| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- DENSE_RANK()
- 로그 변환
- 데이터 정합성
- 3기가 마지막이라니..!
- 부트 스트래핑
- Growth hacking
- ARIMA
- 캐글 산탄데르 고객 만족 예측
- 그룹 연산
- 분석 패널
- WITH ROLLUP
- splitlines
- 그로스 해킹
- 그로스 마케팅
- 스태킹 앙상블
- tableau
- 캐글 신용카드 사기 검출
- python
- 컨브넷
- sql
- 리프 중심 트리 분할
- WITH CUBE
- XGBoost
- ImageDateGenerator
- lightgbm
- 마케팅 보다는 취준 강연 같다(?)
- 데이터 핸들링
- 인프런
- pmdarima
- 데이터 증식
- Today
- Total
LITTLE BY LITTLE
[9] 데이터 가공을 위한 SQL - 사용자를 파악하기 위한 데이터 추출 2 : 벤 다이어그램, Decile 분석, RFM 분석 본문
[9] 데이터 가공을 위한 SQL - 사용자를 파악하기 위한 데이터 추출 2 : 벤 다이어그램, Decile 분석, RFM 분석
위나 2024. 2. 4. 22:25
목차
3. 데이터 가공을 위한 SQL 3-1. 하나의 값 조작하기 (5강) 3-2. 여러 개의 값에 대한 조작 (6강) 3-3. 하나의 테이블에 대한 조작 (7강)3-4. 여러 개의 테이블 조작하기 (8강)4. 매출을 파악하기 위한 데이터 추출 (9강) 4-1. 시계열 기반으로 데이터 집계하기 (10강)4-2. 다면적인 축을 사용해 데이터 집약하기
5. 사용자를 파악하기 위한 데이터 추출
5-1. 사용자 전체의 특징과 경향 찾기
5-2. 시계열에 따른 사용자 전체의 상태 변화 찾기
5-3. 시계열에 따른 사용자의 개별적인 행동 분석하기
6. 웹사이트에서 행동을 파악하는 데이터 추출하기
6-1. 사이트 전체의 특징/경향 찾기
6-2. 사이트 내의 사용자 행동 파악하기
6-3. 입력 양식 최적화하기
7. 데이터 활용의 정밀도를 높이는 분석 기술
7-1. 데이터를 조합해서 새로운 데이터 만들기
7-2. 이상값 검출하기
7-3. 데이터 중복 검출하기
7-4. 여러 개의 데이터셋 비교하기
8. 데이터를 무기로 삼기 위한 분석 기술
8-1. 검색 기능 평가하기
8-2. 데이터 마이닝
8-3. 추천
8-4. 점수 계산하기
9. 지식을 행동으로 옮기기
9-1. 데이터 활용의 현장
※ Mysql 기준
5장. 사용자를 파악하기 위한 데이터 추출
11강. 사용자 전체의 특징과 경향 찾기
~11-5부터 이어서~
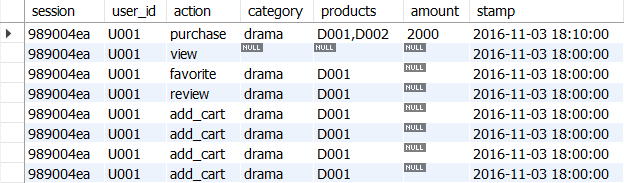
11-5. 벤 다이어그램으로 사용자 액션 집계하기
SIGN, SUM, CASE식, CUBE구문, 벤 다이어그램
사용자 단위로 로그를 집약하고, purchase/review/favorite이라는 3개의 액션 로그 존재 여부로 0,1부여
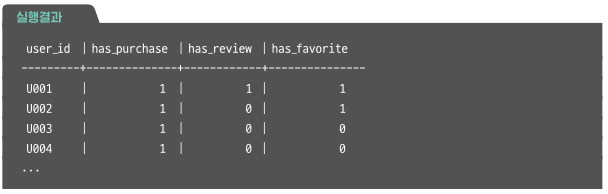
WITH flag AS(
SELECT user_id,
SIGN(SUM(CASE WHEN action='purchase' THEN 1 ELSE 0 END)) AS has_purchase,
SIGN(SUM(CASE WHEN action='review' THEN 1 ELSE 0 END)) AS has_review,
SIGN(SUM(CASE WHEN action='favorite' THEN 1 ELSE 0 END)) has_favorite
FROM action_log
GROUP BY user_id)
SELECT * FROM flag;
벤 다이어그램을 그리기 위한 액션 또는 두 개의 액션을 한 사용자가 몇 명인지 계산하기
CUBE구문
CUBE는 소계와 총계를 모두 계산하는 함수, ROLLUP과 유사
MySQL에서는 CUBE가 안되는 것 같다..ROLLUP과 차이점이 있나?
WITH flag AS(
SELECT user_id,
SIGN(SUM(CASE WHEN action='purchase' THEN 1 ELSE 0 END)) AS has_purchase,
SIGN(SUM(CASE WHEN action='review' THEN 1 ELSE 0 END)) AS has_review,
SIGN(SUM(CASE WHEN action='favorite' THEN 1 ELSE 0 END)) AS has_favorite
FROM action_log
GROUP BY user_id),
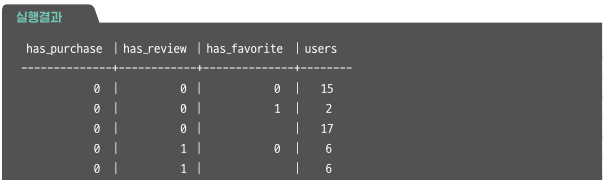
action_venn_diagram AS(
SELECT has_purchase,
has_review,
has_favorite,
COUNT(*) AS users
FROM flag
GROUP BY has_purchase, has_review, has_favorite WITH ROLLUP)
SELECT * FROM action_venn_diagram
ORDER BY has_purchase, has_review, has_favorite;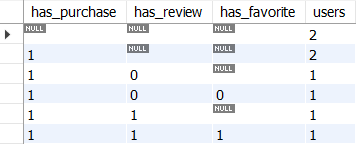
※ NULL 레코드는 해당 액션을 했는지, 안 했는지 모르는 경우를 의미
*CUBE(ROLL UP)을 사용하지 않고 같은 결과 출력하는 방법
:모든 액션 조합을 개별적으로 구하고, UNION ALL로 결합
- 3개 모두 한 경우, 3개 중 2개를 한 경우, 3개 중 1개를 한 경우, 액션과 관계 없이 모든 사용자 집계 까지 UNION을 너무 많이 사용하므로 성능이 좋지 않음
WITH flag AS(
SELECT user_id,
SIGN(SUM(CASE WHEN action='purchase' THEN 1 ELSE 0 END)) AS has_purchase,
SIGN(SUM(CASE WHEN action='review' THEN 1 ELSE 0 END)) AS has_review,
SIGN(SUM(CASE WHEN action='favorite' THEN 1 ELSE 0 END)) AS has_favorite
FROM action_log
GROUP BY user_id),
action_venn_diagram AS(
SELECT has_purchase, has_review, has_favorite, COUNT(*) AS users
FROM flag
GROUP BY has_purchase, has_review, has_favorite
UNION ALL
SELECT NULL AS has_purchase, has_review, has_favorite, COUNT(*) AS users
FROM flag
GROUP BY has_review, has_favorite
UNION ALL
SELECT has_purchase, NULL AS has_review, has_favorite, COUNT(*) AS users
FROM flag
GROUP BY has_purchase, has_favorite)
-- 생략...
SELECT * FROM action_venn_diagram;
*CUBE(ROLL UP)을 사용하지 않고 같은 결과 출력하는 방법 2
: 유사적으로 NULL을 포함한 레코드를 추가해서 CUBE 구문과 같은 결과를 얻는 쿼리, UNNEST사용
- UNNEST(array[]): array를 입력받아, array의 각 요소에 대한 행이 한 개씩 포함된 테이블을 리턴
1. 평면화(flatten)작업을 한다고 생각하면 이해하기 쉽다. <unnest+cross join=flatten>
2. 한 행에 여러 개의 데이터가 들어가 있는 구조인 경우 한 개의 데이터가 들어있는 우리가 보는 익숙한 형태로 바꿔줌
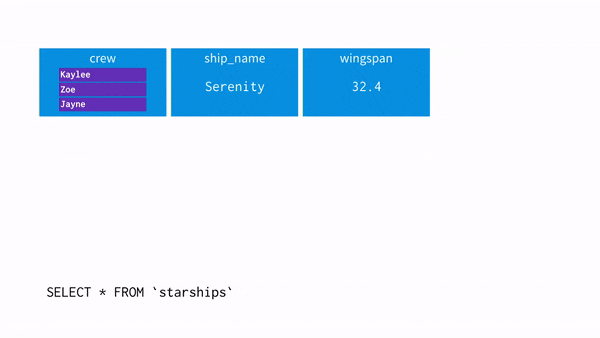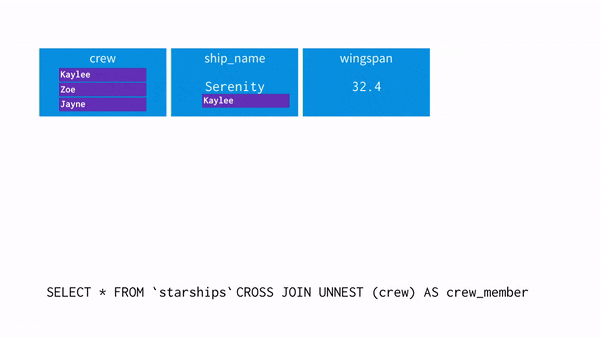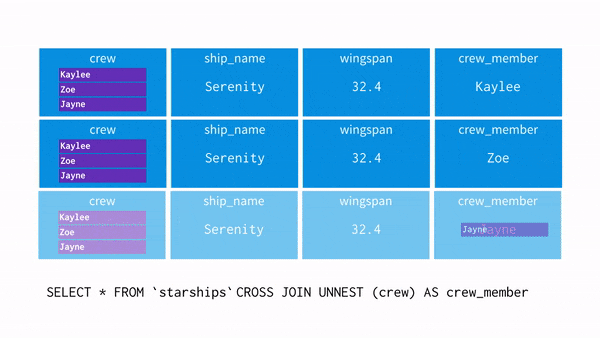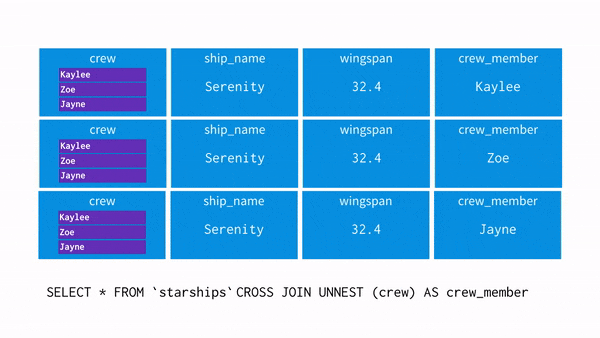
* CROSS JOIN = Cartesian Product
* Union은 append vertically, JOIN은 append horizontally
WITH flag AS(
SELECT user_id,
action,
SIGN(SUM(CASE WHEN action='purchase' THEN 1 ELSE 0 END)) AS has_purchase,
SIGN(SUM(CASE WHEN action='review' THEN 1 ELSE 0 END)) AS has_review,
SIGN(SUM(CASE WHEN action='favorite' THEN 1 ELSE 0 END)) AS has_favorite
FROM action_log
GROUP BY user_id),
action_venn_diagram AS
(SELECT
mod_has_purchase AS has_purchase,
mod_has_review AS has_review,
mod_has_favorite AS has_favorite,
COUNT(*) AS users
FROM flag
/* mysql에서는 array형태를 지원하지 않는다..
CROSS JOIN UNNEST(ARRAY([has_purchase, NULL]) AS mod_has_purchase,
CROSS JOIN UNNEST(ARRAY([has_review, NULL]) AS mod_has_review,
CROSS JOIN UNNEST(ARRAY([has_favorite, NULL]) AS mod_has_favorite 대신에*/
/*얘도 안됨 LATERAL VIEW EXPLODE(array(has_purchase, NULL)) e1 AS mod_has_purchase
LATERAL VIEW EXPLODE(array(has_review, NULL)) e1 AS mod_has_review
LATERAL VIEW EXPLODE(array(has_favorite, NULL)) e1 AS mod_has_favorite*/
CROSS JOIN
(SELECT 'has_purchase' AS mod_has_purchase UNION SELECT NULL) AS mod_has_purchase
CROSS JOIN
(SELECT 'has_review' AS mod_has_review UNION SELECT NULL) AS mod_has_review
CROSS JOIN
(SELECT 'has_favorite' AS mod_has_favorite UNION SELECT NULL) AS mod_has_favorite
GROUP BY
mod_has_purchase, mod_has_review, mod_has_favorite)
SELECT * FROM action_venn_diagram
ORDER BY has_purchase, has_review, has_favorite;※ MySQL에서 배열을 조회하는 방법 - 서브쿼리를 활용하여 값을 합치기..그냥 WITH ROLLUP을 쓰면 될 것 같다
벤 다이어그램을 만들기 위해 데이터 가공하기
1. 0,1플래그를 문자로 가공하기
EX. purchase가 1이면 'purchase', 0이면 'any'
2. 전체 사용자 수를 기반으로 비율구하기
: 모든 액션이 NULL인 사용자 수가 전체 사용자 수를 의미함(=WITH ROLLUP으로 구한 합계니까)

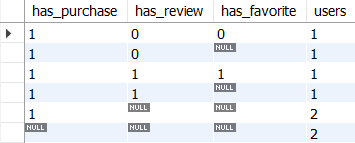
WITH flag AS(
SELECT user_id,
SIGN(SUM(CASE WHEN action='purchase' THEN 1 ELSE 0 END)) AS has_purchase,
SIGN(SUM(CASE WHEN action='review' THEN 1 ELSE 0 END)) AS has_review,
SIGN(SUM(CASE WHEN action='favorite' THEN 1 ELSE 0 END)) AS has_favorite
FROM action_log
GROUP BY user_id),
action_venn_diagram AS(
SELECT has_purchase,
has_review,
has_favorite,
COUNT(*) AS users
FROM flag
GROUP BY has_purchase, has_review, has_favorite WITH ROLLUP)
-- 벤 다이어그램을 만들기 위해 데이터 가공하는 부분
SELECT
CASE has_purchase WHEN 1 THEN 'purchase' ELSE 'any' END AS has_purchase,
CASE has_review WHEN 1 THEN 'review' ELSE 'any' END AS has_review,
CASE has_favorite WHEN 1 THEN 'favorite' ELSE 'any' END AS has_favorite,
users,
100.0 * users / NULLIF(
SUM(CASE WHEN has_purchase IS NULL
AND has_review IS NULL
AND has_favorite IS NULL
THEN users ELSE 0 END) OVER(), 0) AS ratio
FROM action_venn_diagram
ORDER BY has_purchase, has_review, has_favorite;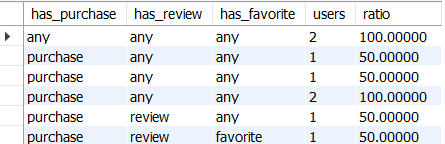
※ 벤 다이어그램을 통해서 위와 유사한 형태로 적용할 수 있다.
EX. 글은 작성하지 않지만 다른사람의 글은 확인하는 사용자, 글을 많이 작성하는 사용자, 글은 작성하지 않지만 댓글은 작성하는 사용자 등등... 효과가 발생한 사용자가 얼마나 되는지 확인할 때 효과적이다.
11-6. Decile 분석을 사용해 사용자를 10단계 그룹으로 나누기
NTILE 윈도 함수, Decile 분석
Decile 분석 과정
<사용자 구매금액에 따라 순위 구분하고 중요도 파악하기>
1. 사용자를 구매 금액이 많은 순으로 정렬
2. 정렬된 사용자 상위부터 10%씩 Decile 1~10까지의 그룹 할당
3. 각 그룹의 구매 금액 합계 집계
4. 전체 구매 금액에 대해 각 Decile의 구매 금액 비율(구성비) 계산
5. 상위에서 누적으로 어느정도의 비율을 차지하는지 구성비 누계 집계
구매액이 많은 순서로 사용자를 정렬하고, 10%씩 Decile1~10으로 그룹 할당하기
NTILE() 함수 활용
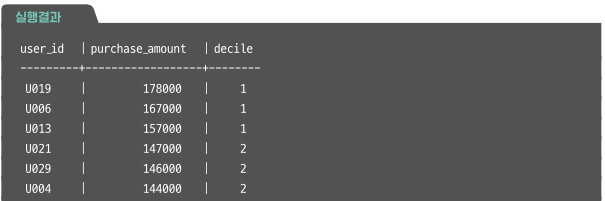
WITH user_amt AS(
SELECT
user_id,
SUM(amount) AS purchase_amount
FROM action_log
WHERE action='purchase'
GROUP BY user_id),
user_decile AS(
SELECT
user_id,
purchase_amount,
ntile(10) OVER (ORDER BY purchase_amount DESC) AS decile
FROM user_amt)
SELECT * FROM user_decile;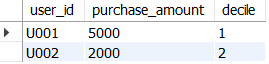
Decile 집계 (sum, avg, cum_sum, total)
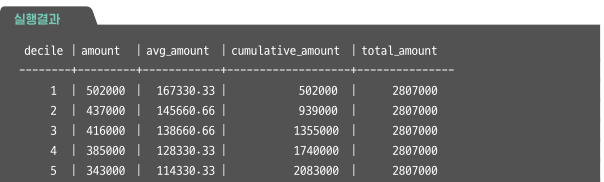
WITH user_amt AS(
SELECT user_id,
SUM(amount) AS purchase_amount
FROM action_log
WHERE action='purchase'
GROUP BY user_id),
user_decile AS(
SELECT user_id,
purchase_amount,
ntile(10) OVER (ORDER BY purchase_amount DESC) AS decile
FROM user_amt),
decile_amt AS(
SELECT decile,
SUM(purchase_amount) AS amount,
AVG(purchase_amount) AS avg_amount,
SUM(SUM(purchase_amount)) OVER (ORDER BY decile) AS cum_amount,
SUM(SUM(purchase_amount)) OVER() AS total_amount
FROM user_decile
GROUP BY decile)
SELECT * FROM decile_amt;
구매액이 많은 Decile 순서로 구성비,구성비 누계 계산하기
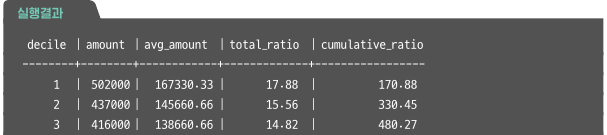

SELECT
decile,
amount,
avg_amount,
100.0 * amount / total_amount AS total_ratio,
100.0 * cum_amount / total_amount AS cum_ration
FROM decile_amt;
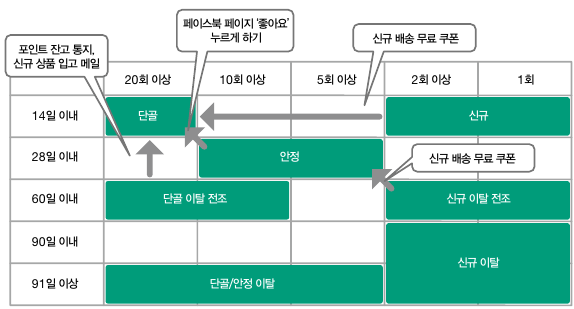
※ DECILE 7~10에 해당하는 정착되지 않은 고객을 대상으로 리텐션을 높이는 등의 대책을 세우거나, 해당 고객을 대상으로 추가 데이터를 수집하여 속성 데이터 수집 및 활용하기
11-7. RFM 분석으로 사용자를 3가지 관점의 그룹으로 나누기
CASE 식, generate_series 함수, RFM 분석
앞서 알아본 Decile분석은 검색 기간에 따라 고객이 잘못 분류되는 단점이 있다. RFM분석에서는 보다 세세하게 사용자를 그룹으로 나눌 수 있다.
RFM 분석의 3가지 지표 집계하기1. Recency: 최근 구매일2. Frequency: 구매 횟수3. Monetary: 구매 금액 합계→ 한 번의 구매로 비싼 물건을 구매한 사용자와 정기적으로 저렴한 물건을 여러 번 구매한 사용자를 다른 그룹으로 구분
사용자 별로 RFM 집계하기
1. Recency - max date - current date
2. Frequency - count
3. Monetary - sum
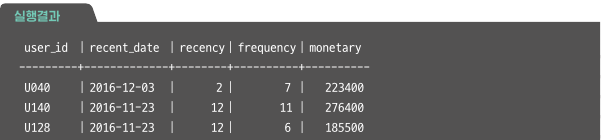
WITH purchase_log AS(
SELECT
user_id,
amount,
mid(stamp, 1, 10) AS dt
FROM action_log),
user_rfm AS(
SELECT
user_id,
MAX(dt) AS recent_date,
DATEDIFF('2016-12-05', MAX(dt)) AS recency,
COUNT(dt) AS frequency,
SUM(amount) AS monetary
FROM purchase_log
GROUP BY user_id)
SELECT * FROM user_rfm;
※ MySQL은 날짜끼리 연산(+,-)이 안됨, DATEDIFF() 사용하기

RFM 랭크 정의하기
: RFM분석에서는 3개의 지표를 5개의 그룹으로 나누는 것이 일반적이다. 총 125개(5X5X5)의 그룹으로 사용자를 나눠 파악할 수 있음
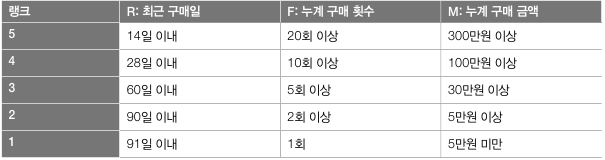
-- 이어서
user_rfm_rank AS(
SELECT
user_id,
recent_date,
recency,
frequency,
monetary,
CASE
WHEN recency < 14 THEN 5
WHEN recency < 28 THEN 4
WHEN recency < 60 THEN 3
WHEN recency < 90 THEN 2
ELSE 1 END AS r,
CASE
WHEN 20 <= frequency THEN 5
WHEN 10 <= frequency THEN 4
WHEN 5 <= frequency THEN 3
WHEN 2 <= frequency THEN 2
ELSE 1 END AS f,
CASE
WHEN 300000 <= monetary THEN 5
WHEN 310000 <= monetary THEN 4
WHEN 30000 <= monetary THEN 3
WHEN 5000 <= monetary THEN 2
ELSE 1 END AS m
FROM user_rfm)
각 그룹의 사람 수 확인하기
-- 이어서
mst_rfm_index AS(
SELECT 1 AS rfm_index
UNION ALL SELECT 2 AS rfm_index
UNION ALL SELECT 3 AS rfm_index
UNION ALL SELECT 4 AS rfm_index
UNION ALL SELECT 5 AS rfm_index),
rfm_flag AS(
SELECT
p.rfm_index,
CASE WHEN p.rfm_index=q.r THEN 1 ELSE 0 END AS r_flag,
CASE WHEN p.rfm_index=q.f THEN 1 ELSE 0 END AS f_flag,
CASE WHEN p.rfm_index=q.m THEN 1 ELSE 0 END AS m_flag
FROM mst_rfm_index AS p
CROSS JOIN user_rfm_rank AS q)
SELECT * FROM rfm_flag;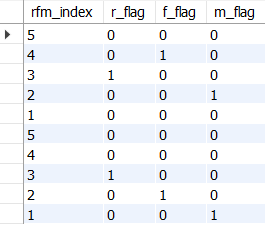
-- 이어서
SELECT
rfm_index,
SUM(r_flag) AS r,
SUM(f_flag) AS f,
SUM(m_flag) AS m
FROM rfm_flag
GROUP BY rfm_index
ORDER BY rfm_index DESC;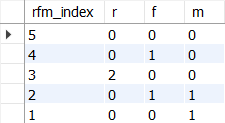
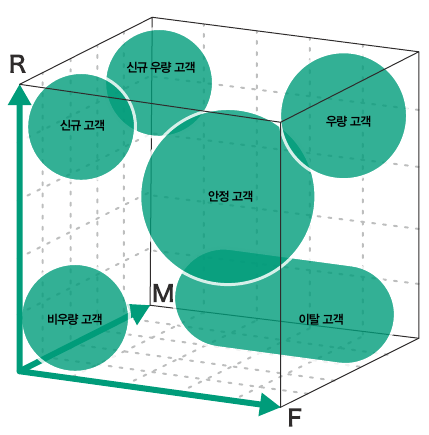
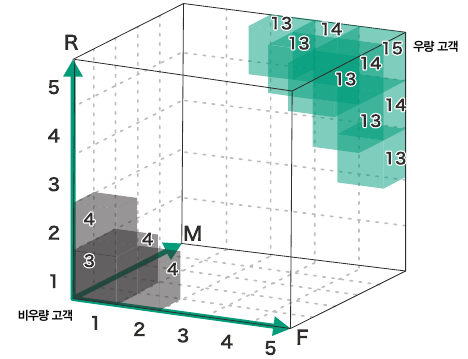
사용자를 1차원으로 구분하기 - R+F+M 값을 통합 랭크로 계산하기
: RFM의 각 랭크 합계를 기반으로 13개의 그룹으로 나누어 관리하기
| 통합 랭크 | R | F | M | 사용자 수 |
| 15 | 5 | 5 | 5 | 9 |
| ... | ... | ... | ... | ... |

--- 이어서
SELECT
r+f+m AS total_rank,
r,
f,
m,
COUNT(user_id) AS count
FROM user_rfm_rank
GROUP BY r,f,m
ORDER BY total_rank DESC, r DESC, f DESC, m DESC;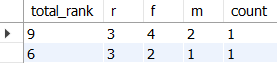
종합 랭크 별로 사용자 수 집계하기

-- 이어서
SELECT
r+f+m AS total_rank,
COUNT(user_id) AS count
FROM user_rfm_rank
GROUP BY total_rank -- OR r+f+m
ORDER BY total_rank DESC;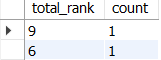
2차원으로 사용자 인식하기 (R과 F를 사용해서 집계하기)
recency의 rank('r')와 frequency의 rank('f') 조합으로 고객 분류하기
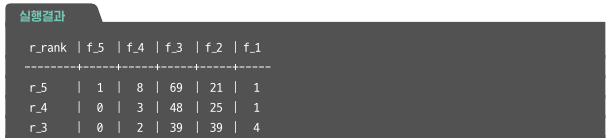

-- 이어서
SELECT
CONCAT('r_', r) AS r_rank,
COUNT(CASE WHEN f=5 THEN 1 END) AS f_5,
COUNT(CASE WHEN f=4 THEN 4 END) AS f_4,
COUNT(CASE WHEN f=3 THEN 3 END) AS f_3,
COUNT(CASE WHEN f=2 THEN 2 END) AS f_2,
COUNT(CASE WHEN f=1 THEN 1 END) AS f_1
FROM user_rfm_rank
GROUP BY r
ORDER BY r_rank DESC;