0.0.1' as inet) << cast('127.0.0.0/8' as inet) as is_contained;
정수 또는 문자열로 IP 주소 다루기
: inet 자료형이 제공되지 않는 미들웨어의 경우, 다른 방법을 사용해야 함
IP 주소를 정수 자료형으로 변환하기
select ip,
cast(split_part(ip, '.', 1) as integer) as ip_part_1,
cast(split_part(ip, '.', 2) as integer) as ip_part_2,
cast(split_part(ip, '.', 3) as integer) as ip_part_3,
cast(split_part(ip, '.', 4) as integer) as ip_part_4
from
(select cast('192.168.0.1' as text) as ip) as t; -- PostgreSQL은 명시적 자료형 변환 필요
-- IP 주소 정수 자료형으로 표기
select ip,
cast(split_part(ip, '.', 1) as integer) * 2^24 +
cast(split_part(ip, '.', 2) as integer) * 2^16 +
cast(split_part(ip, '.', 3) as integer) * 2^8 +
cast(split_part(ip, '.', 4) as integer) * 2^0
as ip_integer
from (select cast('192.168.0.1' as text) as ip) as t;
IP 주소를 0으로 메워서 문자열로 만들기
lpad(문자열, 만들어질 자릿 수, '채워질 문자')
: 지정한 문자 수가 되게 문자열의 왼쪽을 메우는 함수
IP 주소의 각 10진수를 0으로 메워서 고정 길이 문자열을 만들면, 문자열 상태로 대소 비교를 할 수 있다.
select ip,
lpad(split_part(ip, '.', 1), 3, '0') ||
lpad(split_part(ip, '.', 2), 3, '0') ||
lpad(split_part(ip, '.', 3), 3, '0') ||
lpad(split_part(ip, '.', 4), 3, '0')
as ip_padding
from
(select cast('192.168.9.1' as text) as ip) as t;



