
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데이터 정합성
- splitlines
- Growth hacking
- 캐글 산탄데르 고객 만족 예측
- lightgbm
- 3기가 마지막이라니..!
- XGBoost
- 스태킹 앙상블
- sql
- tableau
- 데이터 핸들링
- WITH ROLLUP
- 분석 패널
- ImageDateGenerator
- 인프런
- 컨브넷
- 그로스 마케팅
- 그룹 연산
- 데이터 증식
- python
- 리프 중심 트리 분할
- pmdarima
- ARIMA
- 캐글 신용카드 사기 검출
- 로그 변환
- 그로스 해킹
- WITH CUBE
- 부트 스트래핑
- DENSE_RANK()
- 마케팅 보다는 취준 강연 같다(?)
- Today
- Total
LITTLE BY LITTLE
[4] 데이터 가공을 위한 SQL - 하나의 테이블에 대한 조작 : over(~rows~), max(case~), string_agg, unnest, string_to_array, regexp_split_to_table 본문
[4] 데이터 가공을 위한 SQL - 하나의 테이블에 대한 조작 : over(~rows~), max(case~), string_agg, unnest, string_to_array, regexp_split_to_table
위나 2024. 1. 14. 22:20
목차
3. 데이터 가공을 위한 SQL
3-1. 하나의 값 조작하기 (5강) 3-2. 여러 개의 값에 대한 조작 (6강)
3-3. 하나의 테이블에 대한 조작 (7강)
4. 매출을 파악하기 위한 데이터 추출
4-1. 시계열 기반으로 데이터 집계하기
4-2. 다면적인 축을 사용해 데이터 집약하기
5. 사용자를 파악하기 위한 데이터 추출
5-1. 사용자 전체의 특징과 경향 찾기
5-2. 시계열에 따른 사용자 전체의 상태 변화 찾기
5-3. 시계열에 따른 사용자의 개별적인 행동 분석하기
6. 웹사이트에서 행동을 파악하는 데이터 추출하기
6-1. 사이트 전체의 특징/경향 찾기
6-2. 사이트 내의 사용자 행동 파악하기
6-3. 입력 양식 최적화하기
7. 데이터 활용의 정밀도를 높이는 분석 기술
7-1. 데이터를 조합해서 새로운 데이터 만들기
7-2. 이상값 검출하기
7-3. 데이터 중복 검출하기
7-4. 여러 개의 데이터셋 비교하기
8. 데이터를 무기로 삼기 위한 분석 기술
8-1. 검색 기능 평가하기
8-2. 데이터 마이닝
8-3. 추천
8-4. 점수 계산하기
9. 지식을 행동으로 옮기기
9-1. 데이터 활용의 현장
3장 - 7강. 하나의 테이블에 대한 조작
하나의 테이블을 대상으로 하는 데이터 집약 방법과 가공 방법
7-1. 그룹의 특징 잡기
( 집약 함수, GROUP BY 구문, 윈도 함수, OVER(...PARTITION BY~) 구문 )
create review 테이블

테이블 전체의 특징량 계산하기
select
count(*) as total_count,
count(distinct user_id) as user_count,
count(distinct product_id) as product_count,
sum(score) as sum,
avg(score) as avg,
max(score) as max,
min(score) as min
from review;
그룹핑한 데이터의 특징량 계산하기
GROUP BY 사용 시 주의해야 할 점
: GROUP BY 구문에 지정한 컬럼 또는 집약 함수만 SELECT 구문의 컬럼으로 지정할 수 있다.
※ GROUP BY 구문을 사용한 쿼리에서는 지정한 컬럼을 고유값으로 새로운 테이블을 만들게 되기 때문에, GROUP BY 구문에 지정하지 않은 컬럼은 사라져 버려서 집약 전의 값과 동시에 사용할 수 없다.
사용자(uesr_id)를 기반으로 테이블을 분할하고 집약 함수 적용
select
count(*) as total_count,
count(distinct user_id) as user_count,
count(distinct product_id) as product_count,
sum(score) as sum,
avg(score) as avg,
max(score) as max,
min(score) as min
from review
group by user_id;
집약 함수를 적용한 값과 집약 전의 값을 동시에 다루기
- 앞서 주의해야할 점에서 언급했듯이, 집약 전의 값은 원래 사용할 수 없지만, 사용할 수 있는 방법이 있다.
윈도우 함수
WINDOW_FUNCTION OVER()
SELECT WINDOW_FUNCTION(ARGUMENTS) OVER ([PARTITIONBY 컬럼] [ORDERBY 컬럼] [WINDOWING 절] ) FROM 테이블명 ;
- WINDOW_FUNCTION : 윈도우 함수
- ARGUMENTS(인수) : 함수에 따라 0 ~ N개 인수가 지정될 수 있다.
- PARTITION BY 절 : 전체 집합을 기준에 의해 소그룹으로 나눌 수 있다. ex. 사용자 별 평균 리뷰 점수
- ORDER BY 절 : 어떤 항목에 대해 순위를 지정할 지 order by 절을 기술한다.
- WINDOWING 절 : WINDOWING 절은 함수의 대상이 되는 행 기준의 범위를 강력하게 지정할 수 있다. (sql server 에서는 지원하지 않음)
개별 리뷰 점수(avg_score)와 평균 리뷰 점수(user_avg_score)의 차이 구하기
select user_id, product_id,
--개별 리뷰 점수
score,
--전체 평균 리뷰 점수
round(avg(score) over()) as avg_score,
--사용자의 평균 리뷰 점수
round(avg(score) over(partition by user_id),2) as user_avg_score,
--개별 리뷰 점수와 사용자 평균 리뷰 점수의 차이
round(score - avg(score) over (partition by user_id),2) as user_avg_score_diff
from review;
7-2. 그룹 내부의 순서
( 윈도 함수, OVER(...PARTITION BY~) 구문, OVER(...ROWS~) 구문 )
테이블 popular_products 생성

ORDER BY 구문으로 순서 정의하기
: 윈도 내부에 있는 데이터의 순서를 정의할 수 있다.
순위 관련 윈도우 함수(3)
ROW_NUMBER()
: 순위 번호 붙이기
RANK(), DENSE_RANK()
: 같은 순위의 레코드가 있을 때 순위 번호를 같게 붙인다. RANK는 같은 순위인 경우 건너뛰고, DENSE는 건너뛰지 않음
LAG([컬럼명], pre_row)
: 현재 행을 기준으로 앞의 행의 값을 추출
LEAD([컬럼명], after_row)
: 현재 행을 기준으로 뒤의 행의 값을 추출
윈도 함수의 order by 구문을 사용해 테이블 내부의 순서 다루기
select product_id, score,
--점수 순서로 유일한 순위를 붙임
row_number() over (order by score desc) as row,
-- 같은 순위를 허용해서 순위를 붙임
rank() over (order by score desc) as rank,
-- 같은 순위가 있을 때 순위를 건너 뛰고 순위를 붙임
dense_rank() over (order by score desc) as dense_rank,
-- 현재 행보다 앞에 있는 행의 값 추출
lag(product_id) over (order by score desc) as lag1,
lag(product_id, 2) over (order by score desc) as lag2,
-- 현재 행보다 뒤에 있는 행의 값 추출
lead(product_id) over (order by score desc) as lead1,
lead(product_id, 2) over (order by score desc) as lead2
from popular_products
order by row;
ORDER BY 구문과 집약 함수 조합하기
FIRST_VALUE(), LAST_VALUE() : 윈도 내부에서 가장 첫 번째/마지막 레코드를 추출
프레임 지정 구문 range between ..(start).. and ..(end)..
: 프레임 지정이란, 현재 레코드 위치를 기반으로 상대적인 윈도를 정의하는 구문
range between과 and 사이에는 (start)
- unbounded preceding: 최종 출력될 값의 맨 처음 row의 값 (*partition by 고려)
- current row: 현재 row의 값
- n preceding: n행 앞
and 다음에는 (end)
- unbounded following: 최종 출력될 값의 맨 마지막 row의 값 (*partition by 고려)
- n following: n행 뒤
order by 구문과 집약 함수를 조합해서 계산하기
select product_id, score,
row_number() over (order by score desc) as row,
-- 순위 상위부터 누계 점수 계산하기
sum(score) over (order by score desc
rows between unbounded preceding and current row) as cum_score,
-- 현재 행과 앞뒤 행이 가진 값을 기반으로 평균 점수 계산하기
round(avg(score) over (order by score desc
rows between 1 preceding and 1 following),2) as local_avg,
-- 순위가 높은 상품 id 추출하기
first_value(product_id) over (order by score desc
rows between unbounded preceding and unbounded following) as first_value,
-- 순위가 낮은 상품 id 추출하기
last_value(product_id) over (order by score desc
rows between unbounded preceding and unbounded following) as last_value
from popular_products
order by row
;
array_agg()
: group by 된 값들을 array로 반환
윈도 프레임 지정 별 상품 ID 집약하기
select product_id,
row_number() over (order by score desc) as row,
-- 가장 앞 순위 ~ 가장 뒷 순위까지의 범위를 대상으로 상품 id 집약
array_agg(product_id) over (order by score desc
rows between unbounded preceding and unbounded following) as whole_agg,
-- 가장 앞 순위부터 현재 순위까지의 범위를 대상으로 상품 id 집약
array_agg(product_id) over (order by score desc
rows between unbounded preceding and current row) as cum_agg,
-- 순위 하나 앞고 하나 뒤까지의 범위를 기준으로 상품 id 집약
array_agg(product_id) over (order by score desc
rows between 1 preceding and 1 following) as local_agg
from popular_products
where category = 'action'
order by row;
partition by 와 order by 조합하기
윈도 함수를 사용해 카테고리 순위 계산하기
select category, product_id, score,
--카테고리 별 점수 순서로 정렬하고, 유일한 순위 붙이기
row_number() over (partition by category order by score desc) as row,
-- 카테고리 별 같은 순위를 허가하고 순위 붙이기
rank() over (partition by category order by score desc) as rank,
-- 카테고리 별 같은 순위가 있을 때, 건너뛰고 순위 붙이기
dense_rank() over (partition by category order by score desc) as dense_rank
from popular_products
order by category, row;
※ partition by 와 group by의 차이
: partition by는 group by와 유사한 기능을 하지만, 요약한 데이터 한 줄만 보는 것이 아니라, 데이터 전체를 보고 싶을 때 사용한다는 점이 차이점이다.
| GROUP BY | PARTITION BY | |
| 사용 | 그룹 외부에서 묶어 순위 및 그룹별 집계를 구할 떄 사용 | 그룹 내 순위 및 그룹별 집계를 구할 때 사용 |
| 결과값 | 특정 원하는 컬럼에 대해서 추출해 결과값 보여줌 | 전체 데이터에서 원하는 결과값 보여줌 |
각 카테고리 별 상위 n개 추출하기
카테고리들의 순위 상위 2개까지의 상품 추출하기
※ 서브 쿼리를 사용한 이유는, sql 사양으로 인해 윈도 함수를 where 구문에 작성할 수 없기 때문이다.
- select 구문에서 윈도 함수를 사용한 결과를 서브쿼리로 만들고, 외부에서 where구문을 적용해야 한다.
select * from
-- 서브 쿼리 내부에서 순위 계산하기
( select category, product_id, score,
row_number() over (partition by category order by score desc) as rank
from popular_products) as popular_products_with_rank
-- 외부 쿼리에서 순위 활용해 압축하기
where rank <=2
order by category, rank;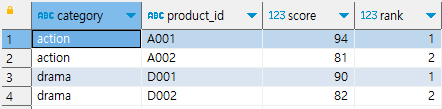
카테고리들의 순위 상위 1개 상품 추출하기
※ 상위 1개만을 보고자 할 경우, FIRST_VALUE () 윈도 함수를 사용하고, SELECT DISTINCT () 구문으로 결과를 집약할 수 있다. (서브쿼리 사용하지 않고)
-- distinct구문으로 중복 제거
select distinct category,
--카테고리 별로 순위 최상위 상품 id 추출
first_value(product_id)
over (partition by category order by score desc
rows between unbounded preceding and unbounded following) as product_id
from popular_products;
7-3. 세로 기반 데이터를 가로 기반으로 변환하기
( MAX(CASE~) 구문, string_agg 함수, listagg 함수, collect_list 함수 )
SQL은 행(레코드)를 기반으로 처리하는 것이 기본이지만, 최종 출력에서는 데이터를 열로 전개해야 가독성이 높은 경우가 많다.
행을 열로 변환하기
create daily_kpi table
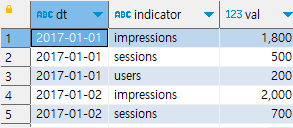
MAX (CASE~) 구문 사용해서 행을 열로 변환하기
select dt,
max(case when indicator = 'impressions' then val end) as impression,
max(case when indicator = 'sessions' then val end) as sessions,
max(case when indicator = 'users' then val end) as users
from daily_kpi
group by dt
order by dt;
행을 쉼표로 구분한 문자열로 집약하기
미리 열의 종류와 수를 알고 있을 때에만 앞의 방법을 사용할 수 있다. 그렇지 않은 경우 행을 문자열로 집약하는 방법을 생각해볼 수 있다.
STRING_AGG( [컬럼명], '구분자' ) ~ GROUP BY (ORDER BY ~)
: 컬럼 값을 정렬하여 구분자로 합치는 함수, group by 절과 함께 사용해야 한다.
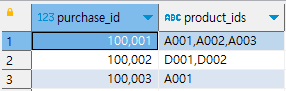
create table purchase_detail_log

purchase_id에 따른 product_id 상품들을 집약해서 보여주기
select purchase_id,
--상품 id를 배열에 집약하고, 쉼표로 구분된 문자열 변환하기
string_agg(product_id, ',') as product_ids
from purchase_detail_log
group by purchase_id
order by purchase_id;
7-4. 가로 기반 데이터를 세로 기반으로 변환하기
( unnest함수, explode 함수, CROSS JOIN, LATERAL VIEW, regexp_split_to_table 함수 )
레코드로 저장된 세로 기반 데이터를 가로 기반으로 변환하는 것은 간단하지만, 반대로 가로 기반 데이터를 세로 기반으로 변환하는 것은 간단한 일이 아니다.
열로 표현된 값을 행으로 변환하기

위처럼 컬럼으로 표현된 가로 기반 데이터의 특징은 데이터의 수가 고정되어 있다는 것 (q1~q4 4가지 데이터로 구성)
수가 고정되어 있다면, 같은 일련번호를 가진 피벗 테이블을 만들고 cross join하면 된다.
피벗 테이블을 결합하고, case식으로 레이블 이름과 매출 값을 추출해서 열을 행으로 변환하기
select q.year,
-- q1~q4 레이블 이름 출력
case when p.idx = 1 then 'q1'
when p.idx = 2 then 'q2'
when p.idx = 3 then 'q3'
when p.idx = 4 then 'q4'
end as quarter,
-- q1~q4까지의 매출 출력
case when p.idx = 1 then q.q1
when p.idx = 2 then q.q2
when p.idx = 3 then q.q3
when p.idx = 4 then q.q4
end as sales
from quarterly_sales as q
cross join
--행으로 전개하고 싶은 열의 수 만큼 순번 테이블 만들기
( select 1 as idx
union all select 2 as idx
union all select 3 as idx
union all select 4 as idx
) as p;
임의의 길이를 가진 배열을 행으로 전개하기
다음과 같은 테이블 형태를 행으로 전개하기
UNNEST()
: array를 입력받아, array의 각 요소에 대한 행이 한 개씩 포함된 테이블을 리턴해준다.
※ unnest와 where 조건 차이
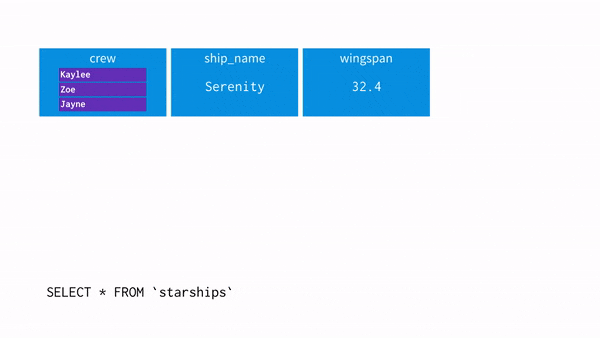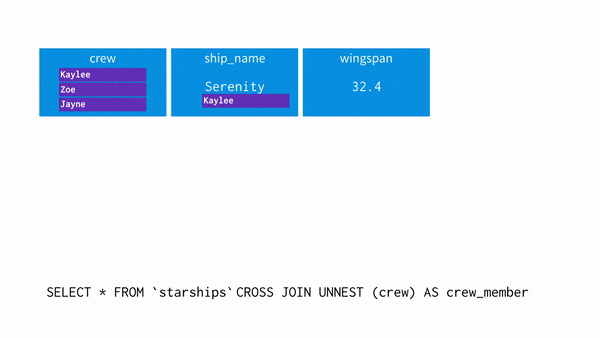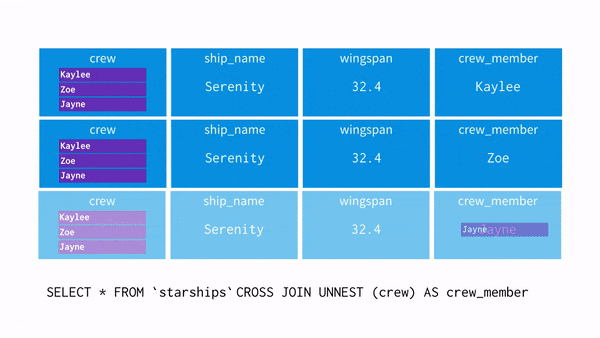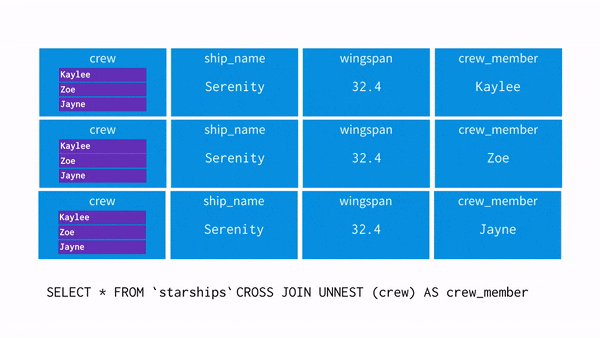
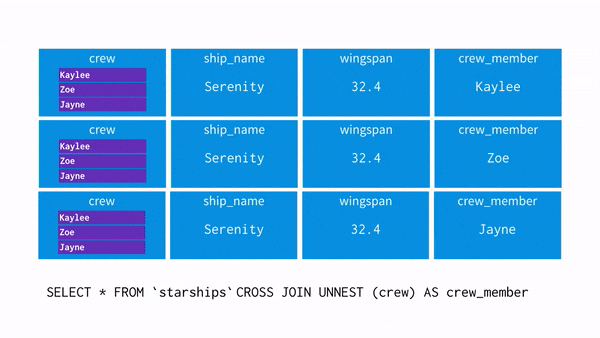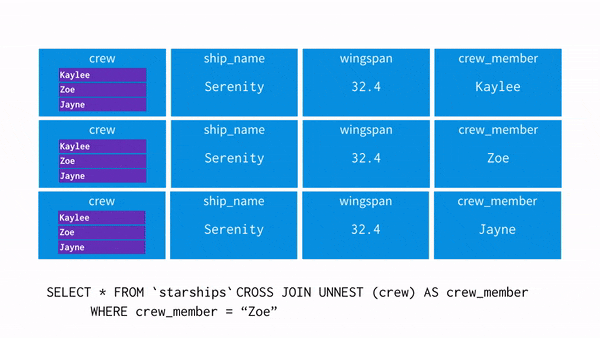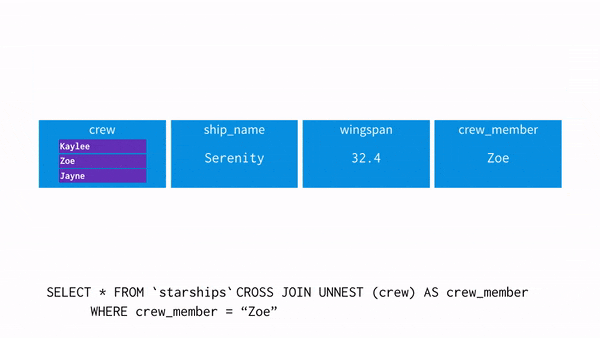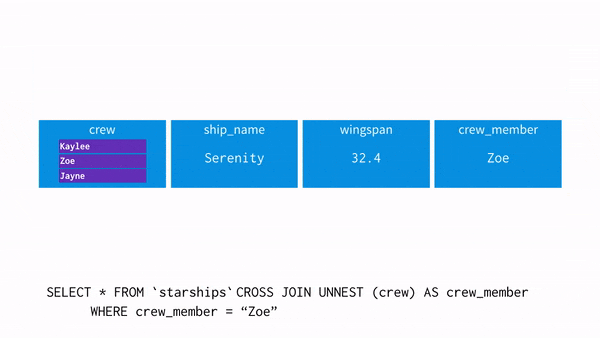
select unnest(array['A001','A002','A003']) as product_id;
STRING_TO_ARRAY()
select purchase_id, product_id
from purchase_log as p
-- string_to_array 함수로 문자열을 배열로 변환하고, unnest함수로 테이블로 변환
cross join unnest(string_to_array(product_ids, ',')) as product_id;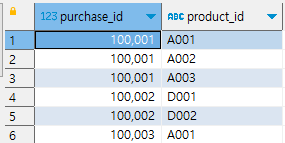
또는
(PostgreSQL)
regexp_split_to_table 함수
: 문자열을 구분자로 분할해서 테이블화하는 함수로 간단하게 쉼표로 구분된 문자열을 행으로 전개할 수 있다.
select purchase_id,
--쉼표로 구분된 문자열을 한 번에 행으로 전개하기
regexp_split_to_table(product_ids, ',') as product_id
from purchase_log;
※ Redshift에서는 배열 자료형이 공식적으로 지원되지 않아 위와 같은 방법을 모두 사용할 수 없다.
Redshift에서 문자열을 행으로 전개하려면,
1. 일련 번호를 가진 피벗테이블을 만들고,
2. split_part 함수로 문자열을 분할해서 n번째 요소를 추출해서,
3. 문자 수의 차이를 사용해 상품 수를 계산하고,
4. 피벗 테이블을 사용해 문자열을 행으로 전개해야 한다.
1. 일련 번호를 가진 피벗테이블 만들기
select * from
(select 1 as idx
union all select 2 as idx
union all select 3 as idx) as pivot;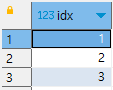
2. split_part 함수로 문자열을 분할해서 n번째 요소 추출하기
select
split_part('A001,A002,A003', ',', 1) as part_1,
split_part('A001,A002,A003', ',', 2) as part_2,
split_part('A001,A002,A003', ',', 3) as part_3;
3. 문자 수의 차이를 사용해 상품 수 계산하기 (char_length)
purchase_log 테이블의 각 레코드에 상품 수만큼 일련 번호를 부여하고, 번호 순서대로 상품 id를 꺼냄
select purchase_id, product_ids,
-- 상품 id 문자열을 기반으로 쉼표 제거
-- 문자 수의 차이 계산해서 상품 수 구하기
1+char_length(product_ids)
- char_length(replace(product_ids, ',',''))
as product_num
from purchase_log;
4. 피벗 테이블을 사용해 문자열을 행으로 전개하기 (최종 쿼리)
select l.purchase_id, l.product_ids,
--상품 수 만큼 순번 붙이기
p.idx,
--문자열을 쉼표로 구분해서 분할하고, idx번째 요소 추출
split_part(l.product_ids, ',', p.idx) as product_id
from purchase_log as l
join
(select 1 as idx
union all select 2 as idx
union all select 3 as idx) as p
--피벗 테이블의 id가 상품 수 이하인 경우 결합하기
on p.idx<=
(1+char_length(l.product_ids)
- char_length(replace(l.product_ids, ',','')));
'시각화 > SQL로 분석하고 Tableau로 시각화하자' 카테고리의 다른 글
| [17,끝] SQL로 분석하고 Tableau로 시각화하자 - 지역별 매장 분석, 카테고리 분석, 워드 클라우드 (0) | 2022.07.26 |
|---|---|
| [16] SQL로 분석하고 Tableau로 시각화하자 - 매개변수, 대시보드, RFM 고객 세분화 분석 (0) | 2022.07.25 |
| [15] SQL로 분석하고 Tableau로 시각화하자 - 기본 함수 (0) | 2022.07.25 |
| [14] SQL로 분석하고 Tableau로 시각화하자 - 퀵 테이블 계산, 개별/단일/이중 축 (0) | 2022.07.23 |
| [13] SQL로 분석하고 Tableau로 시각화하자 - Tableau 속 SQL (0) | 2022.07.22 |



